

STM32的backtrace深度讲解(cortex-m的栈布局与栈回溯的原理和方案)
控制/MCU
描述
STM32上的backtrace原理与分析
-
1.说明
-
2.cortex-m上的栈布局
-
2.1 cortex-m上的寄存器
-
2.2 cortex-m上的自动压栈
-
2.3 cortex-m上的函数执行流程
-
-
3.cmbacktrace原理分析
-
3.1 问题分析
-
-
4.实际应用
-
5.总结
1.说明
对于一个嵌入式产品的开发流程来说,一般都需要经过如下几个阶段:
1.方案预研
2.产品功能设计
3.开发调试
4.工厂测试
5.产品上线售后
一般来说,1,2,3板子都是在开发者手上,一旦遇到bug,只要可以复现,基本上都可以排查出来,然后修复或者规避。但一旦进入到4,5阶段,产品已经成型之后,再想排查BUG就比较麻烦了。例如工厂测试阶段,有可能连续运行好几天或者好几个星期才能复现的问题,排查起来就十分的复杂。对于这种情况,backtrace是十分必要的。可以在离线的状态下分析系统的关键信息,通过函数的栈回溯,从而找到出错的对应的执行函数,然后结合程序设计,基本上大部分的bug基本上也可以找到。我之前写过一篇文章arm上backtrace的分析与实现原理。分析了在cortex-a上的分析情况。但是对于cortex-m来说,问题就会复杂许多,因为cortex-m对于固件的体积的限制以及特殊的架构,让backtrack的方案占用了过大的flash。这是设计者所不能接受的,而且更加难受的是cortex-m并没有栈回溯指针。这就让栈的深度的计算变的十分复杂。本文主要分析cortex-m的栈布局以及一些栈回溯的底层原理和方案。
2.cortex-m上的栈布局
在cortex-m上弄清楚栈的布局,就必须理解cortex-m上的压栈入栈的机制和原理。下面从该体系架构上说说cortex-m上比较重要的细节。
2.1 cortex-m上的寄存器
一旦涉及到C语言函数,必须要考虑到的问题就是函数的入栈出栈的问题,也就是SP指针的增加或者减少。下面还是来复习一下arm cortex-m上的寄存器。
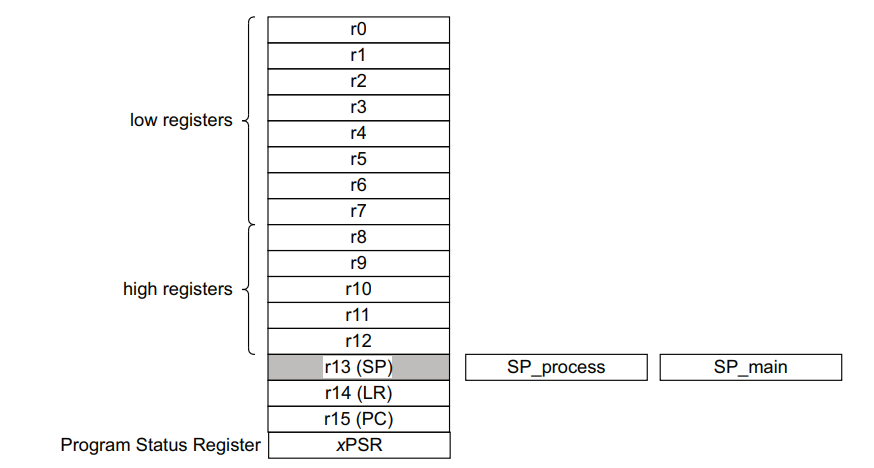
按照arm cortex-m的设计,一共有32个寄存器。
-
13个通用寄存器,r0-r12 -
2个不同模式下使用的SP, PSP(SP_process) 和MSP(SP_main) -
1个链接寄存器LR(r14) -
1个程序计数器(PC) -
1个程序状态寄存器(xPSR)
在不同的模式下,R0-R12、SP、LR是各有一份的,所以这样算下来,总共是32个寄存器,但是在不同的模式下,并不能完全看到这32个寄存器的状态,只能看到其中的一部分。
通用寄存器R0-R12
上图将通用寄存器分为low register和high registers就是根据指令集来说的,对于thumb指令,是16位的,只能访问到low register,也就是R0-R7,而对于32位的arm指令,是所有的指令都可以访问到。所以有这样的划分。
