

浅谈4位HRRG计算机定义的汇编语言
描述
我们要做的一件事就是为我们的4位HRRG计算机定义这样的汇编语言,但是在我们陷入沉迷和放弃之前,我们首先需要引入一些概念。
大端与小端
当现实世界中的计算机使用多个字节表示数据值或内存地址时,有两种主要技术可将这些字节存储在内存中:最高有效字节(MSB)存储在以下位置:具有最低地址的位置,在这种情况下,我们可以说它以“ big-end-first-first”存储,或者最低有效字节(LSB)存储在最低的地址,在这种情况下,我们可以说它是“小-最终至上。”
让我们在HRRG计算机的上下文中考虑这两种机制,它具有4位(1个半字节)数据总线和12位(3个半字节)地址总线,通过可视化我们如何在内存中存储一个3个半字节值$ 426来开始在$ 100的内存位置,如下所示:
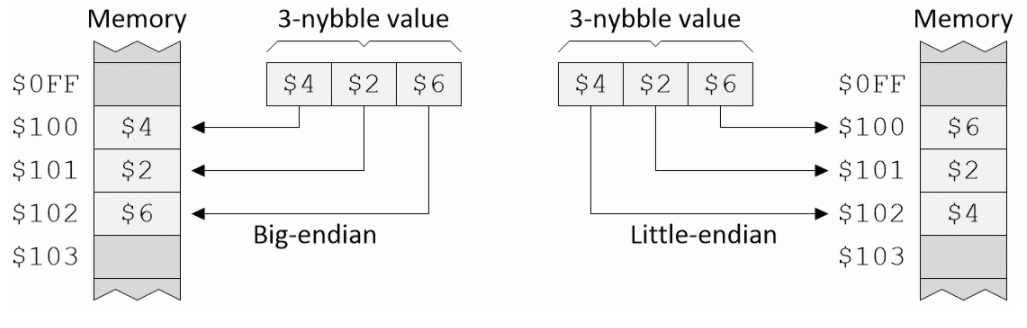
大端(由HRRG使用)与小端。(资料来源:马克斯·麦克菲尔德(Max Maxfield)
HRRG采用big-endian方法。当然,您可能不会对此感到惊讶,因为出于各种技术上的原因,而这些讨论超出了这些讨论的范围,一些计算机设计师偏爱一种风格,而其他计算机设计师则偏向于另一种风格。直到人们对创建异构计算环境感兴趣为止,这才真正变得无关紧要,在异构环境中,将多个不同的计算机连接在一起,以便可以在它们之间传输文件,此后引发了许多激烈的争论。
1980年,丹尼·科恩(Danny Cohen)撰写的著名论文《论神圣的战争与和平》,使用大尾数法和小尾数法来指代两种存储数据的技术。这些术语一直沿用至今,源于盎格鲁爱尔兰讽刺作家乔纳森·斯威夫特(Jonathan Swift)所著的《格列佛游记》。小尾数和大尾数的绰号来自故事的那部分,两个国家为此展开战争,首先要吃煮鸡蛋的一端-小端还是大端!
