

用 “心跳”识别假视频,准确率高达 97%
电子说
描述
Deepfake 真是让人又爱又恨。
众所周知,基于深度学习模型的 Deepfake 软件,可以制造虚假的人脸视频或图像。它在影视、娱乐等行业有着广泛的应用场景。
但自 2017 年起,Deepfake 也开始被不良分子用来制造色情视频——神奇女侠下海事件。据统计,社交网络中的 Deepfake 视频,96% 涉及色情内容,观看用户数量已超过了 1.3 亿。
此外,Deepfake 也开始涉足政治领域,被用来伪造虚假政客言论,相关数据也在逐年增长。
奥巴马发表着与自己不相关的言论
更重要的是,随着 Deepfake 技术的不断升级,这些伪造视频越来越难以分辨真假,对社会稳定构成了极大的威胁。
而近日,一篇刊登在 IEEE PAMI(模式分析与机器智能汇刊)的一篇论文声称,有新的方法能够识别 Deepfake 视频,准确率高达 97.29%,而且还能够发现制造 Deepfake 背后的生成模型。
更有意思的是,不同于常规检测法,该论文强调其利用的是生物信号——心跳。
Deepfake“心跳”检测法
这篇论文来自宾厄姆顿大学(Binghamton University)与英特尔(Intel)公司联合组成的研究团队。该团队称,这款 AI 工具名为 FakeCatcher,它可以通过检测心跳在面部产生的细微差别来区分视频真假。
我们知道,血管遍布人体全身,包括面部。当心脏跳动时会带动全身的血液流动,流动的血液会在人脸表面产生细微的变化,而这种变化正是研究人员区分真假视频的关键。
研究人员把区分这种变化的方法称为光体积变化描计法(Photoplethysmography,简称 PPG)。简单来说,就是利用光率的脉动变化,折算成电信号,从而对应成心率。
这一原理与医学脉搏血氧仪,苹果手表以及可穿戴健身跟踪设备检测运动状态时的心跳信号类似。
该项研究的前提假设是:生物信号是区分真假人脸的重要标识。也就是说,假视频中显示的 “人”不会表现出与真实视频中的人相似的心跳模式。
基于此,研究人员经过实验发现,Deepfake 人脸无法正常还原因血液流动造成的微弱变化。
英特尔公司的资深研究科学家伊尔克 · 德米尔(Ilke Demir)介绍称,
我们从脸部的不同部位提取几个 PPG 信号,并观察了这些信号在空间维度和时间维度上的一致性。
在这里空间维度指的是面部区域,时间维度指的是心跳频率。Demir 的意思是,通过读取 PPG 信号和增强技术,还原并放大其在面部所产生的微弱变化,以此判断视频的真假。
如果是 Deepfake 视频,所产生的面部效果会非常不自然。如下图:
具体来说,FakeCatcher 完整的检测过程如下:1)识别关键的人脸区域;2)提取生物信号(PPG);3)利用信号转换计算空间维度和时间维度的相关性,并在特征集和 PPG 映射中捕获信号特征并训练概率;4)根据真实性概率对视频真假进行分类。
研究人员介绍称,在这一过程中主要取得三个方面的进步:
通过信号转换公式和实验,验证了利用生物信号的空间一致性和时间一致性检验视频真假的可行性。
提出了一种新型通用的 Deepfake 检测器。
提出了一种新的生物信号构造图,可用于训练神经网络进行真实性分类。
构建了一个多样化的人像视频数据集,为虚假内容检测提供了一个试验台。
模型精度测试结果在实验之前,为了更加精准地评估 FakeCatcher 模型,研究人员自建一个 Deepfake 数据集,该数据集来自媒体网络、新闻文章和研究报告等,因此,视频在生成模型、分辨率、压缩、照明、纵横比、帧速率、运动、姿势、遮挡、内容等方面的问题都是真实存在的。
该数据集包含了 142 个视频,有 30 GB 大小。从下图分类结果来看,FakeCatcher 对低分辨率、压缩、运动、照明、遮挡等问题的表现都是鲁棒性的。
上半部分为真实视频,下半部分为 Deepfake 视频
接下来,研究人员主要进行了两项实验验证。一是与当前的深度学习解决方案和其他 Deepfake 检测器进行比较。实验结果如下:
