

Google研究科学家:告别卷积
描述
编译 | 凯隐 出品 | AI科技大本营(ID:rgznai100)
Transformer是由谷歌于2017年提出的具有里程碑意义的模型,同时也是语言AI革命的关键技术。在此之前的SOTA模型都是以循环神经网络为基础(RNN, LSTM等)。从本质上来讲,RNN是以串行的方式来处理数据,对应到NLP任务上,即按照句中词语的先后顺序,每一个时间步处理一个词语。
相较于这种串行模式,Transformer的巨大创新便在于并行化的语言处理:文本中的所有词语都可以在同一时间进行分析,而不是按照序列先后顺序。为了支持这种并行化的处理方式,Transformer依赖于注意力机制。注意力机制可以让模型考虑任意两个词语之间的相互关系,且不受它们在文本序列中位置的影响。通过分析词语之间的两两相互关系,来决定应该对哪些词或短语赋予更多的注意力。
相较于RNN必须按时间顺序进行计算,Transformer并行处理机制的显著好处便在于更高的计算效率,可以通过并行计算来大大加快训练速度,从而能在更大的数据集上进行训练。例如GPT-3(Transformer的第三代)的训练数据集大约包含5000亿个词语,并且模型参数量达到1750亿,远远超越了现有的任何基于RNN的模型。
现有的各种基于Transformer的模型基本只是与NLP任务有关,这得益于GPT-3等衍生模型的成功。然而,最近ICLR 2021的一篇投稿文章开创性地将Transformer模型跨领域地引用到了计算机视觉任务中,并取得了不错地成果。这也被许多AI学者认为是开创了CV领域的新时代,甚至可能完全取代传统的卷积操作。 其中,Google的Deepmind 研究科学家Oriol Vinyals的看法很直接:告别卷积。 以下为该论文的详细工作:
基本内容 Transformer的核心原理是注意力机制,注意力机制在具体实现时主要以矩阵乘法计算为基础,这意味着可以通过并行化来加快计算速度,相较于只能按时间顺序进行串行计算的RNN模型而言,大大提高了训练速度,从而能够在更大的数据集上进行训练。 此外,Transformer模型还具有良好的可扩展性和伸缩性,在面对具体的任务时,常用的做法是先在大型数据集上进行训练,然后在指定任务数据集上进行微调。并且随着模型大小和数据集的增长,模型本身的性能也会跟着提升,目前为止还没有一个明显的性能天花板。
Transformer的这两个特性不仅让其在NLP领域大获成功,也提供了将其迁移到其他任务上的潜力。此前已经有文章尝试将注意力机制应用到图像识别任务上,但他们要么是没有脱离CNN的框架,要么是对注意力机制进行了修改,导致计算效率低,不能很好地实现并行计算加速。因此在大规模图片分类任务中,以ResNet为基本结构的模型依然是主流。