令您惊讶的是,斯威夫特(Swift)在1726年进行了出色的工作,这是发明台球杆的九年之前(在此之前,球员习惯用小狼牙棒来击球)。
寻址模式
术语寻址模式是指指定指令操作数的方式。这些小流氓的名字和口味有很多不同的名称,因此以下内容应仅作为概述。
出于这些讨论的目的,我们将假设一个HRRG类型的体系结构,具有4位(1个半字节)数据总线和12位(3个半字节)地址总线。但是,下面介绍的寄存器和指令助记符是虚构的,仅用于进行这些讨论时使用。
隐式(又名隐式):在隐式(有时称为隐式)寻址模式的情况下,目标本身由指令本身隐含。例如,假设我们有一个名为Q的寄存器和一个名为INCQ的指令,其目的是对寄存器Q的内容进行递增(加1)。在这种情况下,我们所要做的就是一个没有操作数的INCQ操作码,如图所示以下:
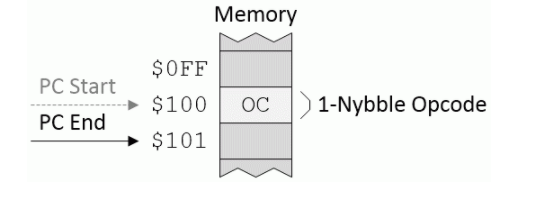
隐式寻址模式(来源:Max Maxfield)
假定程序计数器(PC)从地址$ 100开始,CPU将读取并执行隐含的操作码。我们最终将PC指向地址$ 101,这是CPU希望在程序中找到下一个操作码的位置。
立即:在立即寻址模式下,数据在操作码后立即显示。例如,假设我们有一个名为Q的寄存器和一个称为LDQ的指令,其目的是使用立即寻址模式将一小部分数据加载到寄存器Q中,如下所示:
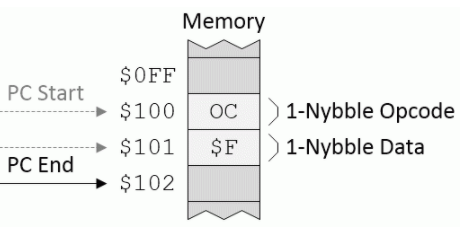
立即寻址模式(来源:Max Maxfield)
假定程序计数器(PC)从地址$ 100开始,CPU读取操作码,意识到此操作码使用立即模式,并将数据nybble(在此示例中为$ F)加载到Q寄存器中。我们最终将PC指向地址$ 102,这是CPU希望在程序中找到下一个操作码的位置。
相对:在相对寻址模式下,目标地址被指定为相对于程序计数器(PC)中当前值的偏移量。这样的偏移量将被视为可以表示正值和负值的带符号二进制数。
假设我们的偏移量表示为2个半字节值。由于2进位字段可以表示-128到+127范围内的有符号数,因此这意味着偏移量可以指向当前PC值之前的128个位置(即,较低的内存地址)和之后的127个位置之间的某个存储位置。当前的PC值(即更高的内存地址)。
