

预训练语言模型设计的理论化认识
描述
在这篇文章中,我会介绍一篇最新的预训练语言模型的论文,出自MASS的同一作者。这篇文章的亮点是:将两种经典的预训练语言模型(MaskedLanguage Model, Permuted Language Model)统一到一个框架中,并且基于它们的优势和缺点,取长补短,提出了一个新的预训练语言模型----MPNet,其混合了MLM和PLM各自的优势,达到了比两者更好的效果,在Natural Language Understanding和NaturalLanguageGeneration任务中,都取得了较好的结果。实验表明MPNet在大量下游任务中超越了MLM和PLM,从而证明了pretrain方法中的2个关键点:
被预测的token之间的依赖关系 (MPNet vs MLM)
整个序列的位置信息 (MPNet vs PLM)
MPNet: Masked and Permuted Pre-training for Language Understanding(https://arxiv.org/pdf/2004.09297.pdf)
【小小说】这篇论文我很喜欢,读下来有一种打通了任督二脉一般行云流水的感觉。在本文中,我会从BERT和XLNet的统一理论框架讲起,然后引出作者如何得到MPNet这一训练方式,接着会介绍一下作者具体实现上用到的方法。希望本文可以让你对预训练语言模型的设计有一个更加理论化的认识。
1. BERT和XLNet各自的优缺点
❝既然是从BERT和XLNet到MPNet,那么当然是要先从这两者讲起。大家对BERT应该比较熟悉,它是划时代的工作,可以说从BERT开始,NLP领域正式进入了“预训练模型”的时代。而XLNet是随后的重磅之作,在这一节中,我们先来回顾一下它们。❞
「BERT」: Masked Language Model , 使用了双边的context信息,但是忽略了masked token之间的依赖关系
「XLNet」: Permuted Language Model , 保留了masked token之间的依赖关系,但是预测的时候每个token只能看到permuted sequence中的前置位的token的信息,不能看到所有token的信息。(p.s. 不知道XLNet的宝宝辛苦去复习 【论文串讲】从GPT和BERT到XLNet )
作者分别从input和output两个角度总结了两者的优缺点分别存在的地方:
「Input Discrepancy」: 在Natural Language Understanding的任务中,模型可以见到完整的input sentence,因此要求在预训练阶段,input要尽可能输入完整的信息
MLM中,token的语言信息是不完整的,不过位置信息是保留的(通过position embedding,p.s. 想具体了解如何通过position embedding保留的,请移步参考 【经典精读】Transformer模型深度解读 中"使用Positional Encoding带来的独特优势"这部分的内容)
PLM中,每个被预测的token只能“看”到被打乱的序列中位于它自己前面的token,而不能像MLM一样“看”到两侧的token。
「Output Dependency」:
MLM中,输出的token,即在input端被mask掉的token,是「互相独立的」。也就是说这些被mask掉的token之间是假定没有context层面的关系的。