栈指针SP
一旦涉及到参数的压栈与入栈,或者函数的执行返回的时候,必须会涉及到栈指针的变化。在cortex-m由于涉及到两种不同的sp的切换,所以在使用SP的时候要格外的小心。
程序链接寄存器LR
程序的链接寄存器在函数返回的时候会被使用到,比如一个函数A中执行的另外一个函数B,如下
void fun_A()
{
fun_B()
}
那么当执行到fun_B的时候,首先编译器编译的汇编代码会将func_A的地址自动存放LR压栈,然后压入其他的参数。待func_B执行完成之后,会弹出LR到PC,此时就会返回到fun_A函数去执行了。
程序计数寄存器
该寄存器会自动指向当前指向的程序地址。
2.2 cortex-m上的自动压栈
不同于其他的处理器架构,cortex-m的定位一开始就是为实时性、小体积容量的设计考虑的,所以在中断处理这一块,也做了一个十分有意思的设计--自动压栈处理。
一般的CPU进入中断后都会去进行压栈操作,因为栈就是函数的现场,保护了栈内容,中断退出的时候只需要恢复栈数据就可以恢复到程序执行的状态了。以往这个阶段都是通过人工操作写程序完成的,在cortex-m上,将部分栈由硬件自动压入。其压入栈的顺序一般如下:
xPSR->PC(返回地址)->LR->R12->R3->R2->R1->R0
这些寄存器硬件自动压入,效率上应该有较大的提升。另外的一些寄存器可以手动处理。
2.3 cortex-m上的函数执行流程
在分析函数的执行的时候,主要是想弄清楚底层的硬件寄存器做了哪些操作,这就需要进行汇编翻译进行。此处我们用arm gcc编译出cortex-m的elf固件,通过objdump随便看一个函数体的执行。
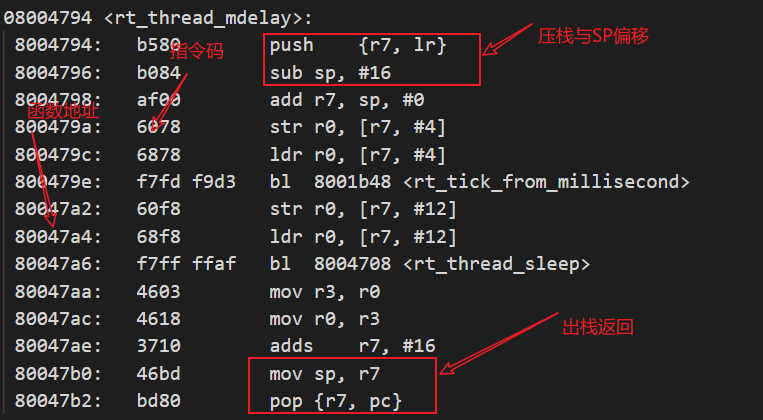
对于一个arm函数的汇编代码,基本上都是上面的执行逻辑。根据指令机器码,得到对应的指令。
我们知道,在函数执行的时候,保存在内存上的都是机器码,只有在通过objdump工具的时候,才会将这些机器码变成程序。也就是说,在程序执行时,如果此时查看0x8004794这个地址,看到的数据是80b5 84b0这样的内容。那么这些又该如何进行翻译呢?该函数的sp指针到底该如何计算。
PUSH指令分析
PUSH指令所对应的机器码如下:
1011 010R rrrr rrrr -- PUSH reg_list
按照解析,R表示的是LR寄存器,后面的是R0-R7寄存器的列表。所以解释起来机器码b580翻译成二进制b1011 0101 1000 0000。对应的实际含义就是压入LR与R7寄存器,当执行PUSH后,SP指针会自动减去两个寄存器的大小,也就是8个字节。
SUB指令分析
SUB指令对应的机器码如下:
1011 0000 1vvv vvvv -- SUB Sp,#immed_7*4
根据含义,v表示分别乘以4。也就是最低位为4,第二位是8,第三位是16,第四位为32,以此类推,得到其偏移的立即数。目前的机器码为b084 翻译成二进制为b1011 0000 1000 0100,所以表示的立即数为16.
