

四足机器人可穿越各种复杂的环境 无需摄像头、激光雷达等设备
描述
近日,瑞士 ANYbotics 公司打造的 ANYmal 机器人登上了新一期的《Science Robotics》封面,这款机器人的控制器可以使其穿越各种复杂的环境,包括溪流、草地、雪地、碎石坡等,而且不靠摄像头、激光雷达等常见设备——平衡系统不需要任何外界信息的输入,控制模型也不包含人类输入的规则。
腿式运动扩展了机器人的应用范围,但在地球上一些最具挑战性的环境中,大部分腿式机器人依然无能为力。
多年来,瑞士 ANYbotics 公司的团队一直在试图解决这个问题,他们的最新研究成果——《Learning quadrupedal locomotion over challenging terrain》登上了新一期《Science Robotics》的封面。
在这篇论文中,他们提出了一种稳健的控制器,可以部署到 ANYbotics 旗下多种机器人中。有了新型控制器的加持,这些机器人可以轻松翻越溪流、草地、雪地、碎石坡等富有挑战的场景。
我们可以看到,这些机器人可以轻松走过小溪:

行走在林间,即使是草木丛生的不平坦地面:

在下坡的雪地上行走:

从有水流过的台阶爬下去:

在这样复杂的环境中行走,对于人或动物来说有时也会显得磕磕绊绊,要打造能如履平地的机器人,难度自不必说了。
「传统的」控制方法已经不够用了
在不平坦的地形上,常规腿式运动方法方法使得控制架构越来越复杂。许多情况都要依赖复杂的状态机来协调运动原语和反射控制器的执行。为了触发状态之间的转换或反射的执行,许多系统都明确地预估状态,例如地面接触和滑行移动。这种预估通常是基于经验设置的,并且在存在诸如泥土、雪地或植被等未建模因素的情况下可能会变得不稳定。还有一些在脚部使用接触式传感器的系统,在野外条件下也会变得不可靠。
总体而言,随着考虑更多场景,用于在崎岖等特殊地形上进行腿式运动的常规系统的复杂性不断升级。在开发和维护方面变得非常困难,并且也容易出现控制器设计无法实现的情况(角落情况)。
近来无模型强化学习(RL)已经成为腿式机器人运动控制器开发中的一种替代方法。强化学习方向的观点是调整控制器以优化给定的奖励函数。优化是通过执行控制器本身获取的数据来执行的,这会随着经验的增加而改进。强化学习已经用于简化运动控制器的设计,自动化设计过程的各个部分以及学习之前的方法无法设计的行为。
但是,将强化学习用于腿式运动在很大程度上仅限于实验中的环境和条件。此前的研究实现了运动和恢复行为的端到端学习,但仅限于在实验室的平坦地面上进行。其他研究也开发了用于腿式运动的强化学习技术,但同样是在实验的环境中,主要集中在平坦或带有中等纹理的表面上。
ANYbotics 的研究者提出了一种稳健的控制器,用于在充满挑战的地形上进行盲四足运动。该控制器仅使用联合编码器和惯性测量单元的本体感受(proprioceptive)度量,这是腿式机器人上最耐用最可靠的传感器。控制器的操作如下图所示。

该控制器被用于 ANYmal 四足机器人的两代版本中。四足机器人在泥土、沙子、瓦砾、茂密的植被、雪地、水中和其他越野地形中安全地小跑。
研究人员介绍说,这个控制器由一种神经网络策略驱动,在模拟环境中进行训练。虽然没有任何现实世界的数据和精确的地形模型,该控制器仍然能克服野外的各种不规则地形。研究人员还强调说,「我们的系统可以穿越视频所示的所有地形,而且一次都没有摔倒。」
此外,这项研究中提到的方法并没有用到摄像头、激光雷达或接触式传感器信息,只依赖本体感受传感器信号(proprioceptive sensor signal)来提高控制策略在不同地形中的适应性和稳健性。
先模拟,再实战
相比之下,对于有足机器人,我们对于波士顿动力旗下的产品更加了解一些,不过来自苏黎世理工的 ANYmal 其实一样能力强大。基于学习的运动控制器使四足 ANYmal 机器人能够穿越充满挑战的自然环境。
与此前的一些无模型强化学习腿式运动方法一样,研究人员先在模拟环境中训练了控制器,随后将训练结果迁移到现实世界中。通常,首先需要在虚拟环境中对物理条件进行建模,进而参数随机化。
苏黎世理工的研究人员发现,这种方法对于更加崎岖的地形效果不佳,因此研究人员引入了一些其他方法。首先在模型上,新方法没有使用在机器人当前状态的快照上运行的多层感知器(MLP),而是使用了序列模型,特别是感受状态的时间卷积网络(TCN)。新方法没有使用显式的接触和滑动预估模块,相反的 TCN 会根据需求从本体感受历史中隐式地推理出接触和滑动事件。

