

非金属材料的前世今生
描述
来源|中科院之声(zkyzswx)编者按:中科院之声与中国科学院上海硅酸盐研究所联合开设“科普硅立方”专栏,为大家介绍先进无机非金属材料的前世今生。我们将带你——认识晶格,挑战势垒,寻觅暗物质,今古论陶瓷;弥补缺陷,能级跃迁,嫦娥织外衣,溢彩话琉璃。
被戏称为诺贝尔“理综奖”的化学奖今年再度授予给生物学家,以表彰她们对新一代基因编辑技术的贡献。生物基因是生物体内携带遗传信息的DNA片段,影响甚至决定着生物体的生长发育、衰老病死等所有生理过程。生物基因工程则是在分子水平上对基因进行重组,改变生物原本的遗传信息,旨在按需设计新品种和产生新产品。那么,同样是由微观粒子(原子、分子、离子等)构成的材料,是否也存在决定材料性能的“基因”呢?人们能否利用材料基因工程技术,按需设计特定性能的材料呢?
材料基因工程
答案是肯定的,而且已经引起各国的重视。早在2011年,美国联邦政府率先启动了一项名为“材料基因组计划”(Materials Genome Initiative, MGI)的研究计划,通过先进实验和计算技术和数据共享等方式,加速新材料的发现,缩短材料研发周期,同时降低成本。同年年底,中国科学院和中国工程院召开了香山科学会议研讨“材料科学系统工程”,并由徐匡迪院士、顾秉林院士、陈立泉院士和张统一院士等学者提出启动中国的“材料基因组计划”。此外,其他国家和地区,例如欧盟、日本和俄罗斯等也相继启动类似的材料研究计划。
图1 美国材料基因组计划框架(图片来自网络)
虽然“材料基因”一词经过多年的探讨,但是至今依旧没有明确的科学定义,其复杂性就可见一斑。相比生物基因仅由几种核苷酸排列而成,材料组成和结构显得更加复杂,材料基因工程的研究也更具有挑战性。传统的科学研究范式可能并不能满足快速解码材料基因图谱的需求,因此材料信息学就应运而生。
人工智能+材料科学
在了解材料信息学之前,我们首先需要对材料科学研究四大范式的发展脉络有整体的认识。四大范式包括,实验试错、理论推演、模拟计算和数据科学。
新材料的研发最传统的方式是实验试错法,即通过改变材料成分、合成手段、工艺参数等条件制备系列样品,选出其中性能最合适的材料。很显然,试错法存在效率低、成本高、研发周期长等缺点,因此往往被戏称为“炒菜法”,但是多年以来也为材料科学积累了大量的数据和经验法则。
理论推演则是在对自然有充分认识、掌握足够多的规律之后,科学家将自然现象抽象成数量关系,构造数学模型,并在模型预测的指导下研发材料。然而,由于实际问题往往相当复杂,理论模型的建立需要采用近似处理方法,因而不可避免地存在偏差和局限。随着电子计算机的发展,科学家可以依据更本质的物理定律,对复杂过程进行多空间尺度模拟,从而定向设计材料成分、结构和性能。即便如此,模拟计算需要基于理论框架和依赖参数设置,因此计算结果与实验结果大相径庭的情况时有发生。
材料信息学一改以往研究范式对经验和理论模型的依赖,直接针对可能与目标量相关的数据,分析其中统计关联性,再从中研究材料成分、结构、工艺和性能之间的物理内涵。这种由数据驱动的方法借助如今快速发展的大数据和人工智能方法,从大量、复杂的变量集合中提取决定性因素,构建数据之间的定量关系,指导新规律的发现和新材料的快速研发。
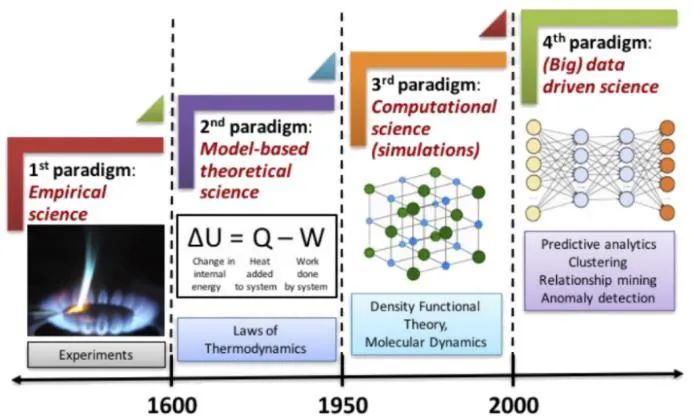
图2 科学研究四大范式(图片来自网络)
