

Mobileye公布最新自动驾驶方案
描述
2020年9月24日,吉利汽车与Mobileye正式签约,将使用EyeQ5做自动驾驶,同时,Mobileye也公布了最新的自动驾驶方案。
11个摄像头中,4个鱼眼短距离的泊车用摄像头,7个远距离自动驾驶用摄像头,包括前向6个,后向1个。与EyeQ4最大不同之处在于三目摄像头被双目取代了,三目摄像头实际是单目摄像头在不同FOV上的扩展,特斯拉和国内新兴造车的辅助驾驶或自动驾驶方案都是采用三目。而Mobileye这次没有用三目,挡风玻璃后视镜位置是两个单目摄像头,FOV分别是28度和120度。
考虑到两个摄像头之间的距离,显然不是奔驰那样传统的Stereo Camera立体双目摄像头,并且根据这两个摄像头的FOV看,也不是主摄像头。倒车镜上则有一个FOV为100度的摄像头,A柱下方还有一个侧向的FOV为100度的摄像头。 实际上Mobileye的前部六个摄像头(可能后部的摄像头也参与了)构成了SfM(Structurefrom Motion)。Stereo Vision(立体视觉)SfM比较稀疏,再进一步稠密化就是Multi ViewStereo,即MVS。虽然这七个摄像头都是单目,但他们是合在一起工作的,应该叫多目立体视觉。 Mobileye有关SfM的专利主要有三个,一个是2014年的DenseStructure from motion,另一个是2017年的StereoAuto-Calibration From Structure-from-motion,还有一个是2020年的COMFORTRESPONSIBILITY SENSITIVITY SAFETY MODEL(长达197页),其中虽未提及SfM具体算法,但描述了SfM Stereo Image的处理流程。

Mobileye的Stereo Image处理流程
自动驾驶领域,感知部分的任务就是建立一个准确的3D环境模型。深度学习加单目三目是无法完成这个任务的。单目和三目摄像头的致命缺陷就是目标识别(分类)和探测(Detection)是一体的,无法分割的。
必须先识别才能探测得知目标的信息,而深度学习肯定会出现漏检,也就是说3D模型有缺失,因为深度学习的认知范围来自其数据集,而数据集是有限的,不可能穷举所有类型,因此深度学习容易出现漏检而忽略前方障碍物,如果无法识别目标,单目就无法获得距离信息,系统就会认为前方障碍物不存在危险,不做任何减速,特斯拉多次事故大多都是这个原因。 传统算法,则可能无法识别前方障碍物,但依然能够获知前方障碍物的信息,能够最大限度地保证安全。当然这需要传感器配合,激光雷达和双目立体视觉都是以传统算法为核心(因为它不需要识别目标,自然就不需要深度学习,当然你也可以用深度学习处理激光雷达数据,但不是为了识别目标)。
其次,深度学习是一个典型的黑盒子系统,汽车上任何事物都必须具备可解释性和确定性,深度学习并不具备。传统车厂尽量避免在直接有关汽车安全领域使用深度学习,当然,深度学习是识别目标准确度最高的方法,不得不用。大部分车厂会坚持使用可解释的具备确定性的传统图像算法,直到深度学习变成白盒子。
