

技术革新,GCU-LARE实现高性能互联
描述
2020年10月26日,燧原科技正式推出搭载燧原科技云燧T10的PCIe Gen4全互联AI高算力训练系统。该系统目前为国内第一套基于PCIe Gen4的全互联AI高算力训练系统,不仅使配备云燧T10的机内PCIe带宽得以全面提升,同时结合燧原科技GCU-LARE技术可实现系统高性能互联。
Supermicro 4U A+ 服务器(搭载8张云燧T10)
技术革新,GCU-LARE实现高性能互联
PCIe Gen4全互联AI高算力训练系统由燧原科技与Supermicro合作研发,其中,燧原科技云燧系列产品PCIe Gen4的高带宽和GCU-LARE智能互联特点,在此研发中发挥了关键作用。
以该系统的创新技术——GCU-LARE来说,燧原科技GCU-LARE智能互联技术为系统提供了最大提供双向200GB/s的互联带宽。在2D Torus 6x6节点连接方式中,若采用GCU-LARE互联,一个机柜内3台8卡服务器,垂直方向环6个节点,水平方向用2张RDMA/RoCE网卡,通过类似可扩展的连接方式,可以实现千卡级别高线性度互联,其线性加速比可达86%以上,远超业内水平,故而实现其高性能互联特色。
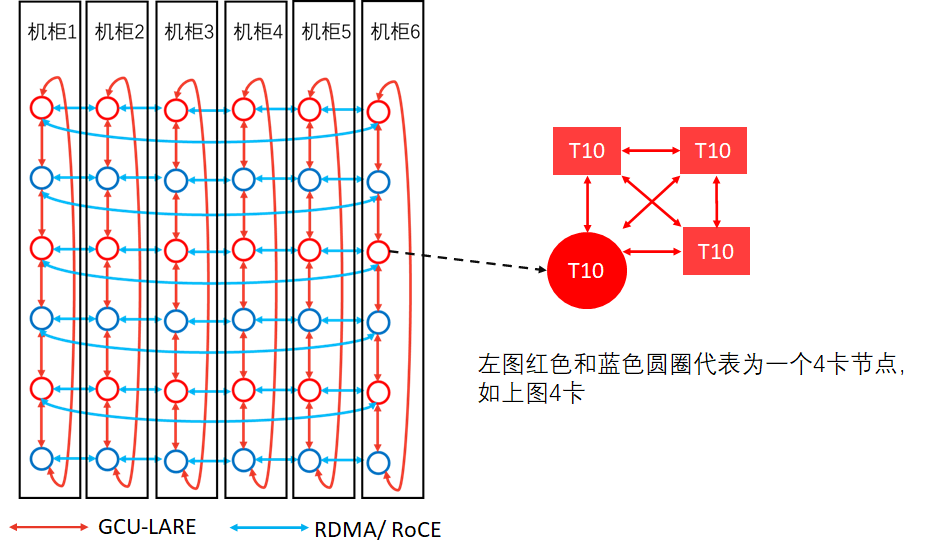
2D Torus 6x6节点示意图(144张云燧T10)
精准攻克,强强联手解决算力瓶颈
燧原科技产品部资深总监邓辉表示,随着AI模型的复杂化和大型化,AI算力需求成指数级增长。其中,运算集群和CPU的通信带宽,以及运算加速卡节点之间scale out时的高性能、低延迟、智能化互联成为高算力集群的瓶颈。
此次燧原科技正式推出的PCIe Gen4全互联AI高算力训练系统,便着重解决通信带宽与运算加速卡节点之间的高性能、低延迟、智能化互联问题。
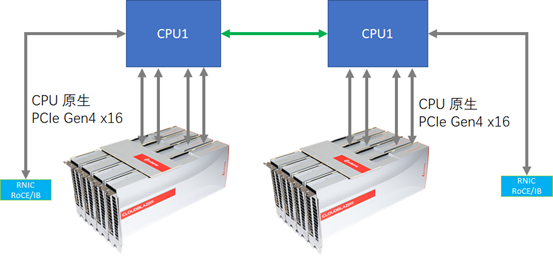
PCIe Gen4连接拓扑
燧原科技通过直接连接PCIe Gen4 x16 CPU至云燧T10,使得Supermicro新的4U A+ Server 4124GS-TNR系统支持最多可8张云燧T10 PCIe AI加速卡,而单机8张云燧T10支持4卡作为一个节点的HCM(HybridCube Mesh)互联拓扑,节点内通过GCU-LARE桥接卡实现4卡间点对点全互联,节点之间通过GCU-LARE高速线缆实现互联,总互联带宽高达800GB/s。最终,该系统无需任何PCIe Switch,便可实现最低延迟、最高带宽和最大限度的加速。