纯粹是为了使示例与此处显示的其他示例相关联,假设我们有一个名为Q的寄存器和一个称为LDQ的指令,其目的是使用相对寻址模式将一小部分数据加载到寄存器Q中(尽管我们如果使用相同的助记符,则该LDQ与我们在前面示例中讨论的LDQ指令将具有不同的操作码。此外,让我们假设偏移值为$ 08(十进制为+8),如下所示:
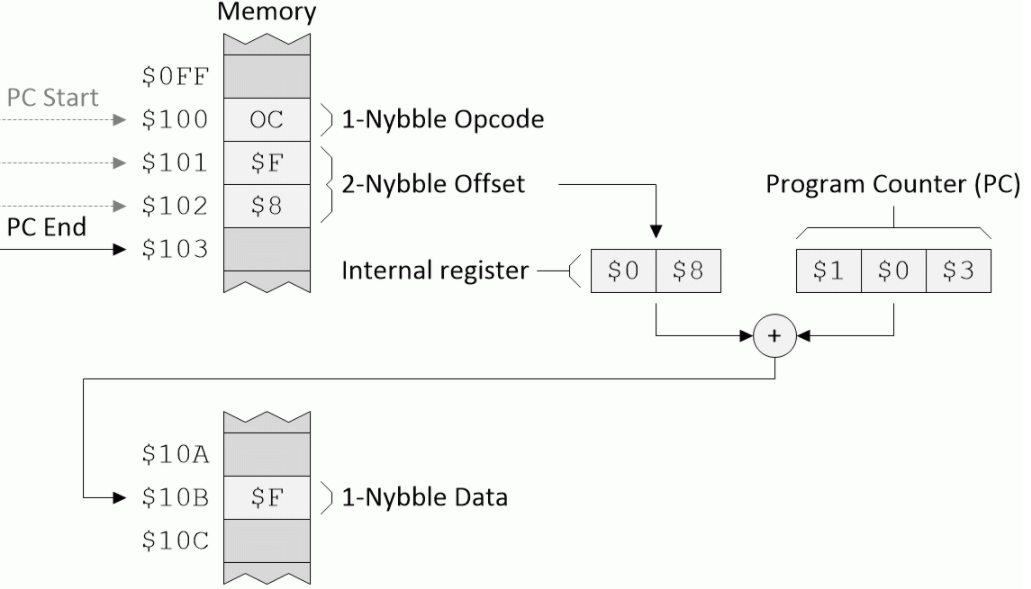
具有正偏移值的相对寻址模式。(资料来源:马克斯·麦克菲尔德(Max Maxfield)
假定程序计数器(PC)从地址$ 100开始,CPU读取操作码,意识到它使用相对模式,然后将下面两个包含偏移值的四位字节复制到内部(临时)寄存器中。
接下来,它将偏移值添加到PC中的当前值,并使用结果指向包含数据nybble的位置。最后,它将数据值(在此示例中为$ F)加载到Q寄存器中。最后,PC指向地址$ 103,这是CPU希望在程序中找到下一个操作码的位置。
纯粹出于完整性考虑,让我们考虑相对寻址的第二个示例,其中偏移值为$ F8(十进制为-8),如下所示:
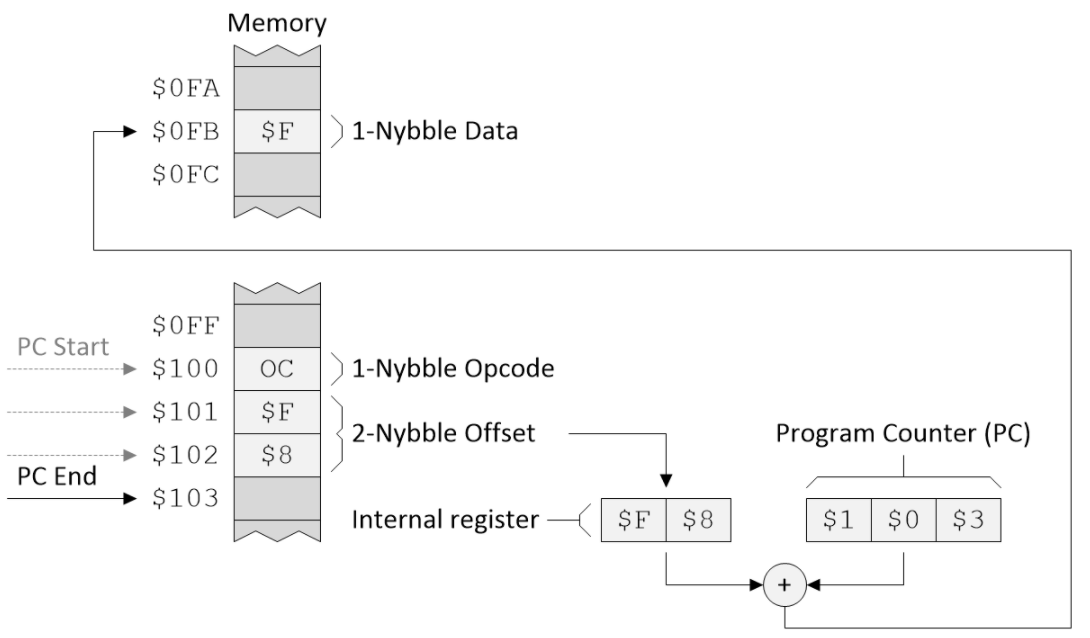
具有负偏移值的相对寻址模式。(资料来源:马克斯·麦克菲尔德(Max Maxfield)
重要的是要注意,除了上面说明的数据操作指令外,相对寻址还可以用于执行跳转或分支指令。
当然,并非所有处理器都支持所有类型指令的所有寻址模式。例如,正如我们在上一专栏中所讨论的那样,6502微处理器具有8位数据总线和16位地址总线。对于其JMP(“无条件跳转”)指令,6502仅支持使用16位(2字节)地址的绝对和间接寻址(下面介绍绝对和间接模式)。但是,6502还支持一组分支指令,这些分支指令采用8位(1字节)相对地址。正如我在该专栏中指出的:
程序往往会进行很多跳转,例如循环循环,因此在时钟有限的日子里,使用1字节的分支地址而不是2字节的跳转地址可能会节省大量的时间和空间。速度,处理器周期和内存位置。
Zilog Z80微处理器不支持相对寻址,因此您必须使用Intel 8086或更高版本才能使用相对寻址模式查看“短跳转”指令。
