

一文详解GPU加速器的知识点
描述
2020 年了,什么样的GPU才是人工智能训练的最佳选择?工欲善其事必先利其器,今天我们就来了解一下,GPU加速器的各路神仙吧!
NVIDIA 最新一代 GPU
NVIDIA A100 Tensor Core GPU 可针对 AI、数据分析和高性能计算 (HPC),在各种规模上实现出色的加速。作为 NVIDIA 数据中心平台的引擎,A100 可以高效扩展,系统中可以集成数千个 A100 GPU,也可以利用 NVIDIA 多实例 GPU (MIG) 技术将每个 A100 划分割为七个独立的 GPU 实例,以加速各种规模的工作负载。
深度学习训练NVIDIA A100 的第三代 Tensor Core 借助 Tensor 浮点运算 (TF32) 精度,可提供比上一代高 10 倍之多的性能,并且无需更改代码,更能通过自动混合精度将性能进一步提升两倍。大型 AI 模型只需在 A100 构成的集群上进行训练几十分钟。
深度学习推理通过全系列精度(从 FP32、FP16、INT8 一直到 INT4)加速,实现了强大的多元化用途。MIG 技术支持多个网络同时在单个 A100 GPU 运行,从而优化计算资源的利用率。在 A100 其他推理性能提升的基础上,结构化稀疏支持将性能再提升两倍。
高性能计算A100 引入了双精度 Tensor Cores, 原本在 NVIDIA V100 Tensor Core GPU 上需要 10 小时的双精度模拟作业如今只要 4 小时就能完成。HPC 应用还可以利用 A100 的 Tensor Core,将单精度矩阵乘法运算的吞吐量提高 10 倍之多。
数据分析搭载 A100 的加速服务器可以提供必要的计算能力,并利用第三代 NVLink 和 NVSwitch 1.6TB/s 的显存带宽和可扩展性,妥善应对这些庞大的工作负载。
企业级利用率A100 的 多实例 GPU (MIG) 功能使 GPU 加速的基础架构利用率大幅提升,达到前所未有的水平。
技术参数
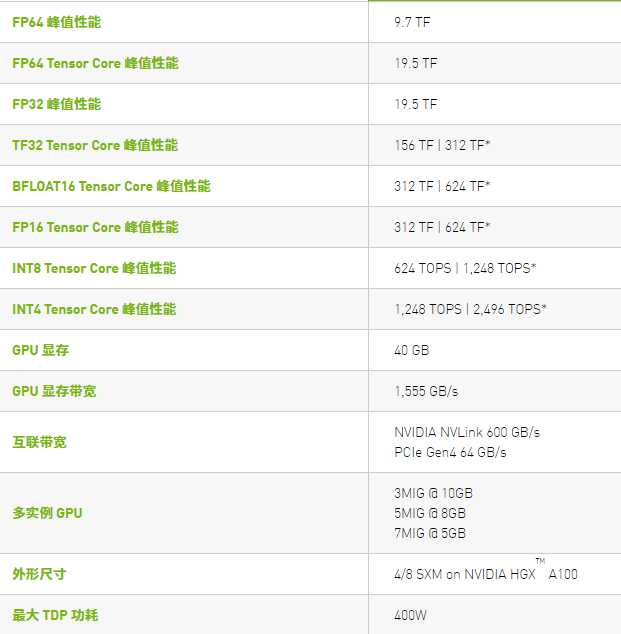
* 采用稀疏技术
构建数据中心必备的 GPU
从语音识别到训练虚拟个人助理和教会自动驾驶汽车自动驾驶,从天气预报到发现药物和发现新能源,数据科学家们正利用人工智能解决日益复杂的挑战,使用大型计算系统来模拟和预测我们的世界。 NVIDIA V100 Tensor Core 是有史以来极其先进的数据中心 GPU,能加快 AI、高性能计算 (HPC) 和图形技术的发展。其采用 NVIDIA Volta 架构,并带有 16 GB 和 32GB 两种配置,在单个 GPU 中即可提供高达 100 个 CPU 的性能。
人工智能训练Tesla V100 拥有 640 个 Tensor 内核,是世界上第一个突破 100 万亿次 (TFLOPS) 深度学习性能障碍的 GPU。新一代 NVIDIA NVLink 以高达 300 GB/s 的速度连接多个 V100 GPU。
人工智能推理NVIDIA V100 GPU 可提供比 CPU 服务器高 30 倍的推理性能。
高性能计算 (HPC)通过在一个统一架构内搭配使用 NVIDIA CUDA 内核和 Tensor 内核,配备 NVIDIA V100 GPU 的单台服务器可以取代数百台仅配备通用 CPU 的服务器来处理传统的高性能计算和人工智能工作负载。
技术参数

