

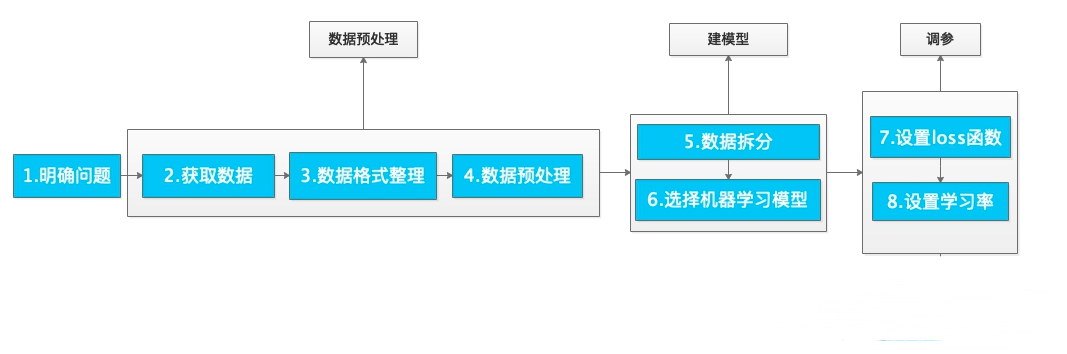
机器学习过程中的通用步骤
人工智能
描述
我们在进行机器学习过程中一个通用步骤主要有以下几个方面:
1)明确问题
实现什么目标
需要什么数据 这个问题:如果公司有大量的数据,可以确定最终的目标是什么;如果没有则需要通过目标来确定数据集
2)获取数据
自己公司内部的数据(项目上使用),如数据库等
开源数据集,如:UCI、GoogleTrends、Kaggle、AWS公用数据集、Imagenet、MINIST、麻省理工大学人脸识别、歌曲数据库、图像处理COCO、视频数据集youtube等等
3)数据格式整理
往往我们的数据大多都是数据库文件数据,并不是里面所有的维度信息都是需要用到的,所以这里需要进行相应的处理。
把收集到的数据转换为txt,csv,xsl等的形式,方便机器学习库进行读取
原始数据的所有的变量量化,进一步转变为含数据(Data)和标签(Labels)的数据框形式,方便建模。
4)数据预处理
偏差检测:即检查导致偏差的因素,并识别离散值与噪声值。
数据清洗:即处理缺失值与噪声。
数据标准化
5)数据拆分
将数据集随机打乱按照7:3或者8比2或者其他拆分为训练集和测试集。
6)根据场景采用不同的合适机器学习模型
考虑因素:
数据的维度大小,数据的质量和数据的特征属性;
可以利用的计算资源;
所在的项目组对该项目的时间预计;
手上的数据能应用在哪些项目中;
选择的依据如果要进行降维操作,那么你可以使用主成分分析方法(PCA);
如果要快速进行手写数字预测,那么你可以使用决策树或者逻辑回归;
如果要进行数据分层操作,那么你可以使用分层聚类。
7)设置损失函数loss
0-1损失函数 也就是说,当预测错误时,损失函数为1,当预测正确时,损失函数值为0。该损失函数不考虑预测值和真实值的误差程度。只要错误,就是1。
平方损失函数 是指预测值与实际值差的平方。
绝对值损失函数 该损失函数的意义和上面差不多,只不过是取了绝对值而不是求绝对值,差距不会被平方放大。
对数损失函数
Hinge loss
8) 设置学习率
对于不同大小的数据集,调节不同的学习率
在每次迭代中调节不同的学习率
9)测试,检验
综上整个大致流程如图所示:
责任编辑人:CC
-
机器学习模型评估指标2023-09-06 2283
-
你是否在学习STM32的过程中很迷茫2016-06-08 4275
-
在学习tensorflow过程中遇到的问题有哪些2020-05-25 1198
-
影响制造过程中的PCB设计步骤2020-10-27 3167
-
学习单片机过程中对编译原理的学习理解 精选资料推荐2021-07-14 896
-
学习MSP430过程中遇到的问题分享2021-11-29 1098
-
什么是机器学习? 机器学习基础入门2022-06-21 3055
-
反激式变压器设计过程中的重要步骤2023-09-28 737
-
Python机器学习开源项目分析过程中的见解和趋势2017-12-16 985
-
展示Python机器学习开源项目以及在分析过程中发现的非常有趣的见解和趋势2018-01-04 4873
-
电源研发的过程中的常见问题2020-09-05 3983
-
机器学习的基本过程及关键要素2020-11-12 13197
-
PCB组装过程中的步骤2020-11-17 8352
-
机器学习8大调参技巧2024-03-23 1658
-
eda在机器学习中的应用2024-11-13 1661
全部0条评论

快来发表一下你的评论吧 !
