

自监督学习与Transformer相关论文
描述
导读
国际表示学习大会(TheInternationalConference onLearningRepresentations)是致力于人工智能领域发展的国际知名学术会议之一。ICLR 2021 将在明年5月4日举行,目前,本次大会投稿已经结束,最后共有3013篇论文提交。ICLR 采用公开评审机制,任何人都可以提前看到这些论文。
为了分析最新研究动向,我们精选了涵盖自监督学习、Transformer、图神经网络、自然语言处理、模型压缩等热点领域,将分多期为大家带来系列论文解读。
本期的关注焦点是自监督学习与Transformer。
自监督学习
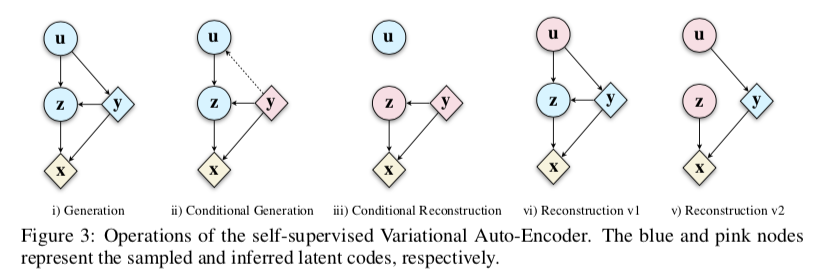
Self-Supervised Variational Auto-Encoders
变分自编码器(VAE)往往通过假设先验分布为高斯分布来简化计算过程,实际上真实数据的分布往往较为复杂,该假设会导致模型的过正则化并影响模型对真实分布的拟合能力;本文通过利用多个简单分布对复杂真实分布进行建模,并采用自监督方法对这些分布之间进行约束,进而提升VAE模型最终的效果。
论文链接:https://openreview.net/forum?id=zOGdf9K8aC
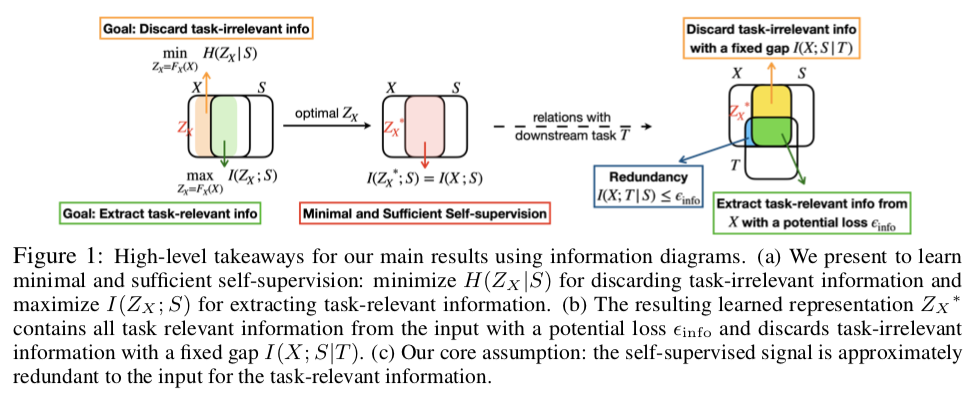
Self-Supervised Learning from a Multi-View Perspective
即使自监督学习已经取得了很好的效果,现有的方法依旧并不清楚自监督学习带来增益的主要原因;本文基于信息空间的考虑,认为自监督学习通过减少不相关信息来帮助收敛;此外本文还提出将自监督任务的两个经典方法——对比学习和预测学习任务进行合并,结合两者优点以增强自监督学习的效果。
论文链接:https://openreview.net/forum?id=-bdp_8Itjwp
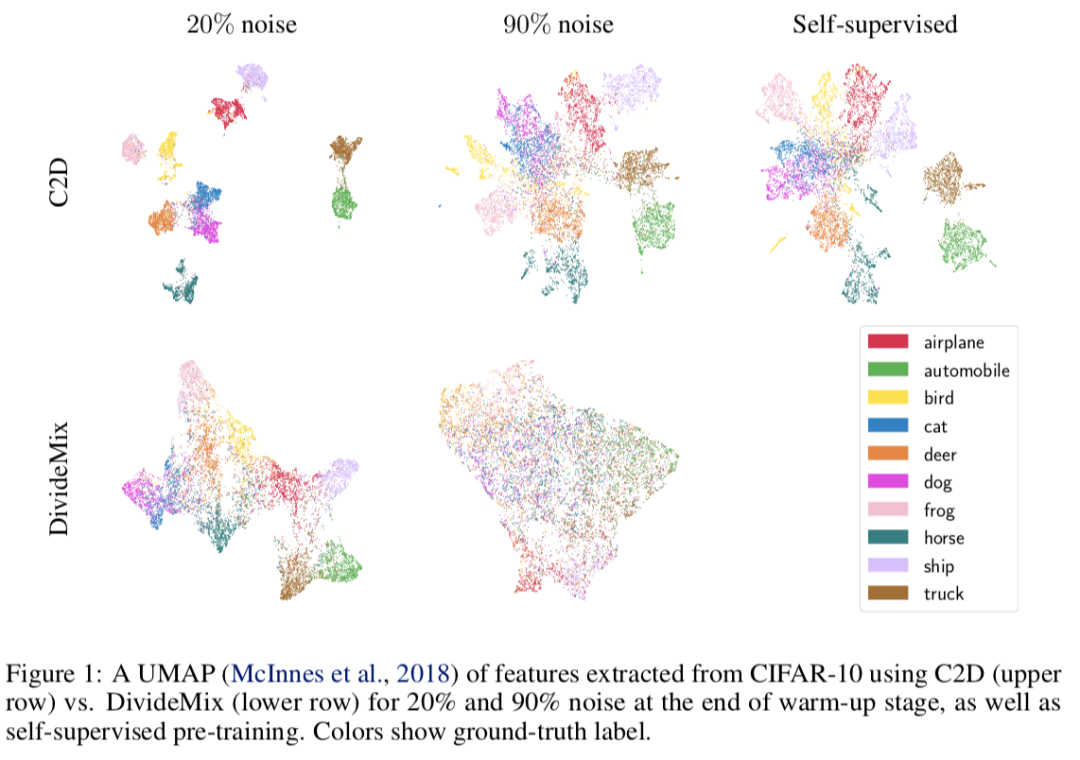
Contrast to Divide: Self-Supervised Pre-Training for Learning with Noisy Labels