PLM规避了MLM中的问题,被预测的token之间也存在context层面的关系。
「总结一下就是:」
❝「PLM在output dependency的问题上处理得比MLM好,但是预训练阶段和fine-tune阶段之间的差异比MLM的更大。」❞
2. 统一MLM和PLM的优化目标
❝了解了BERT和XLNet各自的优缺点和适用的场景后,本文的作者试图从一个统一的视角去总结这两种预训练模型,而这个总结,引出了后来的MPNet。❞
基于以上两点观察,本文的作者提出了统一Masked Language Model和Permuted Language Model的想法,并且起名叫「M」asked and「P」ermuted Language Model,缩写「MPNet」,意在取两者之长,避两者之短。
2.1. 统一优化目标的提出
MLM: 由于Masked Language Model中的独立性假设“每个被mask的位置的token之间是彼此独立的”,我们可以换一种方式看待Masked Language Model: 把Masked tokens统一挪到序列的末尾,这样做并不会改变模型的任何部分,只是我们的看待方式变了。
重新看待Masked Language Model
2. PLM: 原顺序 被打乱成
,然后最右边的两个token 和 就被选作要预测的token。
重新看待Permuted Language Model
基于上述的讨论,作者给出了统一MLM和PLM训练目标的框架:将没有被mask的token放在左边,而将需要被预测的token(被mask掉的)放在右边。
「MLM」

「PLM」
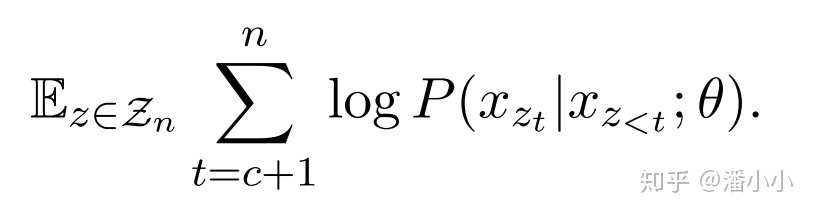
其中,是序列的其中一个permutation,表示在该permutation中的第 位,表示位置小于的所有位置。
2.2. 讨论
MLM和PLM的训练目标公式非常接近,唯一的区别在于,MLM条件概率的条件部分是 和 ; 而PLM的条件部分是,它们的区别是:
MLM比PLM多了 这个条件,也就是比PLM多了关于序列长度的信息(一个[M]就是一个位置)。
PLM比MLM多了被预测部分token之间的相关性:PLM的 是随着预测的进行(t的变化)而动态变化的,MLM的 对于整个模型预测过程进行是恒定不变的。
3. 提出MPNet
❝
基于上一节的总结,作者按照相同的思路提出了MPNet的预训练目标
❞
「a. MPNet的预训练目标」
我们既要像MLM那样,在预测时获取到序列长度的信息;又要像PLM那样,在预测后一个token时,以前面的所有token(包含前置位被预测出来的)为条件。MPNet做到了:
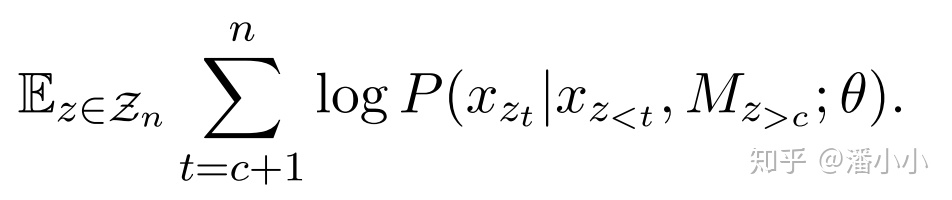
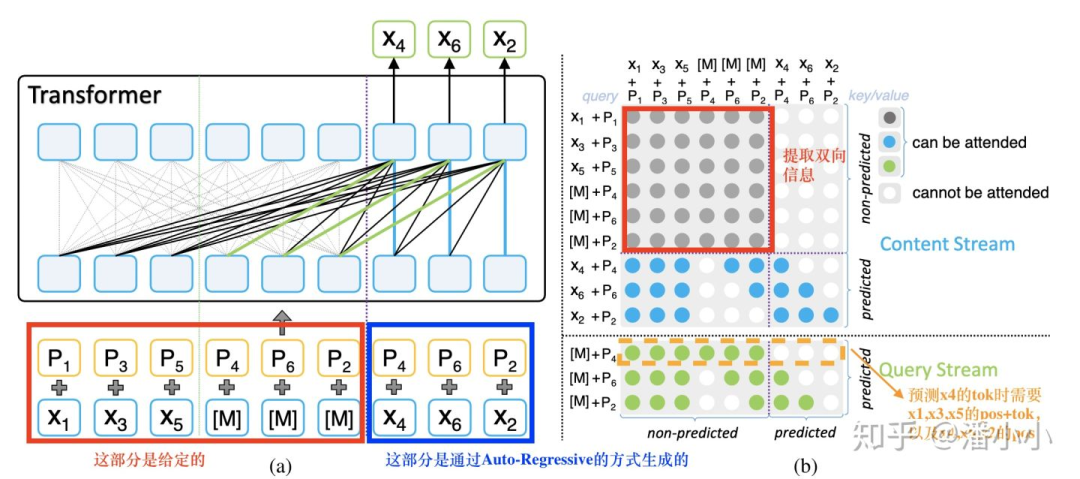
MPNet示意图
(b)图中灰色的部分是encoder端的bidirectional self-attention
(b)图中蓝色和绿色的部分分别是decoder端的two stream self-attention的content stream和query stream (two stream self-attention的具体定义请参考 【论文串讲】从GPT和BERT到XLNet ),这里提一下,content stream相当于query stream右移一步。
(a)图中黑色的线+绿色的线即对应了(b)图中的绿色点,(a)图中黑色的线+蓝色的线即对应了(b)图中的蓝色点。