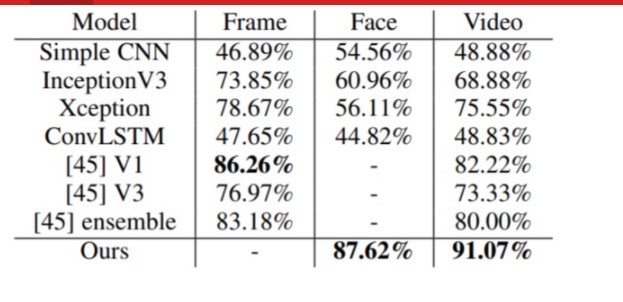
其中,Frame 和 Face 表示分段精度,可以看出 FakeCatcher 最高,达到了 87.62%;Video 表示视频精确度。FakeCatcher 比最好的架构还要高出 8.85%。
需要说明的是,表中所有实验都是在自建数据集 DF(60% 训练和 40% 的测试的分割)中进行的。
二是进行交叉数据集验证,分别包括 DF、Celeb DF、FF、FF++ 和 UADFV 数据集。
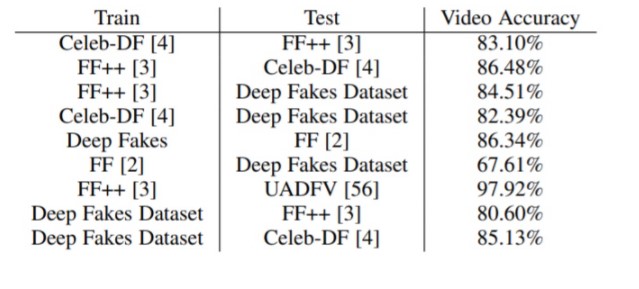
第一列为训练数据集,第二列为测试数据集
从第 5 行和第 6 行来看,FakeCatcher 在小而多样的数据集中的学习效果要比在大型且单一的数据集上更好。一方面是,DF 训练和 FF 测试比反过来的测试精度高出了 18.73%。另一方面是,DF 数据集大约只有 FF 数据集的 5%。从第 3 行和第 6 行来看,可以发现从 FF 到 FF++ 增加分集,DF 的准确率提高了 16.9%。
在交叉数据集 FF++ 中,每个原始视频包含四个合成视频,其中每个视频都使用不同的生成模型生成。研究人员将 FF++ 的原始视频分割为 60% 训练,40% 测试。然后创建这些集合的四个副本,并从每个集合中删除特定模型生成的所有样本。
表中第 1 列,每个集合包含三个模型的 600 个真实视频和 1800 个假视频,以及一个模型的 400 个真实视频和 400 个假视频进行测试。
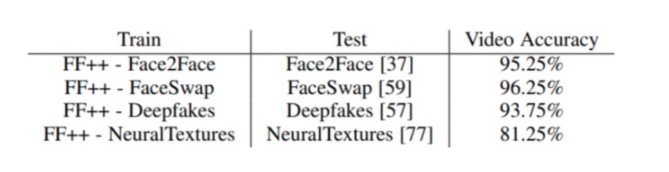
从跨模型评估结果来看,除了 NeuralTextures,其他均得到了非常精确的预测。而 NeuralTextures 本质上就是不同的生成模型。
由此,论文最后得出结论称,基于生物信号的 Deepfake 视频检测器 FakeCatcher,证明了生物信号的空间维度和时间维度的一致性在 GAN-Rated 内容中并没有得到很好的保持。
此外,通过人脸取证实验并引入自建 DF 数据集中,对视频片段、视频的成对分离以及真实性分类方法进行评估,分别得到了 99.39%,96% 以及 91.07% 准确率。这些结果再次验证了 FakeCatcher 可以高精度地检测假内容,而不依赖视频的生成器、内容、分辨率以及质量等指标。
责任编辑:PSY
-
TF之LoR:基于tensorflow实现手写数字图片识别准确率2018-12-19 2625
-
基于RBM实现手写数字识别高准确率2018-12-28 2987
-
请问谁做过蚁群算法选择图像特征,使识别准确率最高?2019-02-17 3467
-
人工智能首次超过人眼准确率 人脸识别准确度已经提升4个数量级2018-02-06 14313
-
Apple Watch居然还能检测心律失常 准确率高达97%2018-03-22 18001
-
阿里达摩院公布自研语音识别模型DFSMN,识别准确率达96.04%2018-06-07 4546
-
机器学习实用指南——准确率与召回率2018-06-19 22091
-
人脸识别准确率大幅度提升,离不开科技企业的努力2018-09-30 2361
-
微软开发出一种新系统 区分安全漏洞和非安全漏洞准确率高达99%2020-04-17 4252
-
脑机接口实现新突破,语音识别准确率高达97%2020-05-26 2947
-
AI垃圾分类的准确率和召回率达到99%2020-06-16 4401
-
美国戴口罩面部识别技术准确率高达96%2021-01-18 3142
-
根据短视频特征信息提高人物行为识别准确率2021-04-07 1499
-
ai人工智能回答准确率高吗2024-10-17 12112
-
电能质量在线监测装置识别谐波源的准确率有多高?2025-10-22 1096
全部0条评论

快来发表一下你的评论吧 !