现有的噪声数据学习策略往往基于loss的噪声识别与再过滤的框架,其需要模型在warm-up阶段既能学习到足够好的特征信息,同时不至于过分拟合噪声数据的分布;改目的与对比学习任务非常契合,本文提出在warm-up阶段采用对比学习帮助进行特征学习,并基于对比学习策略帮助区分噪声数据。
论文链接:https://openreview.net/forum?id=uB5x7Y2qsFR
Improving Self-Supervised Pre-Training via a Fully-Explored Masked Language Model
现有的BERT等模型往往采用masked language model进行自监督学习,但是其往往采用随机的方法确定mask的word或者span;本文提出不合适的mask会导致梯度方差变大,并影响模型的效果,并分析原因在于同时mask的word之间具有一定的相似度;故本文提出一种特殊的mask机制,其考虑增大被mask的word之间的差异,进而削弱梯度方差大带来的影响。

论文链接:https://openreview.net/forum?id=cYr2OPNyTz7
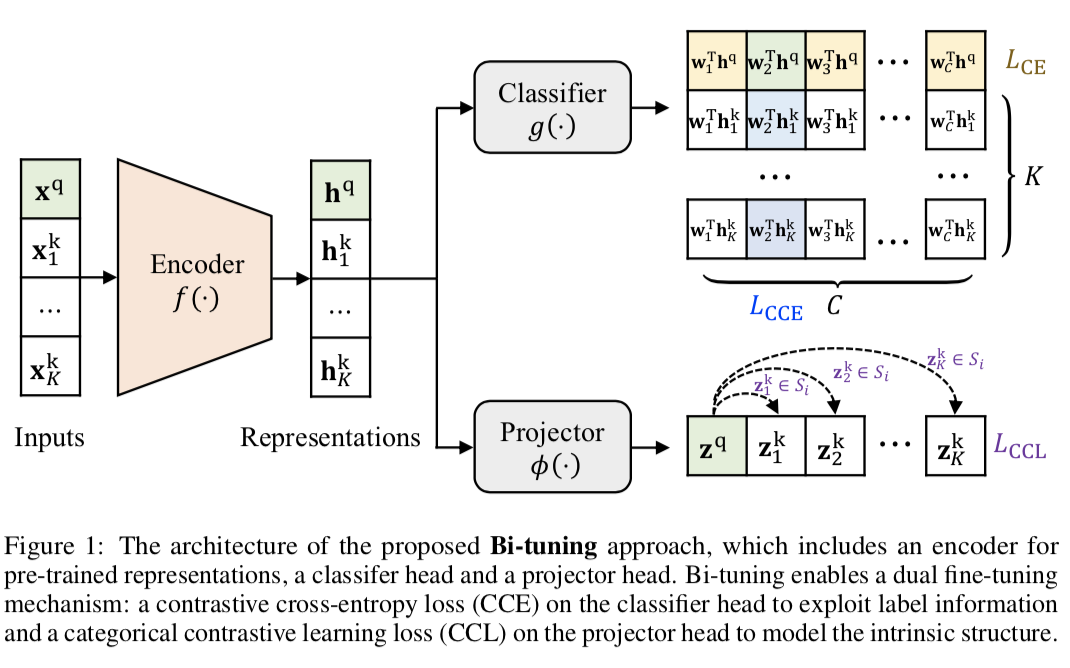
Bi-Tuning of Pre-Trained Representations
随着预训练模型的快速发展,现有方法主要关注于如何进行pre-train,但是很少关注如何进行fine-tune;本文认为在fine-tune时模型很容易忘记预训练的信息并过拟合到当前任务,因此提出了一种特殊的Bi-tune策略,即利用对比学习作为正则项约束模型的收敛情况,进而帮助提升模型的效果。
论文链接:https://openreview.net/forum?id=3rRgu7OGgBI
Erasure for Advancing: Dynamic Self-Supervised Learning for Commonsense Reasoning
