

基于盒形图和回归分析实现数据过滤算法的研究分析
描述
软件度量是对软件开发项目、过程及其产品进行数据定义、收集以及分析的持续性定量化过程,目的在于对此加以理解、预测、评估、控制和改善,从而保证软件开发中的高效率、低成本、高质量。但是,得到正确的度量只是测量程序的一部分。软件质量是与所收集和分析的数据质量密切相关的,数据清洗过程的目的就是要解决“脏数据”的问题。数据清洗是指去除或修补源数据中的不完整、不一致、含噪声的数据。在源数据中,可能由于疏忽、懒惰,甚至为了保密使系统设计人员无法得到某些数据项的数据。根据决策系统中“garbage in garbage out”(如果输入的分析数据是垃圾则输出的分析结果也将是垃圾)原理,必须处理这些噪声数据。去掉噪声平滑数据的技术主要有分箱(binning)、聚类(clustering)、回归(regression)等。本文在回归分析的基础上,加入了盒形图进行数据过滤,从而得出一条线性回归直线,使模式或者关系变得更加明显,从而用这些模式和关系对测量的属性作出判断。
1 盒形图和回归分析简介
1.1 盒形图
该方法可以描述数据集取值范围的情况,展示数据主要聚集的区域,发现离群数据可能的位置,以便于对离群数据进行处理。盒形图显示一个变量的信息,如对相同 CMM等级的不同项目完成每个FP的工作量分析,根据中位数m、上四分位数u、下四分位数l、盒长d、和尾(tail)来分析。
中位数是在数据集中排列居中的项。也就是说,如果中位数取值为m,则数据集中有一半的值大于m,一半的值小于m。将所有数值按大小顺序排列并分成四等份,处于三个分割点位置的得分就是四分位数。最小的四分位数称为下四分位数l,所有数值中,有四分之一小于下四分位数,四分之三大于下四分位数。中点位置的四分位数就是中位数。最大的四分位数称为上四分位数u,所有数值中,有四分之三小于上四分位数,四分之一大于上四分位数。也有叫第25百分位数、第75百分位数的。将上四分位数和下四分位数的距离定义为盒长d,因此,d=u-l。接下来定义分布的尾(tail)。理论上,上尾值点为u+1.5d,下尾值为 u-1.5d,这些值必须进行舍位处理,以接近真实数据,位于上尾和下尾之外的值称为离群值。
1.2 回归分析方法
回归分析方法是研究要素之间具体数量关系的强有力的工具,运用这种方法能够建立反映要素之间具体的数量关系的数学模型,即回归模型。线性回归技术的基础就是散点图。将每个属性对表示为一个数据点(x,y),然后用回归技术计算出能够最好地拟合这些点的直线。目标是将属性y(因变量)根据属性x(自变量)表示为等式:y=a+bx。
线性回归的理论是从每个点垂直向上或向下画一条线段到趋势直线,表示从数据点到趋势直线的垂直距离。在某种意义上,这些线段的长度表示数据和直线的差异,且这种差异应尽可能地小。因此,“最佳拟合”的直线式是指使该距离最小的直线。
在数学上要计算“最佳拟合”直线的斜率b和截距a是很简单的。每个点的差异称为残差,生成线性回归直线的公式是残差的平方和达到最小。可以将每个数据点的残差表示为:
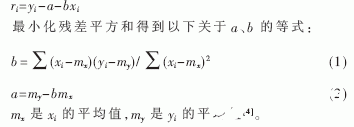
2 算法实现
在进行数据清洗时,由于数据是无序输入的,所以先对其排序,再用盒形图法行数据清洗。以下是伪代码:
void BubbleSort(double m,double q,int n)//先对输入
//的数据进行冒泡排序,并相应修改
//第二组数据的顺序,以保证它们之间的对应关系
{for(int i=0;i<n;i++)
for(int j=n-1;j>i;j--)
{
输入数据的排序
修改第二组数据
}
}
void box(double *m,double *q,int &n) //盒形法筛选
//掉离群项目工作量数据,n为输入数据个数,m、q为指针
{
double a,b,c,top,bottom,l;//上分位a,中位数b,//下分位c
if(n%2==0)//计算出3个四分位数
{