两者结合,得到当前函数会使得sp指针的值减少16+8=24。
3.cmbacktrace原理分析
在做cortex-m上的backtrace的时候,查阅了一些资料,其中发现一个CmBacktrace。
https://github.com/armink/CmBacktrace
设计的目的:针对 ARM Cortex-M 系列 MCU 的错误代码自动追踪、定位,错误原因自动分析的开源库。
其实现的机理是利用cortex-m的压栈特性所决定的。当指定好栈地址后,sp指针就会在自己的栈空间内进行偏移。函数入栈的时候,会压入参数,也会压入lr寄存器,利用lr寄存器的值就可以找到是谁调用该函数的。
对于裸机情况,栈地址指向一个
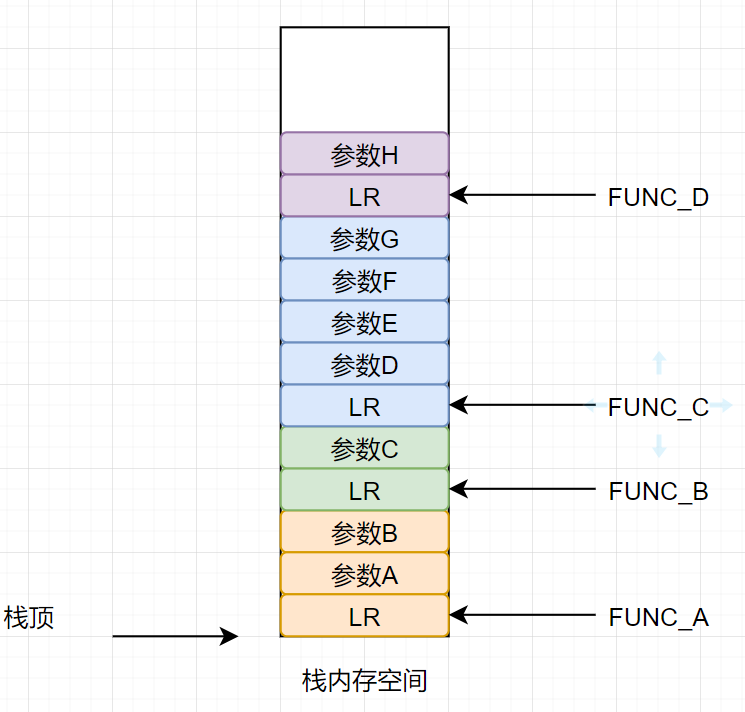
当程序出现异常的时候,只需知道当前的栈顶以及当前的sp的偏移量,这些在程序中是很好得到的。然后开始便利栈中的数据,每四个字节遍历一次得到地址,该地址不一定是函数地址,有可能是参数的地址,人工去审阅这些地址的时候,只要细心一点是可以找到线索的。在CmBacktrace上通过判断地址的前面2个字节的thumb指令的机器码是否为BL或者bLx来进行判断该地址是否为函数。这样也是可以的。
如果在cortex-m上使用了操作系统,原理上基本上是类似的,由于每个线程都会有自己的线程栈,所以会有多个线程栈的情况。要想得到当前运行的线程栈的backtrack,原理上是和裸机一样。但是如果想要分析其他的线程的栈的backtrace,则需要注意操作系统的压栈问题。
例如在rt-thread中,进行线程切换的时候,会调用pendsv进行自动压栈一次,然后在手动压栈其他的寄存器。如果要做解析,首先去掉前面操作系统压栈的部分。rt-thread操作系统前面压栈的数据
# xPSR->PC->LR->R12->R3->R2->R1->R0
# R11 R10 R9 R8 R7 R6 R5 R4 FLAG
一共压了16个寄存器,如果不做处理,解析到的PC为rt_hw_interrupt_enable,解析到的LR为rt_schedule。
3.1 问题分析
在对栈的解析过程中,我们往往会涉及到一些脏数据来破坏我们的分析。比如,参数中传递东西是函数的地址,这是读到的可能会误以为这是LR,这样分析起来会有一定的风险,虽然说在大多数情况下CmBacktrace的解析可以做的很好,但是遇到参数是函数地址的时候,就很难去做分析了,此时可能会借助人工来做分析。需要一定的工作量。那么有没有比较想的办法,不需要便利,直接跳转到下一个LR去执行呢?
根据在《2.3 cortex-m上的函数执行流程》的分析,我们基本上可以算出来一个函数的栈数据偏移,这样就可以顺利的解决这个问题了。每次都会跳转到固定的函数中,结合当前的数据栈的内容,从而得到想要的结果。
4.实际应用
上述的分析是有实际应用的价值的,在每次出错的情况下,我们可以保存栈的数据到掉电非易失性存储介质的某个特定的地址处,因为栈的大小并不会很大,一般512字节或者1k或者2k等等数据量,问题出现后,取出栈里面的内容,然后通过外部工具例如python脚本进行分析,与对应的elf文件结合起来,就能很准确的定位函数的backtrace了。然后对于问题的查询也会变得有迹可循,大大减少后期调试工作的复杂性。
5.总结
未雨绸缪是设计中必须考虑的问题,做出的产品都不能保证一点问题都不会出现,当出现问题的时候,也不用怕,因为有了分析的手段和数据。这样也能够减少产品设计的风险,做出更好用的嵌入式产品。
原文标题:STM32上的backtrace原理与分析
文章出处:【微信公众号:嵌入式IoT】欢迎添加关注!文章转载请注明出处。
-
Cortex-M产品的特色2025-11-26 266
-
RVBacktrace RISC-V极简栈回溯组件2024-09-15 1764
-
求助,关于cortex-M3的压栈问题求解2024-04-28 648
-
Cortex-M位带操作的原理2023-10-24 2038
-
Arm64栈回溯 结构介绍2023-07-28 2000
-
嵌入式C代码调试利器backtrace介绍2023-03-08 3736
-
STM32编程:动画深度演示栈机制、栈溢出2021-12-16 886
-
米尔科技Cortex-M Prototyping System +介绍2019-11-14 3000
-
一文详解Linux内核的栈回溯与妙用2018-10-05 6661
-
关于Cortex-M 调试应用的介绍2018-07-10 3247
-
关于STM32与Cortex-M内核系列的介绍(2)2018-07-05 5771
全部0条评论

快来发表一下你的评论吧 !