最后一点,在上面的讨论中,当说明要添加偏移量的值时,我们多次使用了短语“ PC中的当前值”。当“推来推去”时,我们使用了$ 103的值,这是下一个操作码的地址。我们为什么使用这个值?使用$ 100(原始操作码的地址)或$ 102(偏移量中第二个小节的地址)是否更有意义。
好吧,假设我们正在执行某种形式的分支指令,而不是执行我们虚构的LDQ指令。现在考虑如果偏移值为$ 0会发生什么。如果偏移量是从分支指令操作码的地址$ 100开始,则偏移量$ 0将导致无限循环(如果采用了分支)。或者,如果偏移量是从地址$ 102处的操作数的第二个字节开始的,则偏移量$ 0将导致CPU将操作数的第二个nybble误认为是一个操作码。归根结底,如果偏移量为$ 0,则按照我们的原始指令立即跳转到操作码是有意义的;因此,我们使用下一个操作码的地址作为“ PC中的当前值”这一事实。
只是为了确认所有这些内容,因为在我所看到的任何地方它都没有得到很好的记录,所以我请我的新手尼克·比尔德(Nick Bild)(基于6502的虚拟现实系统的创建者)提供经验证明。为此,尼克创建了一个小型的6502汇编程序,如下所示:
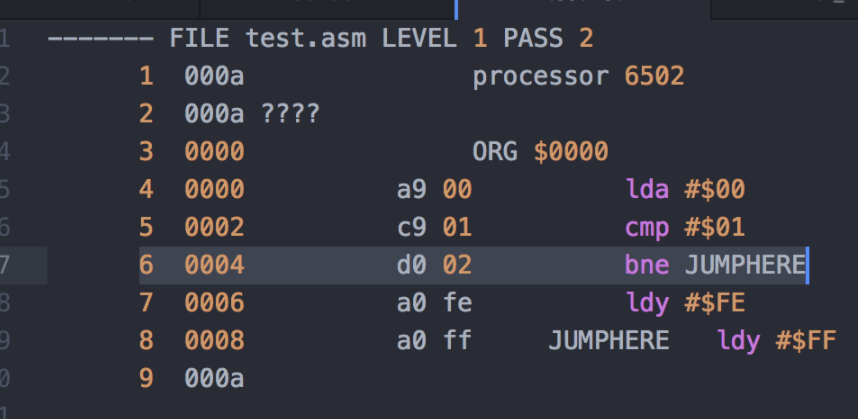
6502汇编程序(来源:Nick Bild)
请记住,6502具有8位数据总线和16位地址总线。遵守地址$ 0004的BNE(“如果不相等则分支”)指令。如果满足分支条件,该指令将跳转到地址$ 0008的JUMPHERE标签。现在观察到,由汇编程序生成并存储在地址$ 0005中的偏移值为$ 02。当然,$ 0008 – $ 02 = $ 0006,它是LDY(“装载索引寄存器Y”)指令的地址;也就是说,紧跟在BNE指令之后的操作码。优质教育
绝对(也称为直接):在绝对(有时称为直接)寻址模式下,目标地址在操作码后立即显示。例如,假设我们有一个名为Q的寄存器和一条称为LDQ的指令,其目的是使用绝对寻址模式将数据的小节加载到寄存器Q中,如下所示(再次,尽管我们使用的是相同的助记符,但该LDQ与前面示例中讨论的LDQ指令会有不同的操作码):
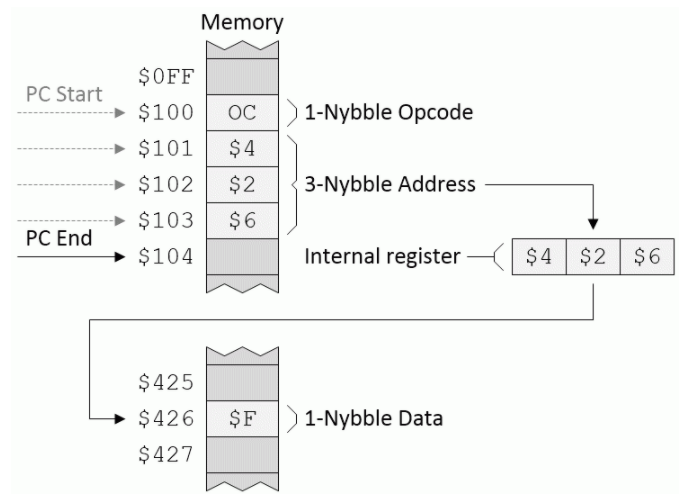
