

CPU对代码的识别和读取
描述
从底层硬件角度出发剖析了一下CPU对代码的识别和读取,内容之精彩,读完感觉学到的很多东西瞬间联系起来了,分享给大家。
先说一下半导体,啥叫半导体?就是介于导体和绝缘体中间的一种东西,比如二极管。
电流可以从A端流向C端,但反过来则不行。你可以把它理解成一种防止电流逆流的东西。
当C端10V,A端0V,二极管可以视为断开。
当C端0V,A端10V,二极管可以视为导线,结果就是A端的电流源源不断的流向C端,导致最后的结果就是A端=C端=10V。
等等,不是说好的C端0V,A端10V么?咋就变成结果是A端=C端=10V了?你可以把这个理解成初始状态,当最后稳定下来之后就会变成A端=C端=10V。
文科的童鞋们对不住了,实在不懂问高中物理老师吧。反正你不能理解的话就记住这种情况下它相当于导线就行了。
利用半导体的这个特性,我们可以制作一些有趣的电路,比如【与门】。
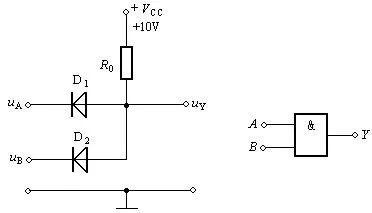
此时A端B端只要有一个是0V,那Y端就会和0V地方直接导通,导致Y端也变成0V。只有AB两端都是10V,Y和AB之间才没有电流流动,Y端也才是10V。
我们把这个装置成为【与门】,把有电压的地方计为1,0电压的地方计为0。至于具体几V电压,那不重要。也就是AB必须同时输入1,输出端Y才是1;AB有一个是0,输出端Y就是0。
其他还有【或门】【非门】和【异或门】,跟这个都差不多,或门就是输入有一个是1输出就是1,输入00则输入0。
非门也好理解,就是输入1输出0,输入0输出1。
异或门难理解一些,不过也就那么回事,输入01或者10则输出1,输入00或者11则输出0。(即输入两个一样的值则输出0,输入两个不一样的值则输出1)。
这几种门都可以用二极管或者三极管做出来,具体怎么做就不演示了,有兴趣的童鞋可以自己试试。当然实际并不是用二极管三极管做的,因为它们太费电了。实际是用场效应管(也叫MOS管)做的。
然后我们就可以用门电路来做CPU了。当然做CPU还是挺难的,我们先从简单的开始:加法器。加法器顾名思义,就是一种用来算加法的电路,最简单的就是下面这种。
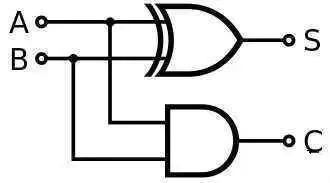
AB只能输入0或者1,也就是这个加法器能算0+0,1+0或者1+1。
输出端S是结果,而C则代表是不是发生进位了,二进制1+1=10嘛。这个时候C=1,S=0。
费了大半天的力气,算个1+1是不是特别有成就感?
那再进一步算个1+2吧(二进制01+10),然后我们就发现了一个新的问题:第二位需要处理第一位有可能进位的问题,所以我们还得设计一个全加法器。
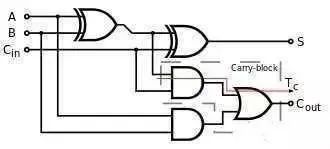
每次都这么画实在太麻烦了,我们简化一下。
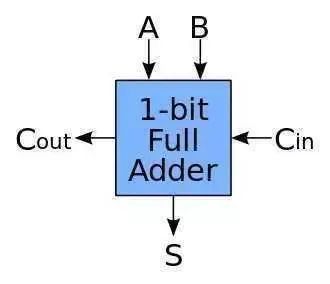
也就是有3个输入2个输出,分别输入要相加的两个数和上一位的进位,然后输入结果和是否进位。然后我们把这个全加法器串起来:
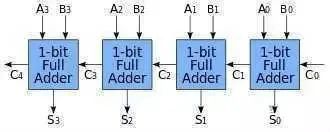
我们就有了一个4位加法器,可以计算4位数的加法也就是15+15,已经达到了幼儿园中班水平,是不是特别给力?