推理加速的神器
NVIDIA Tesla T4 Tensor Core GPU是世界上极其先进的推理加速器。搭载 NVIDIA Turing Tensor 核心的 T4 提供革命性的多精度推理性能,以加速现代人工智能的各种应用。T4 封装在节能的小型 70 瓦 PCIe 中,可针对横向扩展服务器进行优化,并且旨在实时提供极其先进的推理。
极具突破性的推理性能NVIDIA T4 引入革命性的 Turing Tensor 核心技术,具备人工智能推理的多精度计算性能。从 FP32 到 FP16 再到 INT8,以及 INT4 精度,T4 的性能比 CPU 高出 40 倍。
先进的实时推理NVIDIA T4 可提供优于 40 倍的低延时高吞吐量,进而可以实时满足更多的请求。
视频转码性能NVIDIA T4 专用的硬件转码引擎将解码性能提升至上一代 GPU 的两倍。T4 可以解码多达 38 个全高清视频流。
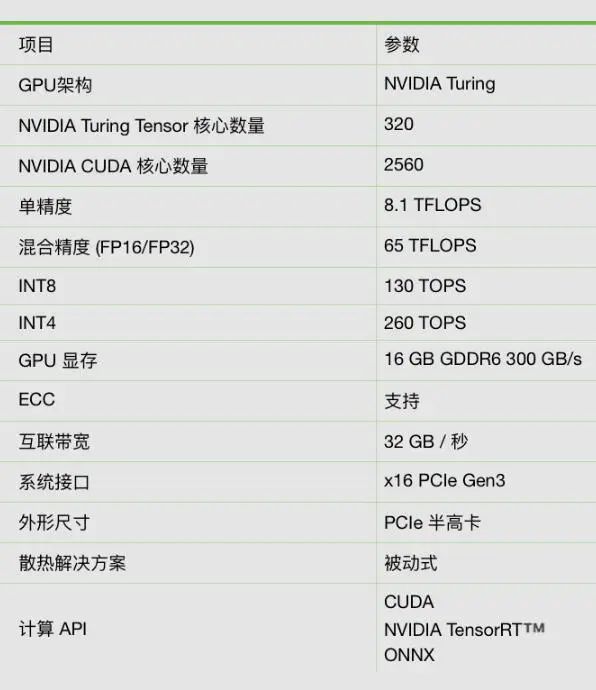
技术参数
适用于桌面的个人工作站
一台DGX工作站就可以提供相当于 400 个 CPU 的计算能力,以低功耗、水冷静音而著称。 过去,硬件及软件的购置、集成和测试可能就要花一个月或更长时间。此外, 优化框架、库及驱动程序还需掌握更多专业知识, 付出更多努力。这些用在系统集成和软件 工程上的宝贵时间和金钱,现在可以用于训练和实验。
专为您办公室设计的超级计算机为办公室及安静场所设计,噪音仅为其他工作站的十分之一 。
更快开始使用深度学习只需插入和接通电源,这种部署简单直观。这个集成软硬件的解决方案可让您将更多时间专注探索发现而不是组装组件上。
从桌面到数据中心,显著提升工作效率DGX工作站可以节省价值几十万元的工程时间,避免因等待开源框架的稳定版本而导致工作效率降低。
相较目前最快的 GPU 工作站提速2倍基于 4 个 NVIDIA V100 加速器构建的工作站, 同时采用了下一代 NVLink 以及全新 Tensor 核心架构等创新技术 。DGX 工作站相较现今最快的 GPU 工作站,深度学习训练性能提升了 2 倍 ,具备 480 TFLOPS 的水冷性能和 FP16 精度。
技术参数

开箱即可用的解决方案
NVIDIA DGX-1 通过开箱即用的解决方案。借助 DGX-1,再加上集成式 NVIDIA 深度学习软件堆栈,您只需开启电源,即可开始工作。
轻松取得工作成果借助 NVIDIA DGX-1提高研究效率,简化工作流程并与团队开展协作。
革命性的 AI 性能DGX-1 凭借 NVIDIA GPU Cloud 深度学习软件堆栈和当今流行的技术框架,将训练速度提升高达三倍。
投资保护NVIDIA 的企业级支持让您无需耗费时间对硬件和开源软件进行问题排查,节省调试和优化时间。
技术参数