绝对寻址模式(来源:Max Maxfield)
假设程序计数器(PC)从地址$ 100开始,CPU读取操作码,意识到该操作码使用绝对模式,然后将以下三个字节(在本示例中为$ 426)加载到内部寄存器中。然后,CPU使用此内部寄存器的内容指向内存中的数据寄存器(在此示例中为$ F),并将其装入Q寄存器。我们最终将PC指向地址$ 104,这是CPU期望在程序中找到下一个操作码的位置。
与我们虚构的LDQ指令相反,假设我们的地址为$ 100的操作码指示CPU使用绝对寻址模式执行无条件的JMP。在这种情况下,CPU将跳转(设置PC)以寻址$ 426。
间接的:这是开始变得有趣的地方。假设我们有一个名为Q的寄存器和一个称为LDQ的指令,其目的是使用间接寻址模式将一小部分数据加载到寄存器Q中,如下所示:
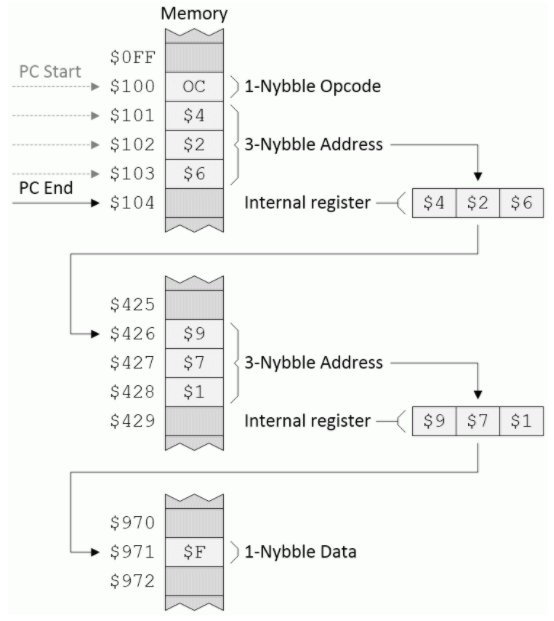
间接寻址模式(来源:Max Maxfield)
至于绝对模式,操作码后面的三个字节包含一个地址,该地址被加载到内部寄存器中。但是,在这种情况下,该地址并不直接指向数据,而是指向另一个3位地址的第一个地址,而该第二个地址用于指向数据。
与我们想象中的LDQ指令相反,假设我们的地址为$ 100的操作码指示CPU使用间接寻址模式执行无条件的JMP。在这种情况下,CPU最终将跳转(设置PC)以寻址$ 971。
索引(也称为绝对索引):此模式与绝对模式非常相似,不同之处在于它还涉及索引(X)寄存器。假设我们有一个名为Q的寄存器和一个称为LDQ的指令,其目的是使用索引寻址模式将一小部分数据加载到寄存器Q中,如下所示:
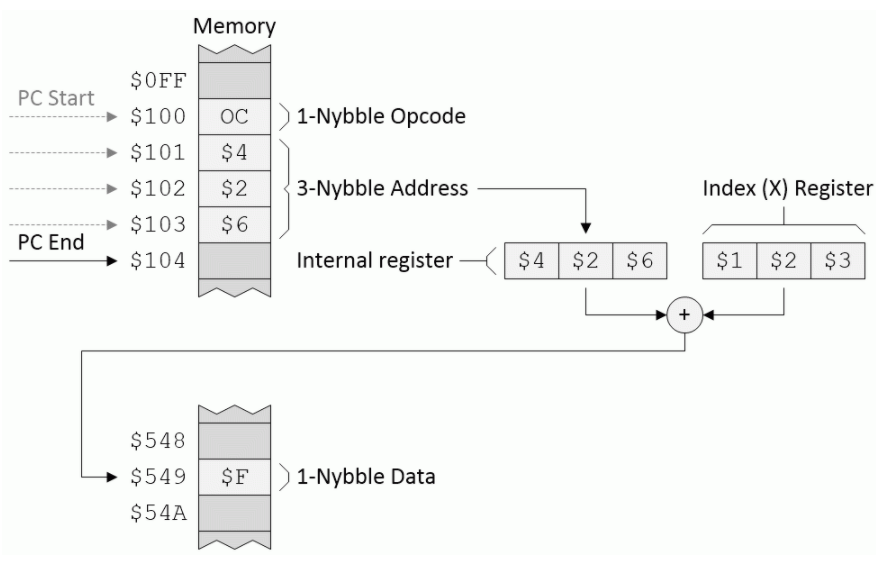
索引寻址模式(来源:Max Maxfield)
假设程序计数器(PC)从地址$ 100开始,CPU读取操作码,意识到此操作码使用索引模式,然后将以下三个字节(在本示例中为$ 426)加载到内部寄存器中。然后,CPU将此内部寄存器的内容添加到索引(X)寄存器的内容中,并使用结果指向内存中的数据缓冲区(在此示例中为$ F),并将其装入Q寄存器。我们最终将PC指向地址$ 104,这是CPU期望在程序中找到下一个操作码的位置。