说白了,材料信息学可以简单地认为是“人工智能+材料科学”。提起“人工智能”,你可能会想起几年前的围棋人机大战:围棋世界冠军柯洁完败。人类冠军低头拭泪,痛苦感叹“它太完美,我看不到任何胜利的希望”的场景依旧历历在目。在柯洁战败之前,“AI+”早已引起学术界的重视。2016年1月27日“AI+围棋”登上顶尖科学期刊《自然》封面,报道了谷歌 Deep Mind 的人工智能系统阿尔法围棋(Alpha Go)完胜欧洲围棋冠军。同年5月4日,“AI+材料科学”也登上了《自然》封面,报道了材料科学领域的“人机大战”。这项研究由哈弗福德学院(Haverford College)主导,针对一种有机-无机杂化材料的水热合成反应,通过机器学习方法从大量成功和失败的实验数据中发现规律,并建立判断反应能否成功的预测模型。机器学习模型成功率高达89%,高于有经验的化学家的人工判断78%。这项报道充分展示了人工智能在材料科学研究中的强大潜力,掀起了“AI+材料科学”的浪潮。
图3 Nature封面文章:“AI+围棋”和“AI+材料科学” (图片来自网络)
“数据困境”与破解之法
两场“人机大战”之中,战胜人类棋手的Alpha Go背后主要利用了深度神经网络,战胜人类化学家的预测模型背后主要是支持向量机,它们都属于机器学习方法。机器学习是实现人工智能的一类方法,其基本过程是采用程序算法利用大量的数据进行建模训练,从数据中学习规律,最终对未知事物做出决策和预测。机器学习方法研究材料科学一般分为数据集构造、数据预处理、数据降维、模型训练、模型测试与评价等步骤。其中,数据集构造是首要步骤,数据收集是材料信息学的重点和难点。你或许会疑惑,数据收集不是很简单吗?我们只需要在购物app内点击某件商品,在新闻app内浏览某条新闻,在地图app内搜索某个地点……我们在互联网上的一切行为,每时每刻都在都转化为数据被收集。然而,在材料科学领域,获取一个数据可能意味着几个小时的模拟计算,几天的材料制备,几周的循环测试……因此,材料学的数据很难成为“大数据”,至少现阶段只能是“小数据”。正是由于数据量小,数据偏差和噪声对模型的影响将会十分显著。机器学习的算法再优化,计算机的算力再提升,我们手里只有稀疏、高维、有偏差和带噪音的数据,材料信息学将面临“巧妇难为无米之炊”的困境。
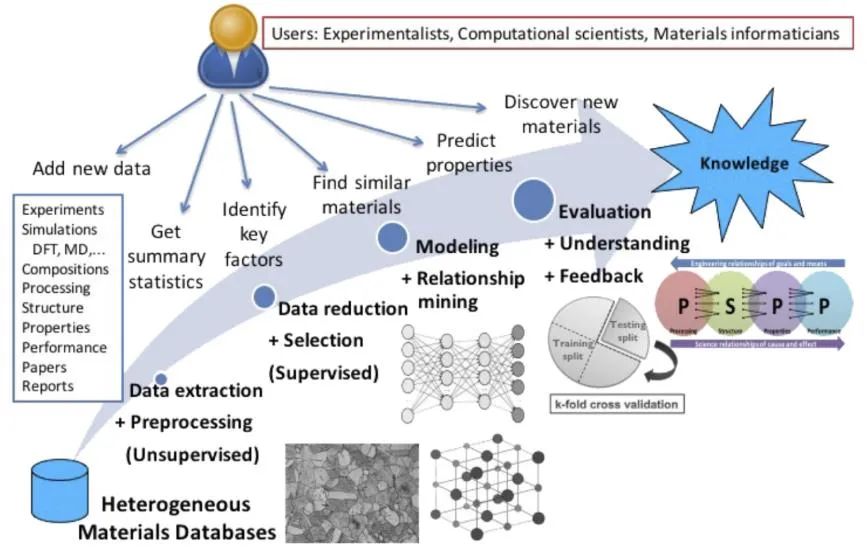
图4 机器学习方法研究材料科学的基本流程(图片来自网络)
破解“数据困境”需要从两个方面着手:生产和流通。在数据生产方面,随着各国有关材料基因工程的项目推进,高通量实验和计算快速发展,对数据的标准化和高效产出有非常积极的作用。在数据流通方面,国外的Materials Project以及我国的Atomly等数据库免费开放大量的计算数据,便于数据共享。哈弗福德学院建立了“黑暗反应计划”(Dark Reaction Project)平台,鼓励研究者们在发表“成功的”数据之后,再将不发表的“失败的”数据上传到平台,以供机器学习模型对化学反应进行更加深入的分析。借助高通量、数据库、互联网等新技术加速材料数据生产和流通方兴未艾,这个时代留给了材料人大展拳脚的广阔舞台。
我们不妨畅想未来的材料实验室成为“数据工厂”的那天:智能化的实验机器人,严格标准化的样品制备和测试表征,完全电子化的实验记录,融合物联网的内部即时数据共享平台,融合区块链技术的国际数据交易平台,以及更加先进的处理和分析数据的人工智能方法。我们材料人将会从“磨金相、守炉子、过柱子”,甚至复杂的数据分析之中解放出来,转型为“开发者”、“合作者”和“研究者”。“开发者”负责AI算法和智能化实验机器的开发与维护;“合作者”熟悉编程和材料研究的两套逻辑和语言,促进“开发者”和“研究者”的沟通交流;“研究者”捕捉行业痛点,提出科学问题,创新研究思路。到那一天,或许我们能够解码出材料基因图谱,每一位材料人都能像钢铁侠一样帅气地研发材料。