AI 企业的必要基础设施
NVIDIA DGX-2 是世界上第一个 2-petaFLOPS 系统,配备 16 块极为先进的 GPU,可以在单个节点训练 4 倍 规模的模型。与传统的 x86 架构相比,DGX-2 训练 ResNet-50 的性能相当于 300 台配备双路英特尔至强 Gold CPU 服务器的性能。
非同一般的计算能力造就出众的训练性能可在单一节点上训练规模扩大 4 倍的模型,而且其性能达到 8 GPU 系统的 10 倍。
革命性的人工智能网络架构NVIDIA 首款 2 petaFLOPS GPU 加速器采用的正是这种创新技术,其 GPU 间带宽高达 2.4 TB/s,性能比前代系统提升了 24 倍,并且问题解决速度提高了 5 倍。
将人工智能规模提升至全新水平的最快途径凭借用于构建大型深度学习计算集群的灵活网络选项,再结合可在共享基础设施环境中改进用户和工作负载隔离的安全多租户功能。
始终运行的企业级人工智能基础设施DGX-2 专为 RAS 而打造,可以减少计划外停机时间,简化可维护性,并保持运行连续性。
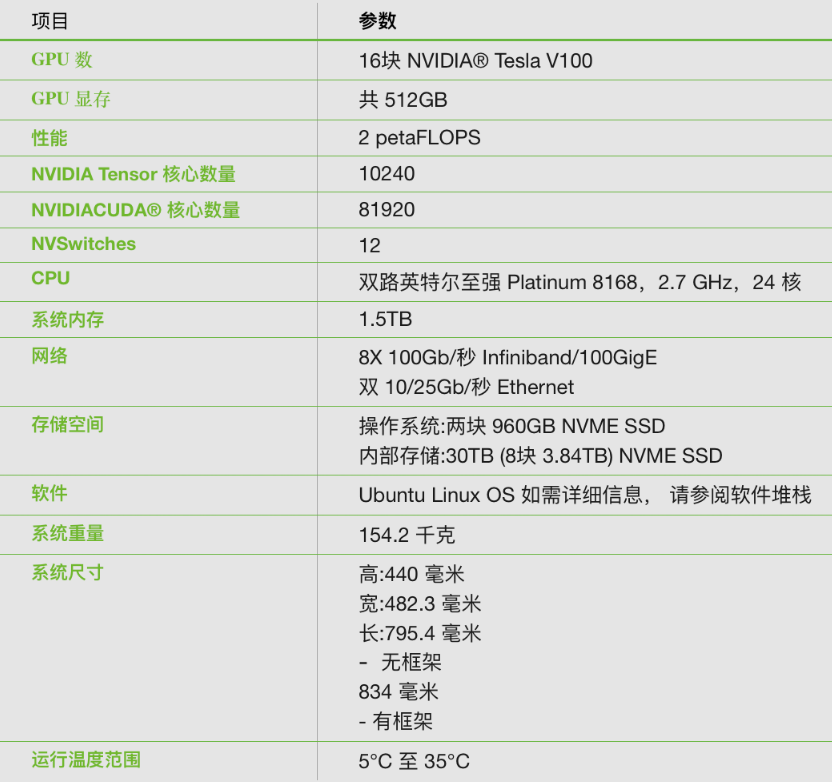
技术参数
目前全球最先进的 GPU 系统
NVIDIA DGX A100 为全球首款 5 petaFLOPS AI 系统提供超高的计算密度、性能和灵活性。采用全球超强大的加速器 NVIDIA A100 Tensor Core GPU,可让企业将深度学习训练、推理和分析整合至一个易于部署的统一 AI 基础架构中,该基础架构具备直接联系 NVIDIA AI 专家的功能。
各种 AI 工作负载的通用系统 NVIDIA DGX A100 是适用于所有 AI 基础架构(包括分析、训练、推理基础架构)的通用系统。
DGXperts:集中获取 AI 专业知识 NVIDIA DGXperts 是一个拥有 14000 多位 AI 专业人士的全球团队,能够帮助您更大限度地提升 DGX 投资价值。
更快的加速体验 集成八块 A100 GPU,可针对 NVIDIA CUDA-X 软件和整套端到端 NVIDIA 数据中心解决方案进行全面优化。
卓越的数据中心可扩展性 NVIDIA DGX A100 内置 Mellanox ConnectX-6 VPI HDR InfiniBand 和以太网适配器,其双向带宽峰值为 450Gb/s。
技术参数

众所周知,如果将英伟达GPU比喻成通往人工智能路上的交通工具的话,选对了方式你坐的可能就是火箭,只需要花费一小时即可完成几百个T的数据研究,选错了,那可能就是“11”路公交车。
责任编辑人:CC
-
Linux文件系统知识点详解2023-11-02 1611
-
C语言链表知识点(2)2023-08-22 712
-
STM32 RTOS知识点2023-08-01 847
-
滚珠螺杆的基本知识点2023-07-07 2686
-
数字电路知识点总结2023-05-30 7361
-
详解射频微波基础知识点2023-01-29 3669
-
电力基础知识点合集2022-03-14 1390
-
Synopsy的Host和DPHY的知识点详解,错过后悔2022-03-08 1508
-
嵌入式知识点总结2021-07-30 2045
-
PWM知识点详解2017-03-16 1962
-
关于红外通信的一些问题知识点2016-05-05 1090
-
高一数学知识点总结2016-02-23 1560
-
计算机组成原理考研知识点归纳2010-04-13 2052
-
硅控制开关(SCS)必需知识点详解2009-07-25 1989
全部0条评论

快来发表一下你的评论吧 !