与我们想象中的LDQ指令相反,假设我们的地址为$ 100的操作码指示CPU使用索引寻址模式执行无条件的JMP。在这种情况下,CPU最终将跳转(设置PC)以寻址549美元。
索引间接:此模式反映了索引模式和间接模式的一种可能组合。假设我们有一个名为Q的寄存器和一个称为LDQ的指令,其目的是使用索引间接寻址模式将一小部分数据加载到寄存器Q中,如下所示:
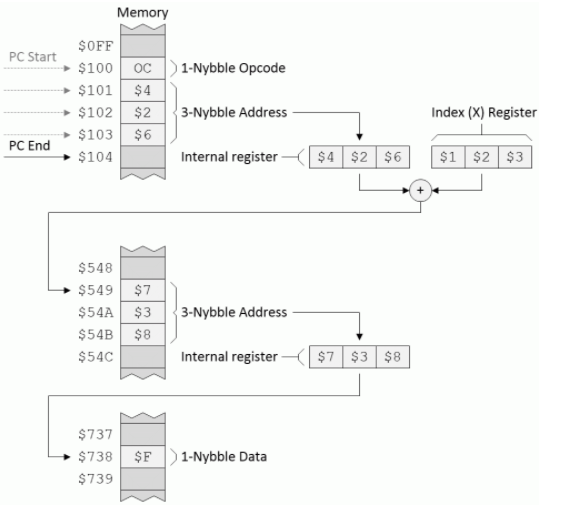
索引间接寻址模式(来源:Max Maxfield)
假定程序计数器(PC)从地址$ 100开始,CPU读取操作码,意识到此操作码使用索引间接模式,并将以下三个字节(在本示例中为$ 426)加载到内部寄存器中。然后,CPU将此内部寄存器的内容添加到索引(X)寄存器的内容中,以生成一个新地址。但是,在这种情况下,新地址不会直接指向数据,而是指向另一个3位地址的第一个地址,而这个第二地址用于指向将要加载到数据中的数据。 Q寄存器。
与我们虚构的LDQ指令相反,假设我们的地址为$ 100的操作码指示CPU使用索引间接寻址模式执行无条件JMP。在这种情况下,CPU最终将跳转(设置PC)以解决$ 738。
间接索引:此模式反映了索引模式和间接模式的替代组合。假设我们有一个名为Q的寄存器和一个称为LDQ的指令,其目的是使用间接索引寻址模式将一小部分数据加载到寄存器Q中,如下所示:
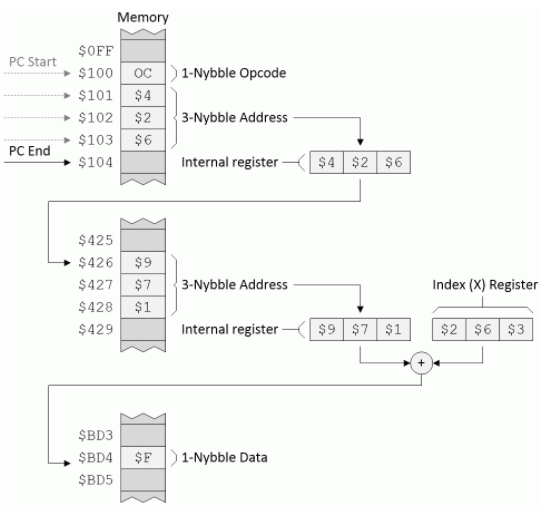
间接索引寻址模式(来源:Max Maxfield)
假定程序计数器(PC)从地址$ 100开始,CPU读取操作码,意识到此操作码使用间接索引模式,并将以下三个字节(在本示例中为$ 426)加载到内部寄存器中。该地址指向另一个3位地址的第一个地址,该地址本身被复制到内部寄存器中。然后,CPU将第二个内部寄存器的内容添加到索引(X)寄存器的内容中,以生成一个新地址,该地址指向将要加载到Q寄存器中的数据。
与我们想象中的LDQ指令相反,假设我们的地址为$ 100的操作码指示CPU使用间接索引寻址模式执行无条件的JMP。在这种情况下,CPU最终将跳转(设置PC)以寻址$ BD4。