做完加法器我们再做个乘法器吧,当然乘任意10进制数是有点麻烦的,我们先做个乘2的吧。
乘2就很简单了,对于一个2进制数数我们在后面加个0就算是乘2了。比如:
5=101(2)
10=1010(2)
以我们只要把输入都往前移动一位,再在最低位上补个零就算是乘2了。具体逻辑电路图我就不画,你们知道咋回事就行了。
那乘3呢?简单,先位移一次(乘2)再加一次。乘5呢?先位移两次(乘4)再加一次。
所以一般简单的CPU是没有乘法的,而乘法则是通过位移和加算的组合来通过软件来实现的。这说的有点远了,我们还是继续做CPU吧。
现在假设你有8位加法器了,也有一个位移1位的模块了。串起来你就能算(A+B)×2了!激动人心,已经差不多到了准小学生水平。
那我要是想算A×2+B呢?简单,你把加法器模块和位移模块的接线改一下就行了,改成输入A先过位移模块,再进加法器就可以了。
你的意思是我改个程序还得重新接线?
所以你以为呢?
实际上,编程就是把线来回插啊。惊喜不惊喜?意外不意外?
早期的计算机就是这样编程的,几分钟就算完了但插线好几天。而且插线是个细致且需要耐心的工作,所以那个时候的程序员都是清一色的漂亮女孩子,穿制服的那种,就像照片上这样。是不是有种生不逢时的感觉?
插线也是个累死人的工作。所以我们需要改进一下,让CPU可以根据指令来相加或者乘2。这里再引入两个模块,一个叫flip-flop,简称FF,中文好像叫触发器,如下图这样。
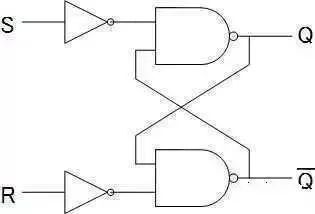
这个模块的作用是存储1bit数据。比如上面这个RS型的FF,R是Reset,输入1则清零。S是Set,输入1则保存1。RS都输入0的时候,会一直输出刚才保存的内容。
我们用FF来保存计算的中间数据(也可以是中间状态或者别的什么),1bit肯定是不够的,不过我们可以并联嘛,用4个或者8个来保存4位或者8位数据。这种我们称之为寄存器(Register)。另外一个叫MUX,中文叫选择器,如下图就是一个选择器。
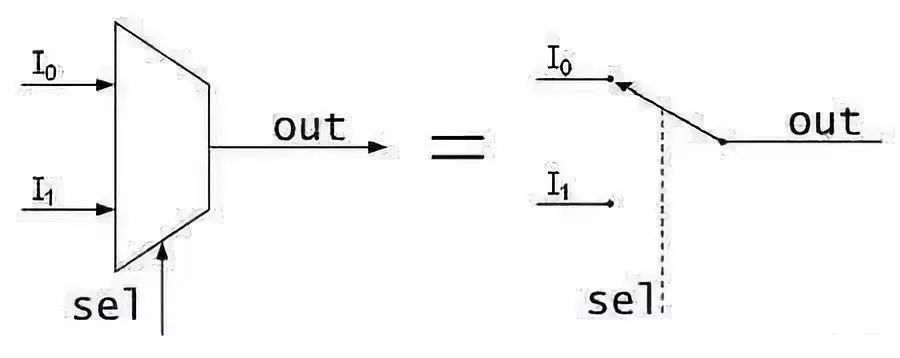
这个就简单了,sel输入0则输出i0的数据,i0是什么就输出什么,01皆可。同理sel如果输入1则输出i1的数据。当然选择器可以做的很长,比如这种四进一出的具体原理不细说了,其实看看逻辑图琢磨一下就懂了,知道有这个东西就行了。下图是一个四进一出-选择器。
有这个东西我们就可以给加法器和乘2模块(位移)设计一个激活针脚。
这个激活针脚输入1则激活这个模块,输入0则不激活。这样我们就可以控制数据是流入加法器还是位移模块了。
于是我们给CPU先设计8个输入针脚,4位指令,4位数据。
我们再设计3个指令:
0100,数据读入寄存器
0001,数据与寄存器相加,结果保存到寄存器
0010,寄存器数据向左位移一位(乘2)
为什么这么设计呢,刚才也说了,我们可以为每个模块设计一个激活针脚。然后我们可以分别用指令输入的第二第三第四个针脚连接寄存器,加法器和位移器的激活针脚。
这样我们输入0100这个指令的时候,寄存器输入被激活,其他模块都是0没有激活,数据就存入寄存器了。同理,如果我们输入0001这个指令,则加法器开始工作,我们就可以执行相加这个操作了。
这里就可以简单回答这个问题的第一个小问题了:CPU是为什么能看懂这些二级制的数呢?
为什么CPU能看懂,因为CPU里面的线就是这么接的呗。你输入一个二进制数,就像开关一样激活CPU里面若干个指定的模块以及改变这些模块的连同方式,最终得出结果。
几个可能会被问的问题
Q:CPU里面可能有成千上万个小模块,一个32位/64位的指令能控制那么多吗?