实现优化结果的第二个关键在于特权学习(privileged learning),研究人员发现直接通过强化学习训练出的越野运动策略并不成功:控制信号稀疏,并且所输出的网络无法在合理的时间内学习出正确的运动。新的模型在训练中分为两个阶段,首先训练教师策略,该策略可访问特权信息——真实情况(ground-truth)及机器人接触的情况,随后教师指导纯本体感受的学生控制器学习,后者仅使用机器人本身可用的传感器信息。
这种特权学习会在模拟环境中启用,但最终学习到的策略可以在模拟环境,以及真实的物理环境中部署。
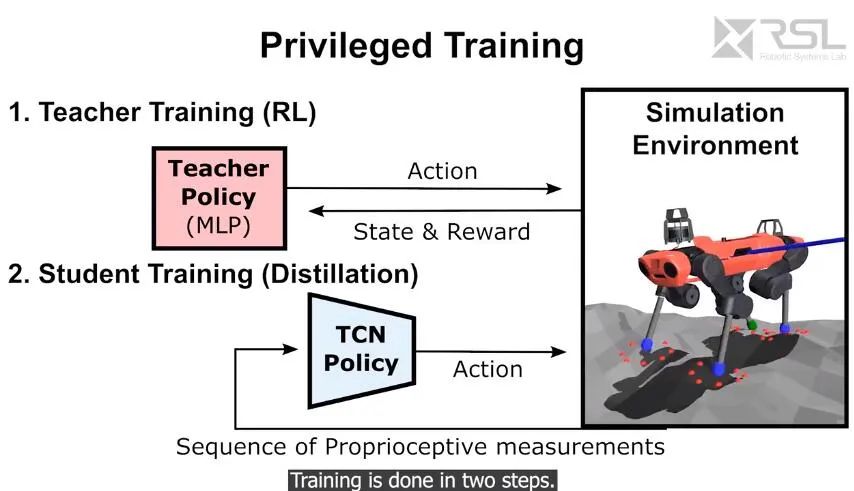
第三个概念对于实现其鲁棒性很重要。该教程根据控制器在训练过程不同阶段的表现,对不同地形进行自适应。本质上,控制器会经历各种合成地形的考验,同时变得更具鲁棒性。研究者评估了参数化地形的可通行性,并使用了粒子滤波来维持中等难度地形参数的分布,以适应神经网络的学习。训练环境的挑战性逐渐增加,促使了这种敏捷性与弹性兼具的全方位控制器的诞生。
借助腿式运动控制器,机器人可以穿越一些现有方法无法到达的复杂地形。该控制器拥有在零样本环境中的泛化能力,即使遇见训练过程中未见过的条件,仍然具备鲁棒性。
研究者在模拟训练中只使用了刚性地貌和一组由程序生成的地形剖面,比如山丘和台阶。然而,当控制器被部署在四足机器人上时,它能够成功应对可变化地形(比如泥土、苔藓、雪地)、动态立足点(比如在杂乱室内环境踩到滚动板、田野中的碎片)和地面障碍物(厚植被、碎石、涌出的水)。
从研究结果来看,不需要进行艰苦的建模过程,以及危险且高成本的实地测试,物理世界的极度复杂性也可以被克服。这一方法或许会引领未来腿式机器人的发展。
更适合复杂环境,更适用于真实世界
在四足机器人领域里,名头更响的波士顿动力 Spot 已在今年开卖了,目前全球已卖出约 300 台,不过人们在使用 Spot 的时候会遭遇一些「翻车」情况。

对于面向工业场景的用户来说,稳定性至关重要,在这方面不知 ANYmal 的机器人是否更加强大。在今年 6 月,这家公司的机器人也已向用户交付了自家的四足机器人 Anymal C。
ANYmal 机器人由 ANYbotics 公司打造。ANYbotics 成立于 2016 年,是瑞士苏黎世联邦理工学院的衍生公司,致力于开发工业应用的移动机器人技术。该公司表示,其自动腿式机器人的设计目的是解决客户在具有挑战性的环境中遇到的问题。该公司已经在多个应用中进行过 ANYmal 机器人的成功测试,如在北海上进行的首例离岸机器人测试。
ANYbotics 的团队表示,他们从事腿式机器人的研究已经超过 10 年,如今又根据工业需求重新对 ANYmal 机器人进行了设计。他们的研究核心是设计出强大的扭矩可控制动器,使得机器人能够爬上陡峭的楼梯,可靠地承受各种环境变化带来的压力。
在过去的十年中,ANYmal 系列机器人也经历了一系列的更新换代和技术革新,从最初的 ANYmal Alph 到 ANYmal Beth、ANYmal B 再到如今的 ANYmal C。经过数次迭代,ANYmal 变得越发强大。
论文链接:https://robotics.sciencemag.org/content/5/47/eabc5986
文章转自“机器之心”
责任编辑:PSY
原文标题:不用摄像头和激光雷达,四足机器人「凭感觉」越野
文章出处:【微信公众号:中科院长春光机所】欢迎添加关注!文章转载请注明出处。
-
详细介绍机场智能指路机器人的工作原理2025-05-10 1260
-
激光导航AGV底盘定制 巡检机器人,服务机器人,智慧物流搬运AGV2017-06-10 8367
-
速腾聚创激光雷达现在实现量产2017-08-21 3535
-
浅析自动驾驶发展趋势,激光雷达是未来?2017-09-06 5540
-
激光雷达分类以及应用2017-09-19 8923
-
【Firefly RK3399试用体验】+ 双目摄像头开发之景深相机调研2017-11-12 7140
-
消费级激光雷达的起航2017-12-07 7513
-
让机器人在陌生环境里穿梭自如的激光雷达2018-09-10 3959
-
除了机器人行业,激光雷达还能应用于哪些领域?2018-12-10 4925
-
机器人和激光雷达都不可或缺2019-02-15 6239
-
TOF激光雷达2019-06-07 9316
-
四足机器人的机构设计2021-09-15 2144
-
激光雷达是什么,激光雷达的应用说明2022-06-20 26761
-
激光雷达、单目摄像头、双目摄像头原理和优缺点2022-03-26 18800
-
激光雷达烧坏摄像头?2023-11-30 2682
全部0条评论

快来发表一下你的评论吧 !