上图为Waymo深度学习科学家drago anguelov 2019年2月在MIT在讲述无人车感知系统时,坦承机器学习的不足,单目系统漏检无法避免,特别是在交通复杂的中国。深度学习的漏检和算力没有任何关系,再强大的算力也无法避免漏检,也就无法避免事故。 若要解决漏检这个问题,或者说构建一个没有缺失的3D环境模型就必须用将识别与探测分离,无需识别也可以探测目标的信息,忘掉深度学习,传统的做法是激光雷达和双目立体视觉。但激光雷达商业化,车载化一直进展缓慢,双目的缺陷是立体匹配算法门槛太高,在线标定非常困难,只有奔驰、斯巴鲁、路虎和雷克萨斯运用的比较好。宝马虽然高端车型使用双目,但实测结果并不理想,宝马如今也部分放弃了双目路线,电动SUV领域还未放弃双目。
除了激光雷达和双目立体视觉外还有一种方法,这就是今天要说的主角:SfM。在双目立体视觉中,两个相机之间的相对位姿是通过标定靶精确标定出来的,在重建时直接使用三角法进行计算;而在SfM中该相对位姿是需要在重建之前先计算的。双目必须两个镜头输入两张照片双目重建方法,SfM和MVS属于单目重建多目立体视觉,输入的是一系列同一物体和场景的多视图。SfM得到的通常是稀疏点云,而经过MVS处理极线约束后可建立稠密点云,可以媲美激光雷达点云,也就是Mobileye所说的Vidar。
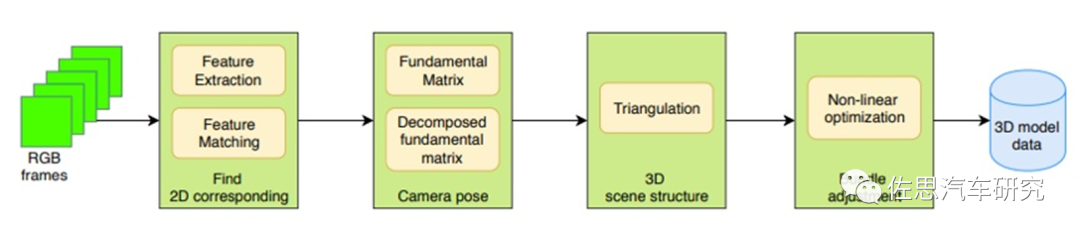
SfM的框架图
Structure fromMotion(SfM)是一个估计相机参数及三维点位置的问题。一个基本的SfM pipeline可以描述为:对每张2维图片检测特征点(feature point),对每对图片中的特征点进行匹配,只保留满足几何约束的匹配,最后执行一个迭代式的、鲁棒的SfM方法来恢复摄像机的内参(intrinsic parameter)和外参(extrinsic parameter)。并由三角化得到三维点坐标,然后使用Bundle Adjustment进行优化。常见的SfM方法可以分为增量式(incremental/sequentialSfM),全局式(global SfM),混合式(hybrid SfM),层次式(hierarchica SfM)。这些都是传统OpenCV算法,跟深度学习无关,而如今,简单易学深度学习横扫一切,复杂难学的传统算法人才非常稀缺,导致SfM几乎没有商业化的例子。
SfM最初是假定相机围绕静态场景运动,实际就是相机获取在目标不同位置的图像,因此可以用放置多个相机取代运动的单一相机。为了避免干扰,28度FOV与两个100度FOV的摄像头构成SfM系统。SfM通常针对静止目标(古建筑物居多),移动目标难度极大,干扰因素比较多,大部分人都望而却步。 在MVS重建精准3D尺寸模型领域有个难点,即尺度因子不确定性,这个可以用其他传感器如高精度IMU获取真实尺寸校准,但高精度IMU太贵了,还有一种方法就是DNN。也可以看作用先验尺寸数据推算实际尺寸。当然也有传统的非深度学习方法。
上图即Mobileye的VIDAR,基于比较简单的神经网络DNN,对算力要求远低于图像识别分类的CNN。基于深度学习的3D点云和mesh重构是较难以计算的,因为深度学习一个物体完整的架构需要大量数据的支持。传统的3D模型是由vertices和mesh组成的,因此不一样的数据尺寸data size造成了训练的困难。所以后续大家都用voxelization(Voxel)的方法把所有CAD model转成binary voxel模式(有值为1,空缺为0)这样保证了每个模型都是相同的大小。利用一个标准的CNN结构对原始input image进行编码,然后用Deconv进行解码,最后用3D LSTM的每个单元重构output voxel。3D voxel是三维的,它的精度成指数增长,所以它的计算相对复杂。
