

研究证明:商业语音识别系统的错误率非常高
电子说
描述
某些语音识别系统(ASR)的准确性可能要比之前假定的差很多。”这是最近约翰·霍普金斯大学、波兰波兹南工业大学、弗罗茨瓦夫科技大学以及初创公司Avaya的研究人员一项正在进行的研究主要发现。
这项研究对内部创建的数据集上的商业语音识别模型进行了基准测试。共同作者声称,词错误率(Word Error Rate, WER)(一种常见的语音识别性能指标)要显著高于最佳报告结果,这可能表明自然语言处理(NLP)领域存在更多待克服的问题。
据了解,目前ASR已广泛应用于诸多场景中,如电话会议、电子邮件、智能设备等。ASR模型的综合基准中,标准语料库的WER仅有2%~3%,而正是这一统计数据遭到了上述作者的质疑。他们声称,大多数ASR的交互场景都是在“类似于聊天机器人”的背景下进行的,说话人往往因为意识到跟他们的交互对象是聊天机器人,因此通常会将命令简化成结构紧凑的简短词语,而非正常的自然对话。作者基于来自1595个供应商和1261个客户的50个呼叫中心对话数据集对几套ASR系统进行了评估。其通常时间长达8.5个小时,其中2.2个小时是对话。通过测试,作者发现ASR系统的错误率基本在15%以下,这与基准测试中的2%相悖。
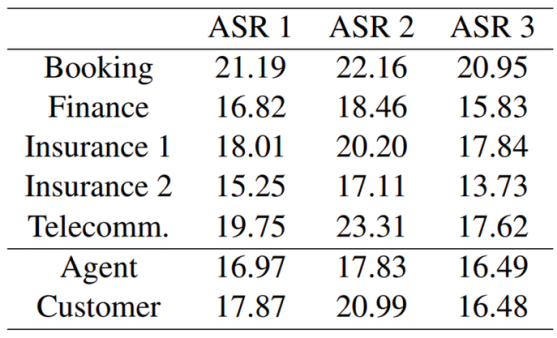
而基于保险、通信、预定等金融行业的语料库中,作者发现其WER的测试结果高达23.31%。其中,预定和通信的错误率最高,可能是因为对话涉及特定的日期、时间、订单金额、地点、产品和公司名称等。但在所有领域的测试中,其错误率均高于13.73%。
研究人员将这一问题归结为领域适应性问题——基准测试使用了单一性语料,例如Librispeech(1000小时英语有声读物录音)、WSJ(新闻口述的谈话)和Switchboard(电话交谈),这些都可能太过简单而无法真正挑战ASR系统的可靠性。
而且,尽管他们试图刻意模仿真实、自发的对话,但本质上还是受约束的,比如需要配音演员,就某一合适主题进行脚本/半脚本对话,而且正是由于配音演员的存在,几乎都不需要考虑因性别、母语因素而产生的发音问题。
作为一种补救措施,研究人员建议ASR和NLP社区收集和注释音频数据集,使其更好地与ASR系统的实际应用场景保持一致,他们还呼吁建立更具包容性的声学模型,更广泛的方言语料库,这些改变将会促进音频信号处理的技术改进。
因此,这些问题并非无法克服。“学界和工业界应该深思熟虑,考虑可以创建高质量的测试数据集。我们认为,对ASR准确性的过于乐观会损害NLP领域下游应用程序的开发。”研究人员最后表示。
责编AJX
-
基于STM32嵌入式的孤立词语音识别系统设计2021-08-06 1813
-
基于DSP的汉字语音识别系统如何实现2021-03-12 3204
-
报告指出口罩正在挫败常规的人脸识别算法,提高错误率2020-08-28 1003
-
研究显示目前的语音识别系统存在着种族差异2020-05-18 1504
-
基于LabVIEW的语音识别系统2020-03-07 8956
-
IBM宣布语音识别技术的错误率已接近人类2019-10-24 1193
-
语音识别系统功能_语音识别系统的应用2019-10-01 6291
-
怎么设计基于嵌入式系统的语音口令识别系统?2019-09-03 3126
-
高通语音识别系统近乎完美2018-05-30 4608
-
微软语音识别系统错误率仅为5.1%,达成新的精准里程碑!2017-08-23 2128
-
基于语音特征聚类的HMM语音识别系统研究姚敏锋2017-03-15 1038
-
FPGA和Nios_软核的语音识别系统的研究2012-08-11 3297
-
交互式语音识别系统研究2011-05-28 1617
-
车辆牌照识别系统的原理及算法研究2009-12-02 3935
全部0条评论

快来发表一下你的评论吧 !