自动递增和自动递减:除了上面讨论的基本索引模式外,某些CPU还支持自动递增和自动递减版本,其中将索引寄存器的内容添加到临时寄存器中的地址之后,递增或递减索引寄存器。
实际上,由于增量/减量是在添加之后进行的,因此应将这些模式更恰当地称为“自动后增量”和“自动后减量”。这是因为某些处理器还支持“预自动递增”和“预自动递减”,其中在将索引寄存器的内容添加到临时寄存器的地址之前,对索引寄存器进行递增或递减操作。
还要注意,自动递增和自动递减的所有四种形式都可以潜在地应用于索引间接和间接索引模式。
我的天啊!真的吗?
我知道,当我们考虑上述所有可能的寻址模式时,有很多事情需要解决。不要惊慌!HRRG仅支持这些模式的子集,而这是最简单的模式,即隐式,立即,绝对和索引模式。
另一方面,我们设计HRRG的方式意味着它有时在同一条指令中使用多种模式。我能说什么 这是一个有趣的旧世界。
编辑:hfy
- 相关推荐
- 热点推荐
- 寄存器
-
汇编指令是什么 计算机语言汇编指令简介2023-12-13 2766
-
构建 4 位计算机:汇编语言和汇编器(第 1 部分)2022-08-01 1716
-
[从零学习汇编语言] - 计算机中的硬件与软件2021-12-31 820
-
汇编语言是什么?怎样去学习汇编语言呢2021-11-29 1579
-
什么是汇编语言2021-07-19 1855
-
全面解析构建4位计算机:汇编语言和汇编器2021-05-13 3869
-
计算机的机器语言和汇编语言与高级语言的详细资料介绍2020-02-06 7151
-
计算机学习教程之指令系统与汇编语言程序设计课件免费下载2020-01-03 1322
-
计算机语言的分类2018-12-27 27945
-
微机原理汇编语言接口技术2015-12-31 906
-
计算机组成原理与汇编语言习题一2010-04-15 798
-
32位微型计算机原理与接口技术 (pdf电子书下载)2009-05-03 61347
-
计算机组成原理与汇编语言程序设计2008-10-21 922
全部0条评论

快来发表一下你的评论吧 !