为了解决预训练模型很难学习到更精准的 question-clue pairs 问题,本文提出DynamIcSelf-sUperviSedErasure (DISUSE)。其中包含 erasure sampler 和 supervisor,分别用于擦出上下文和问题中的多余线索,以及使用 self-supervised manner 进行监督。
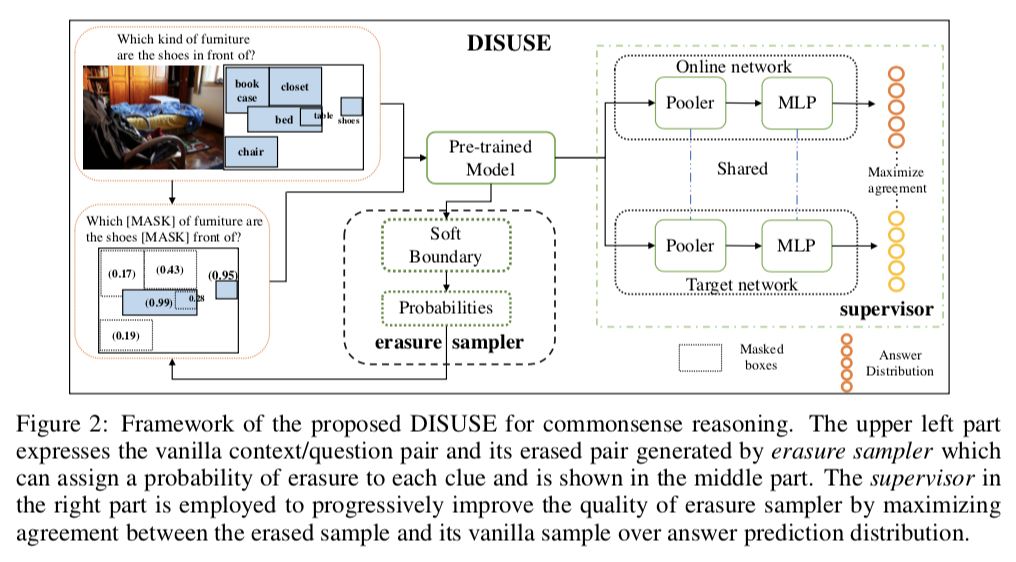
论文链接:https://openreview.net/forum?id=WfY0jNndSn3
Transformer
Addressing Some Limitations of Transformers with Feedback Memory
Transformer结构因其并行计算的特性有很高的计算效率,但是这种特性限制了Transformer发掘序列信息的能力,这体现在底层表示无法获得高层表示信息。作者提出一种Feedback Memory结构,将所有历史的底层和高层表示信息传递给未来表示。
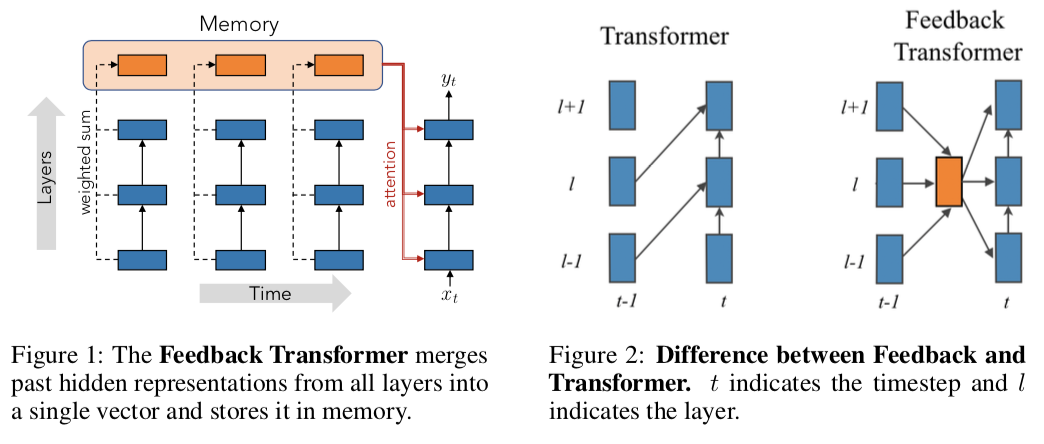
论文链接:https://openreview.net/forum?id=OCm0rwa1lx1
Not All Memories are Created Equal: Learning to Expire
Attention机制往往需要长期的记忆,但是实际上并不是所有历史信息都是重要的。因此,作者提出一种Expire-Span机制,动态地决定每一个时刻信息存活的时间长短,从而减少模型进行Attention操作耗费的空间开销。
论文链接:https://openreview.net/forum?id=ZVBtN6B_6i7
Memformer: The Memory-Augmented Transformer
目前大部分Transformer变体模型在处理长序列时都会存在效率问题。作者提出一种利用Memory机制来编码和保存历史信息,使得时间复杂度下降到线性时间,空间复杂度变为常数。
论文链接:https://openreview.net/forum?id=_adSMszz_g9
Non-iterative Parallel Text Generation via Glancing Transformer
