

重点介绍数据科学领域需要知道的五大关键概念
电子说
描述
本文将重点介绍一些数据科学领域的关键概念,掌握它们对于你今后的职业生涯大有益处。这些概念或许你已经了解,或许你还未掌握。不论你现在是否清楚,笔者的目的是向你专业地解释为何它们至关重要。
多重共线性、独热编码、欠采样和过采样、误差度量以及叙事能力,这是笔者在想到专业数据科学家日常工作时首先想到的关键概念。叙事能力或许算是技能和概念的结合,但笔者在此还是想强调它在数据科学家工作中的重要性。我们开始吧!
多重共线性
多重共线性虽然看起来又长又拗口,拆开来看还是易于理解的。“多重”指数量多,“共线性”则意味着线性相关。多重共线性可以描述为在回归模型中,两个或多个解释变量解释相似信息或高度相关。这一概念之所以引起关注,有以下几个原因。
对于某些建模技术来说,多重共线性可能导致过拟合,最终降低模型性能。冗余数据时有出现,模型中的所有特征或属性并非都是有必要的。因此,可以采用某些方法来找到应该被删除的特征,正是它们导致了多重共线性。
方差膨胀系数(VIF)
相关矩阵
数据科学家们经常使用这两种技术,尤其是相关矩阵和相关图——通常用某种热图进行可视化,而VIF则不太为人所知。VIF值越高,该特征对回归模型的用处就越小。
独热编码
独热编码是模型中的一种特征转换形式,你可以通过编码来数值化地体现类别特征。尽管类别特征本身有文本值,但是独热编码会将这些信息转置,以便每个值都成为特征,行中的观察值记为0或1。例如,假设我们有分类变量gender,独热编码后的数字表示如下(之前表示为gender,之后表示为male/female):

独热编码处理前后对比
如果你不仅要使用数字化的特征,还需要使用文本/类别特征创建数字表示,那么此转换非常有用。
采样
当你拥有的数据不足时,可以使用过采样作为一种补偿。假设在处理一个分类问题时,有一个如下例所示的少数类:
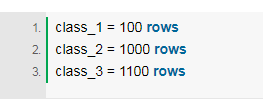
如你所见,class_1的类只有少量数据,这意味着你的数据集是不平衡的,也就是所谓的少数类。
有几种过采样方法。其中一种叫做SMOTE,即合成少数类过采样技术(Synthetic Minority Over-samplingTechnique)。SMOTE的实现方式之一是采用K近邻(K-neighbor)算法来找到最近的点以合成样本。也有类似的技术反其道而行之,进行欠采样。
当类或回归数据中有离群值时,如果你希望确保模型运行在最能体现数据集的采样结果之上,那么这些技术便能派上用场。
误差度量
在数据科学中,有很多用于分类模型和回归模型的误差度量。以下是一些可以专门用于回归模型的方法:
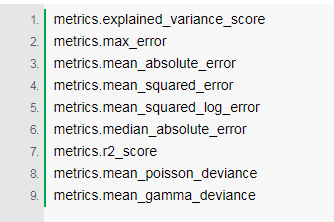
对回归模型来说,上述误差度量中最常用的两种是MSE(均方误差)和RMSE(均方根误差):
MSE:平均绝对误差回归损失(引自sklearn)
RMSE:均方根误差回归损失(引自sklearn)
对于分类模型来说,可以用精度和ROC曲线下的面积(AUC,Area Under the Curve)来评价模型的性能。
叙事能力
叙事概念的重要性怎么强调都不为过。它可以被定义成一种概念或技能,但定义本身并不重要。重要的是,如何在商业环境中展现出自己解决问题的能力。许多数据科学家总是只关注模型的精度,但却无法理解整个商业过程。该过程包括:
业务是什么?
问题是什么?
为何需要数据科学?
数据科学在其中的目标是什么?
何时能得到可用结果?
如何应用我们的结果?
我们的结果有什么影响?
如何分享我们的结果和整个过程?
上述问题与模型本身或提升精度无关,重点是如何使用数据来解决公司的问题。与利益相关者和非技术领域的同事相熟对此是大有助益的,在运行基础模型之前,你需要和产品经理一道评估问题,和数据工程师一起收集数据。在模型过程结束时,你将向关键人员介绍结果,这些人最喜欢看可视化结果,因此掌握呈现和交流的技能也是有益的。
对于数据科学家和机器学习工程师来说,有许多需要掌握的关键概念。本文介绍的5点,你了解了吗?
责编AJX
-
工业物联网实施应考虑的五大关键要素2018-10-12 2403
-
智能穿戴产业的五大关键技术2019-05-09 3080
-
苹果未来五大超级产品概念2010-02-02 1343
-
五大关键词解读2010年半导体照明产业发展热点2011-11-01 1001
-
施耐德电机智能城市五大关键领域解决方案2012-11-29 1529
-
决定人工智能发展的风向标五大关键之问2018-01-11 3742
-
微服务五大关键好处揭秘2018-02-09 11976
-
一文看懂LTE五大关键技术和日常维护2018-05-23 41458
-
细谈智能穿戴的五大关键技术2018-07-11 10727
-
智能工厂的五大关键领域及特征2018-10-16 3193
-
智能工厂五大关键领域及其特征体现2018-10-08 5874
-
ADI在线研讨会:精密数模转换器的五大关键技术规格2019-06-20 3995
-
制造业创新中心政策体系形成,主要聚集在五大关键领域2020-06-16 4706
-
成就更好5G的五大关键.zip2023-01-13 640
-
工业化超声波清洗设备的五大关键特性2025-06-13 890
全部0条评论

快来发表一下你的评论吧 !