这篇文章首先尝试在几乎不做改动的情况下将Transformer模型应用到图像分类任务中,在 ImageNet 得到的结果相较于 ResNet 较差,这是因为Transformer模型缺乏归纳偏置能力,例如并不具备CNN那样的平移不变性和局部性,因此在数据不足时不能很好的泛化到该任务上。 然而,当训练数据量得到提升时,归纳偏置的问题便能得到缓解,即如果在足够大的数据集上进行与训练,便能很好地迁移到小规模数据集上。 在此基础上,作者提出了Vision Transformer模型。下面将介绍模型原理。
模型原理 该研究提出了一种称为Vision Transformer(ViT)的模型,在设计上是尽可能遵循原版Transformer结构,这也是为了尽可能保持原版的性能。 虽然可以并行处理,但Transformer依然是以一维序列作为输入,然而图片数据都是二维的,因此首先要解决的问题是如何将图片以合适的方式输入到模型中。本文采用的是切块 + embedding的方法,如下图:
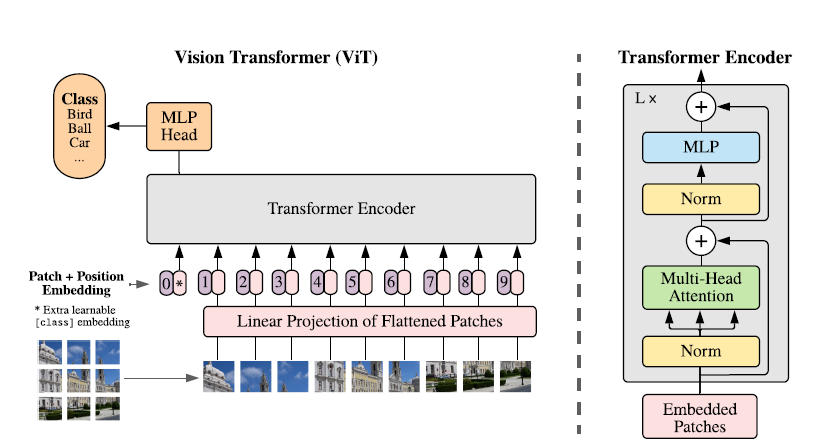
首先将原始图片划分为多个子图(patch),每个子图相当于一个word,这个过程也可以表示为:

其中x是输入图片,xp则是处理后的子图序列,P2则是子图的分辨率,N则是切分后的子图数量(即序列长度),显然有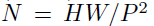 。由于Transformer只接受1D序列作为输入,因此还需要对每个patch进行embedding,通过一个线性变换层将二维的patch嵌入表示为长度为D的一维向量,得到的输出被称为patch嵌入。 类似于BERT模型的[class] token机制,对每一个patch嵌入
。由于Transformer只接受1D序列作为输入,因此还需要对每个patch进行embedding,通过一个线性变换层将二维的patch嵌入表示为长度为D的一维向量,得到的输出被称为patch嵌入。 类似于BERT模型的[class] token机制,对每一个patch嵌入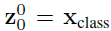 ,都会额外预测一个可学习的嵌入表示,然后将这个嵌入表示在encoder中的最终输出(
,都会额外预测一个可学习的嵌入表示,然后将这个嵌入表示在encoder中的最终输出(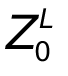 )作为对应patch的表示。在预训练和微调阶段,分类头都依赖于。 此外还加入了位置嵌入信息(图中的0,1,2,3…),因为序列化的patch丢失了他们在图片中的位置信息。作者尝试了各种不同的2D嵌入方法,但是相较于一般的1D嵌入并没有任何显著的性能提升,因此最终使用联合嵌入作为输入。 模型结构与标准的Transformer相同(如上图右侧),即由多个交互层多头注意力(MSA)和多层感知器(MLP)构成。在每个模块前使用LayerNorm,在模块后使用残差连接。使用GELU作为MLP的激活函数。整个模型的更新公式如下:
)作为对应patch的表示。在预训练和微调阶段,分类头都依赖于。 此外还加入了位置嵌入信息(图中的0,1,2,3…),因为序列化的patch丢失了他们在图片中的位置信息。作者尝试了各种不同的2D嵌入方法,但是相较于一般的1D嵌入并没有任何显著的性能提升,因此最终使用联合嵌入作为输入。 模型结构与标准的Transformer相同(如上图右侧),即由多个交互层多头注意力(MSA)和多层感知器(MLP)构成。在每个模块前使用LayerNorm,在模块后使用残差连接。使用GELU作为MLP的激活函数。整个模型的更新公式如下:
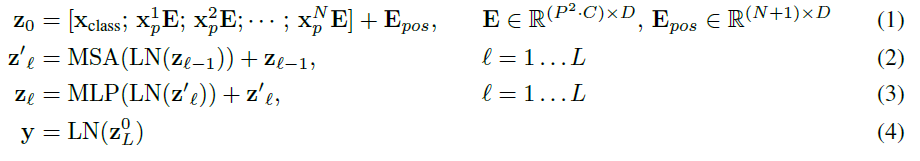
其中(1)代表了嵌入层的更新,公式(2)和(3)则代表了MSA和MLP的前向传播。 此外本文还提出了一种直接采用ResNet中间层输出作为图片嵌入表示的方法,可以作为上述基于patch分割方法的替代。
模型训练和分辨率调整 和之前常用的做法一样,在针对具体任务时,先在大规模数据集上训练,然后根据具体的任务需求进行微调。这里主要是更换最后的分类头,按照分类数来设置分类头的参数形状。此外作者还发现在更高的分辨率进行微调往往能取得更好的效果,因为在保持patch分辨率不变的情况下,原始图像分辨率越高,得到的patch数越大,因此得到的有效序列也就越长。
对比实验 4.1 实验设置 首先作者设计了多个不同大小的ViT变体,分别对应不同的复杂度。
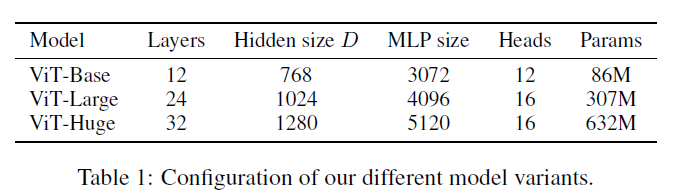
数据集主要使用ILSVRC-2012,ImageNet-21K,以及JFT数据集。 4.2 与SOTA模型的性能对比 首先是和ResNet以及efficientNet的对比,这两个模型都是比较有代表的基于CNN的模型。
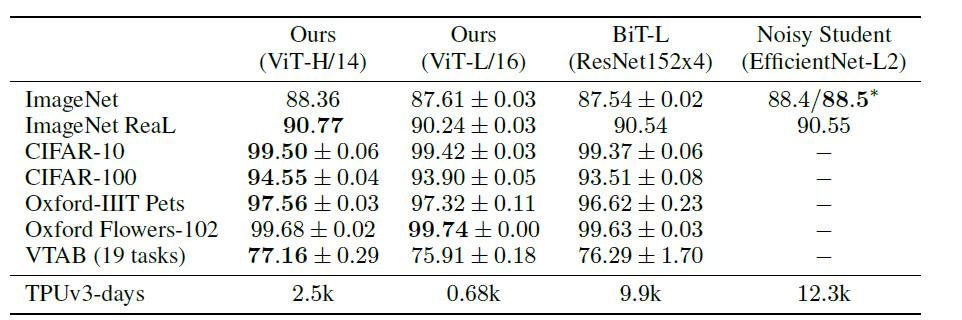
其中ViT模型都是在JFT-300M数据集上进行了预训练。从上表可以看出,复杂度较低,规模较小的ViT-L在各个数据集上都超过了ResNet,并且其所需的算力也要少十多倍。ViT-H规模更大,但性能也有进一步提升,在ImageNet, CIFAR,Oxford-IIIT, VTAB等数据集上超过了SOTA,且有大幅提升。 作者进一步将VTAB的任务分为多组,并对比了ViT和其他几个SOTA模型的性能:
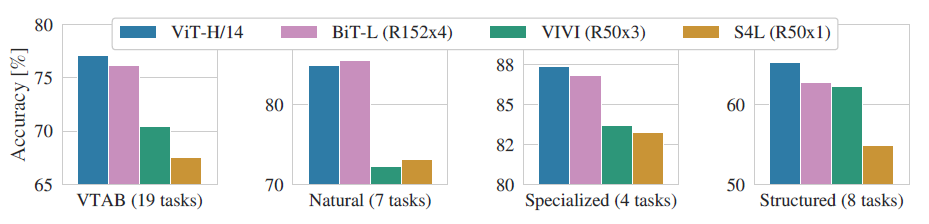
可以看到除了在Natrual任务中ViT略低于BiT外,在其他三个任务中都达到了SOTA,这再次证明了ViT的性能强大。 4.3 不同预训练数据集对性能的影响 预训练对于该模型而言是一个非常重要的环节,预训练所用数据集的规模将影响模型的归纳偏置能力,因此作者进一步探究了不同规模的预训练数据集对性能的影响:
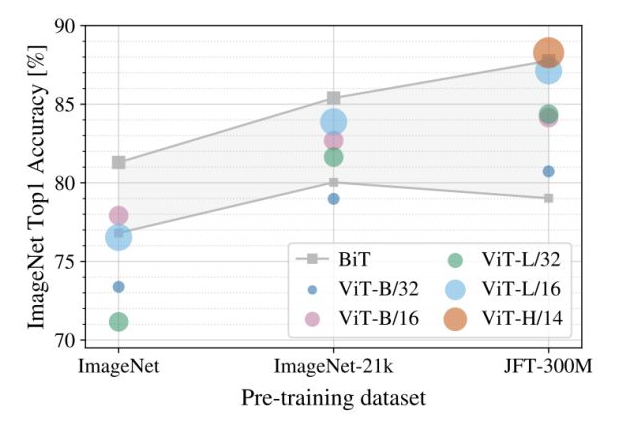
上图展示了不同规模的预训练数据集(横轴)对不同大小的模型的性能影响,注意微调时的数据集固定为ImageNet。可以看到对大部分模型而言,预训练数据集规模越大,最终的性能越好。并且随着数据集的增大,较大的ViT模型(ViT-H/14)要由于较小的ViT模型(ViT-L)。 此外,作者还在不同大小的JFT数据集的子集上进行了模型训练:
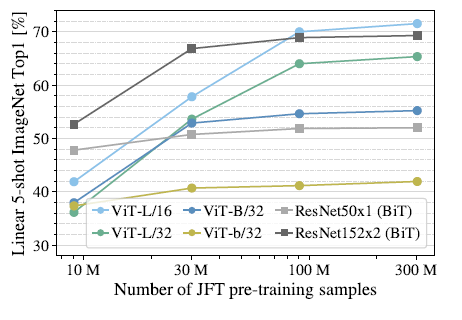
可以发现ViT-L对应的两个模型在数据集规模增大时有非常明显的提升,而ResNet则几乎没有变化。这里可以得出两个结论,一是ViT模型本身的性能上限要优于ResNet,这可以理解为注意力机制的上限高于CNN。二是在数据集非常大的情况下,ViT模型性能大幅超越ResNet, 这说明在数据足够的情况下,注意力机制完全可以代替CNN,而在数据集较小的情况下(10M),卷积则更为有效。 除了以上实验,作者还探究了ViT模型的迁移性能,实验结果表明不论是性能还是算力需求,ViT模型在进行迁移时都优于ResNet。
可视化分析 可视化分析可以帮助我们了解ViT的特征学习过程。显然,ViT模型的注意力一定是放在了与分类有关的区域:

总结 本文提出的基于patch分割的图像解释策略,在结合Transformer的情况下取得了非常好的效果,这为CV领域的其他研究提供了一个很好的思路。此外,接下来应该会出现许多基于这篇工作的研究,进一步将这一划时代的模型应用到更多的任务上,例如目标检测、实例分割、行为识别等等。此外,也会出现针对patch分割策略的改进,来进一步提高模型性能。
原文标题:告别 CNN?一张图等于 16x16 个字,计算机视觉也用上 Transformer 了
文章出处:【微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
TI科学家谈浮点DSP未来发展2009-11-03 11045
-
科学家研制可在黑暗中使用的细菌发电生物电池2013-12-03 3431
-
美科学家建新设备将光束变固体 可用于研制量子计算机2014-09-28 3890
-
美科学家推出多种波动描记传感器2018-10-24 2431
-
生物电磁波揭密 场导发现(俄罗斯华裔科学家写的脑控技术丛书)2020-03-05 5172
-
科学家证实太阳能电池“雪崩效应”2010-01-13 1214
-
科学家发现距离地球最近“黑太阳”2010-04-12 1015
-
人工智能领域科学家排名2018-04-08 17634
-
通往数据科学家的崎岖道路2018-07-26 3404
-
苹果正在招募神经科学家,意图进行AR眼镜项目研究2018-09-10 1321
-
哪些才是对数据科学家最迫切的技能呢?2018-11-19 3825
-
科学家研究发现钠离子电池中添加猛可提升电池容量2020-04-23 3863
-
采访资深数据科学家:成为数据科学家应具有的品质2020-06-30 3204
-
什么是数据科学家的最佳编程语言?2020-07-05 3296
-
中国联通AI科学家廉士国入选全球前2%顶尖科学家榜单2022-11-07 3769
全部0条评论

快来发表一下你的评论吧 !