本文提出了一种基于 glancing language model 的 Glancing Transformer,通过 one-iteration 的生成方式提升 NAT 的性能。其中 Glancing language model,可以通过两次 decoding 来降低学习难度以及加快生成速度。另外这种方法同样可以应用于其他基于 NAT 的任务。
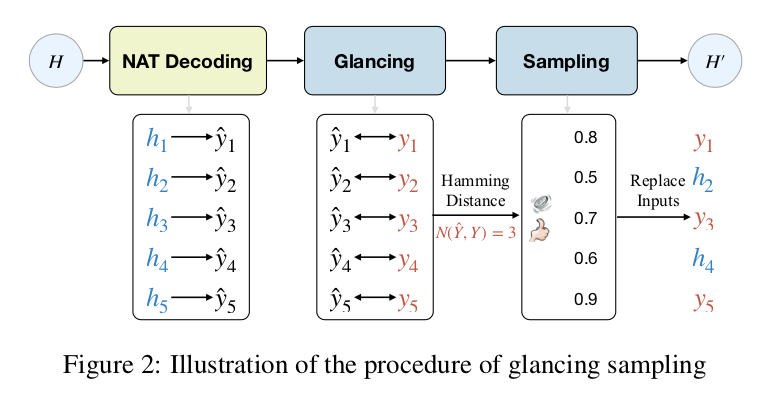
论文链接:https://openreview.net/forum?id=ZaYZfu8pT_N
责任编辑:xj
原文标题:【ICLR2021必读】 【自监督学习】 & 【Transformer】相关论文
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
- 相关推荐
- 热点推荐
- 人工智能
- 深度学习
- Transformer
-
使用MATLAB进行无监督学习2025-05-16 1747
-
基于transformer和自监督学习的路面异常检测方法分享2023-12-06 3258
-
适用于任意数据模态的自监督学习数据增强技术2023-09-04 1998
-
自监督学习的一些思考2022-01-26 613
-
机器学习中的无监督学习应用在哪些领域2022-01-20 5646
-
基于人工智能的自监督学习详解2021-03-30 7142
-
半监督学习:比监督学习做的更好2020-12-08 2302
-
为什么半监督学习是机器学习的未来?2020-11-27 4790
-
最基础的半监督学习2020-11-02 3517
-
机器学习算法中有监督和无监督学习的区别2020-07-07 6821
-
如何用Python进行无监督学习2019-01-21 5435
-
你想要的机器学习课程笔记在这:主要讨论监督学习和无监督学习2018-12-03 1013
-
基于半监督学习框架的识别算法2018-01-21 1081
-
基于半监督学习的跌倒检测系统设计_李仲年2017-03-19 1047
全部0条评论

快来发表一下你的评论吧 !