这个多目立体视觉制造出来的VIDAR与真实的Lidar当然有一定差距,与传统的双目立体视觉相比精度也有一定差距,毕竟双目立体视觉发展了20年,不过多目比双目覆盖面更广。
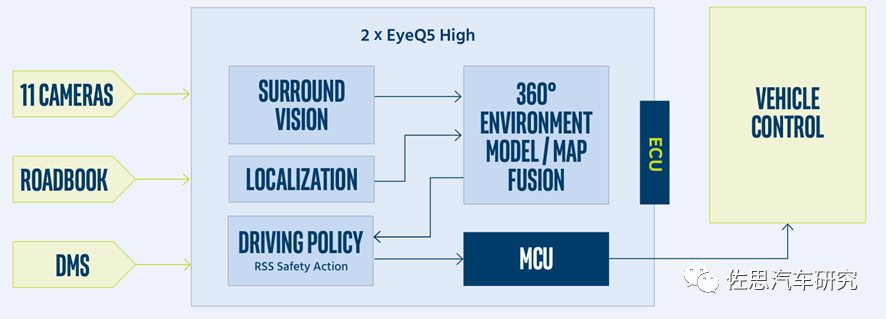
Mobileye SuperVision的系统框架图
在2020年Mobileye的专利里也提到了双处理器设置,第一个视觉处理器检测道路标识、交通标识,并根绝ROADBOOK做定位,第二个视觉处理器则处理SfM,并发送到第一个视觉处理器,构建起一个带有完整道路结构的3D环境模型。 和英伟达、特斯拉以及一堆视觉加速器厂家比,Mobileye并不擅长硬件高算力,EyeQ5的算力只有24TOPS,低于英伟达Xavier的32TOPS,2022年即将量产的Orin高达200TOPS。
Mobileye擅长的是算法,SfM和MVS将筑起一道算法护城河,并借此提高安全。EyeQ5预计在2021年3月量产,尽管其算力与许多国内初创厂家相比都低,但高算力不代表安全,EyeQ5依然获得吉利、宝马等4个大整车厂的订单。 加入佐思数据平台会员,可获得Mobileye立体视觉专利完整版。
原文标题:忘掉单目和三目吧,Mobileye转向立体视觉
文章出处:【微信公众号:佐思汽车研究】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
细说关于自动驾驶那些事儿2017-05-15 7237
-
自动驾驶的到来2017-06-08 7479
-
AI/自动驾驶领域的巅峰会议—国际AI自动驾驶高峰论坛2017-09-13 7588
-
自动驾驶OS市场的现状及未来 精选资料推荐2021-07-27 2544
-
英特尔联合德尔福/Mobileye成立自动驾驶事业部 共同打造平台产品2016-12-01 1997
-
Mobileye与Intel将为自动驾驶带来什么?2016-12-06 1035
-
Mobileye联手四维图新 打造中国自动驾驶解决方案2018-01-10 6942
-
对于Mobileye在自动驾驶中的作用分析2019-09-04 3231
-
自动驾驶传感器初创公司Luminar与自动驾驶芯片公司Mobileye合作2020-11-24 2542
-
Mobileye在自动驾驶方面的战略和将用于自动驾驶汽车的技术2021-01-15 3634
-
为了实现消费级别的自动驾驶,Mobileye做了哪些?2021-01-29 3549
-
Mobileye的自动驾驶系统Mobileye Drive已经实现商用2021-04-25 3178
-
大众汽车和Mobileye加强自动驾驶合作2024-03-22 1747
-
Mobileye端到端自动驾驶解决方案的深度解析2024-10-17 1750
-
Elektrobit与Mobileye合作打造自动驾驶解决方案2026-02-28 1907
全部0条评论

快来发表一下你的评论吧 !