(b)图中的行对应着query position,列对应着column position。
「b. ”位置补偿“」
由于用到了Permuted Language Model的思想,所以MPNet和XLNet一样,也要使用two-stream self-attention。想要实现预训练目标中的 ,在实现上作者提出了“位置补偿”(positioncompensation),也就是说,在预测过程的每一步,query stream和contentstream都可以看到N(N即序列长度)个token,具体结合图中的例子来说就是,
预测 时: 已知 , , , , , , , ,
预测 时: 已知 , , , , , , , , ,
预测 时: 已知 , , , , , , , , , ,
也就是说,无论预测到哪一步, , ,
, , , 这6个位置信息都可见。我们回顾一下XLNet,作一下对比:
预测 时: 已知 , , , , , ,
预测 时: 已知 , , , , , , , ,
预测 时: 已知 , , , , , , , , , ,
可以看出,在预测 时,比MPNet少了 , ,在预测 时,比MPNet少了 。
「c. 总结」

MPNet有效性来自于它保留了更多的信息
通过上面的详细讲解,相信到这儿大家也明白了:MPNet保留的信息是BERT和XLNet的并集,第一,它利用PLM的自回归特性,规避了MLM的独立性假设,在预测后面token时也利用了之前预测出来的token;第二,它利用MLM建模中自带的序列信息,规避了PLM在预测前面的token时不知道序列整体的长度的缺点。这两点保证了MPNet完美扬长避短,因此在下游任务中完美击败了前两者。
给我们的启发
致力于弥合pre-train阶段和下游任务fine-tune阶段的预训练目标,尽可能减少训练和预测过程中信息的损失,是研究预训练模型的重中之重,也是预训练模型领域整体的发展方向。读预训练系列论文的时候一定要抓住这个核心线索去读。
责任编辑:xj
原文标题:【论文串讲】从BERT和XLNet到MPNet
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
-
名单公布!【书籍评测活动NO.30】大规模语言模型:从理论到实践2024-03-11 16190
-
【大语言模型:原理与工程实践】大语言模型的预训练2024-05-07 1597
-
如何向大规模预训练语言模型中融入知识?2021-06-23 6415
-
一文详解知识增强的语言预训练模型2022-04-02 11199
-
Multilingual多语言预训练语言模型的套路2022-05-05 4469
-
一种基于乱序语言模型的预训练模型-PERT2022-05-10 2722
-
如何更高效地使用预训练语言模型2022-07-08 2179
-
利用视觉语言模型对检测器进行预训练2022-08-08 2545
-
预训练语言模型的字典描述2022-08-11 2017
-
CogBERT:脑认知指导的预训练语言模型2022-11-03 2055
-
预训练数据大小对于预训练模型的影响2023-03-03 2730
-
什么是预训练 AI 模型?2023-04-04 2835
-
什么是预训练AI模型?2023-05-25 2288
-
预训练模型的基本原理和应用2024-07-03 6159
-
大语言模型的预训练2024-07-11 2037
全部0条评论

快来发表一下你的评论吧 !