b=(*(m+n/2)+*(m+n/2-1))/2;//数据个数为
//偶数时,中位数取中间两数的平均值
a=*(m+n/4);
c=*(m+3*n/4); }
}
else
{ b=*(m+n/2);
a=*(m+n/4);
c=*(m+3*n/4); }
l=c-a; top=c+1.5*l;bottom=c-1.5*l;//计算出盒
//长,上尾数,下尾数
if(bottom<0) bottom=m;//并进行必要的舍位处理
int j=n;
for(int i=0;i<j;i++)//判断是否为离群值,
{
if(*(m+i)>top‖*(m+i)<bottom)
如有,将其从数组中剔去
}
}
接下来要对筛选出来的数据进行回归分析,从而得到一个数据模型。
void regress(double* m,double* q,int n) //对数组
//m和数据q的数据用线性回归法进行拟合
//并用一条直线表示出它们之间的对应关系
{double average_m,average_q,total_m,total_q,L_mq,L_mm;
double a,b; //拟合直线y=a+bx的2个待定系数
for(int i=0;i<n;i++)。
{
//计算两组数据的和total_m和total_q
}
average_m=total_m/n; //求的第一组数据的平均值
average_q=total_q/n; //求的第二组数据的平均值
for(int j=0;j<n;j++)
{
利用公式(1)计算两组数据m,q它们所有数据偏离程度的对应相乘之和L_mq
}
for(int k=0;k<n;k++)
{
计算第一组数据m,它的所有数据偏离
程度的平方和L_mm
}
b=L_mq/L_mm;//计算出拟合直线的待定系数
//b的拟合值
a=average_q-b*average_m;//利用公式(2)算出参
//数a
}
从而得到一条线性直线,算法结束。
3 算法在实验数据上的实现
从SSMBSS(上海软件度量基准体系)中选取了一组数据(见表1),首先将其用散点图列出来(见图1),然后用盒形图进行数据清洗(见图2),最后用回归分析得出拟合直线(见图3)。
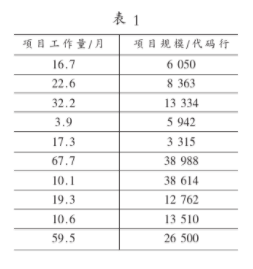
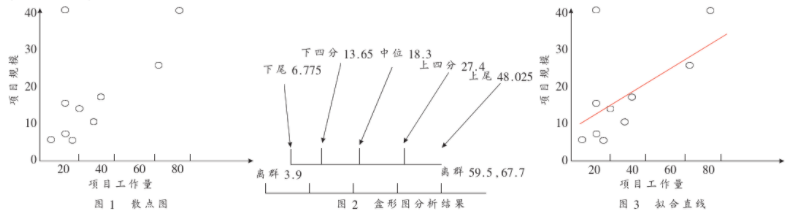
综上所述,对于软件度量过程中出现的数据冗余和失真的情况,可以通过数据过滤和回归分析进行处理,除去那些离群的数据,并得出相应的拟合直线,这样就可以分析出数据的规律,保证软件的质量,提高效率。
责任编辑:gt
-
AES和SM4算法的可重构分析2025-10-23 363
-
《Visual C# 2008程序设计经典案例设计与实现》---饼形图表分析图2017-05-02 4525
-
简单线性回归代码实现细节分析2020-05-22 1807
-
python数据分析基础之使用statasmodels进行线性回归2020-06-19 2516
-
回归算法有哪些,常用回归算法(3种)详解2020-07-28 2759
-
步进电机驱动算法——S形加减速算法原理 精选资料下载2021-07-08 1386
-
数学建模与数学实验-回归分析2008-12-03 818
-
过程间指针分析算法的改进2009-04-02 660
-
信息过滤系统中字符串匹配算法的研究2009-08-15 686
-
AES算法的S盒分析及改进探讨2010-01-09 1488
-
RFID中间件数据的过滤方法的研究和分析2010-01-12 991
-
基于高强度密码S盒安全性分析2017-11-28 1058
-
如何使用IFS分形算法进行树木形态的分析和实现2018-11-29 1230
-
matlab经典算法数字实验教程之回归分析2019-01-03 1080
-
数据分析师必知的7种回归分析方法2019-02-27 4431
全部0条评论

快来发表一下你的评论吧 !