GCU-LARE互联HCM拓扑(单机8卡)
此外,该系统还支持最多两个额外高性能PCIe Gen4扩展槽,且支持单个PCIe Gen4 x8以及最多2个用于RDMA高速网卡提供最高200Gb/s的高性能网络连接,用于实现最先进的2D Torus的高性能AI训练集群互联拓扑。
多方攻克,具有强大算力与超高加速的PCIe Gen4全互联AI高算力训练系统搭载燧原科技云燧T10,应运而生。该系统加速了计算和网络性能,极大的丰富和提升了整个AI高算力训练系统互联拓扑和带宽,为客户带来强大的产品性能和可扩展性,使其拥有前所未有的速度为最复杂的Al网络进行训练。
系统落地,彰显训练芯片实力
燧原科技正是认可Supermicro在全球企业服务器先进解决方案上的突出地位,并与其创新性、革命性的研发特理念不谋而合,故而凭借其独创的GCU-LARE互联技术与Supermicro展开合作,成功地推出了中国第一套PCIe Gen4的多卡AI服务器训练系统,解决了大型AI训练系统互联接口的瓶颈和规模部署的门槛。此次合作的成功还为双方后期深入合作奠定了良好基础,让未来更多基于多卡互联的AI模型训练系统逐一实现。
对于燧原科技而言,这款搭载云燧T10的中国第一套PCIe Gen4全互联AI高算力训练系统成功推出,是对其研发方向的极致肯定,同时也彰显了燧原科技在训练芯片领域的技术实力与企业地位。
燧原科技创始人兼COO张亚林认为,能与全球企业服务器先进解决方案的倡导者和领先者Supermicro保持前瞻性技术上的一致,并展开深入合作,最后成功落地合作成果,是燧原科技走向国际舞台的标志性一步,代表我国训练芯片行业曙光在即,前景远大。
未来,AI训练芯片的算力需求将以每三个月增长一倍的惊人速度增长,而AI应用率到2025年将达80%。急速变化的AI训练芯片技术、产量需求为该领域企业带来了严峻考验,燧原科技必将全力践行其研发战略,全面攻克数据分析、深度学习和深度学习推理等多方难题,为真正的算力普惠和应用落地创造价值和铺平道路。
原文标题:燧原科技上线AI高算力训练系统PCIe Gen4
文章出处:【微信公众号:燧原科技Enflame】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
蓄电池放电技术革新:引领能源存储新时代2025-02-08 6076
-
TDK帮助机器人实现技术革新的传感器解决方案2020-07-09 2003
-
这年头充电电池套装也要技术革新2009-11-06 728
-
高性能DSP互联方法2017-10-20 911
-
快速发展的无线标准以及如何应对技术革新者们面临的困境2017-11-17 1360
-
TFT液晶制造制程技术革新讲解2018-09-26 7492
-
AI是传媒生产力提升的一次技术革新2018-12-03 1313
-
探析5G时代的技术革新挑战2018-12-04 6015
-
国产深海1万米六维力传感器引领卡脖子技术革新2024-02-20 2224
-
天马微电子荣获阿尔卑斯阿尔派2023年度“技术革新奖”2024-05-29 1864
-
甬矽电子高密度SiP技术革新5G射频模组2024-05-31 1866
-
iPhone 16 Pro电池技术革新:不锈钢外壳引领续航新飞跃2024-08-07 3276
-
汽车车架焊接技术革新与应用前景2025-02-21 1122
-
耐能KNEO Pi开发板的三大技术革新2025-06-06 1461
-
国产时钟缓冲器:技术革新与市场竞争2025-11-18 6476
全部0条评论

快来发表一下你的评论吧 !