参考文献:
1. Agrawal A, Choudhary A. Perspective: Materials informatics and big data: Realization of the “fourth paradigm” of science in materials science[J]. APL Materials, 2016, 4(5):053208-1-10.
2. Liu Y, Zhao T, Ju W, et al. Materials discovery and design using machine learning[J]. Journal of Materiomics, 2017, 3(3).
3. Dima A, Bhaskarla S , Becker C , et al. Informatics Infrastructure for the Materials Genome Initiative[J]. JOM - Journal of the Minerals, Metals and Materials Society, 2016, 68(8):2053-2064.
4. Anubhav J, Shyue P O, Geoffroy H, et al. Commentary: The Materials Project: A materials genome approach to accelerating materials innovation[J]. APL Materials, 2013, 1():011002-1-11
5. Hanoch S, Alexander T. Materials Informatics. Journal of Chemical Information and Modeling 2018 58 (7), 1313-1314
6. 施思齐,徐积维,崔艳华 等. 多尺度材料计算方法[J]. 科技导报, 2015, 33(10):20-30
责任编辑:xj
原文标题:材料信息学:解码材料基因图谱丨科普硅立方
文章出处:【微信公众号:中科院半导体所】欢迎添加关注!文章转载请注明出处。
-
汽车非金属材料机械性能测试内容有哪些?2025-06-18 827
-
盐雾试验箱能否用于非金属材料的测试?2024-08-06 1052
-
金属薄板、软质非金属材料拉力测试方案:视频引伸计+单柱万能试验机实测!2023-05-26 1959
-
我司交付海军非金属材料检测中心非金属材料封箱实验箱2023-02-17 1259
-
氮化镓属于无机非金属材料吗2023-02-13 6186
-
喜讯!和晟仪器中标某医学中心某部非金属材料封箱实验箱项目2022-01-05 989
-
金属材料单重计算 软件2021-09-26 5947
-
芯片春秋——ARM前世今生2020-05-25 2320
-
金属材料的物理性能2017-08-25 3213
-
金属材料工程词典2010-12-07 1657
-
质子导电性无机非金属材料的发展及其应用2009-07-14 576
-
非金属材料的分类2008-12-24 13214
-
金属材料基本知识2008-12-23 1302
全部0条评论

快来发表一下你的评论吧 !