A:我们举例子的CPU里面只有3个模块,就直接接了。真正的CPU里会有一个解码器(decoder),把指令翻译成需要的形式。
Q:你举例子的简单CPU,如果我输入指令0011会怎么样?
A:当然是同时激活了加法器和位移器从而产生不可预料的后果,简单的说因为你使用了没有设计的指令,所以后果自负呗。在真正的CPU上这么干大概率就是崩溃呗,不过肯定会有各种保护性的设计。
细心的小伙伴可能发现一个问题:你设计的指令【0001,数据与寄存器相加,结果保存到寄存器】这个一步做不出来吧?
毕竟还有一个回写的过程,实际上确实是这样。我们设计的简易CPU执行一个指令差不多得三步,读取指令,执行指令,写寄存器。
经典的RISC设计则是分5步:读取指令(IF),解码指令(ID),执行指令(EX),内存操作(MEM),写寄存器(WB)。我们平常用的x86的CPU有的指令可能要分将近20个步骤。
你可以理解有这么一个开关,我们啪的按一下,CPU就走一步,你按的越快CPU就走的越快。咦?听说你有个想法?少年,你这个想法很危险啊,姑且不说你能不能按那么快。拿现代的CPU来说,也就2GHz多吧,大概一秒也就按个20亿下吧。
就算你能按那么快,虽然速度是上去了,但功耗会大大增加,发热上升稳定性下降。江湖上确实有这种玩法,名曰超频,不过新手不推荐你尝试哈。
那CPU怎么知道自己走到哪一步了呢?前面不是介绍了FF么,这个不光可以用来存中间数据,也可以用来存中间状态,也就是走到哪了。
具体的设计涉及到FSM(finite-state machine),也就是有限状态机理论,以及怎么用FF实装。这个也是很重要的一块,考试必考哈,只不过跟题目关系不大,这里就不展开讲了。
我们再继续刚才的讲,现在我们有3个指令了。我们来试试算个(1+4)X2+3吧。
0100 0001 ;寄存器存入1
0001 0100 ;寄存器的数字加4
0010 0000 ;乘2
0001 0011 ;再加三
太棒了,靠这台计算机我们应该可以打败所有的幼儿园小朋友,称霸大班了。而且现在我们用的是4位的,如果换成8位的CPU完全可以吊打低年级小学生了!
实际上用程序控制CPU是个挺高级的想法,再此之前计算机(器)的CPU都是单独设计的。
1969年一家日本公司BUSICOM想搞程控的计算器,而负责设计CPU的美国公司也觉得每次都重新设计CPU是个挺傻X的事,于是双方一拍即合,于1970年推出一种划时代的产品,世界上第一款微处理器4004。
这个架构改变了世界,那家负责设计CPU的美国公司也一步一步成为了业界巨头。哦对了,它叫Intel,对,就是噔噔噔噔的那个。
我们把刚才的程序整理一下:
"01000001000101000010000000010011"
你来把它输入CPU,我去准备一下去幼儿园大班踢馆的工作。
什么!?等我们输完了人家小朋友掰手指都能算出来了?
没办法机器语言就是这么反人类。哦,忘记说了,这种只有01组成的语言被称之为机器语言(机器码),是CPU唯一可以理解的语言。不过你把机器语言让人读,绝对一秒变典韦,这谁也受不了。
所以我们还是改进一下吧。不过话虽这么讲,也就往前个30年,直接输入01也是个挺普遍的事情。
于是我们把我们机器语言写成的程序:
0100 0001 ;寄存器存入1
0001 0100 ;寄存器的数字加4
0010 0000 ;乘2
0001 0011 ;再加三
改写成:
MOV 1 ;寄存器存入1
ADD 4 ;寄存器的数字加4
SHL 0 ;乘2(介于我们设计的乘法器暂时只能乘2,这个0是占位的)
ADD 3 ;再加三
是不是容易读多了?这就叫汇编语言。
汇编语言的好处在于它和机器语言一一对应。
也就是我们写的汇编可以完美的改写成机器语言,直接指挥cpu,进行底层开发;我们也可以把内存中的数据dump出来,以汇编语言的形式展示出来,方便调试和debug。
汇编语言极大的增强了机器语言的可读性和开发效率,但对于人类来说也依然是太晦涩了,于是我们又发明了高级语言,以近似于人类的语法来表现数据结构和算法。
比如很多语言都可以这么写:
a=(1+4)*2+3;
当然这样计算机是不认识的,我们要把它翻译成计算机认识的形式,这个过程叫编译,用来做这个事的东西叫编译器。
具体怎么把高级语言弄成汇编语言/机器语言的,一本书都写不完,我们就举个简单的例子。
我们把:
(1+4)*2+3
转换成:
1,4,+,2,*,3,+
这种写法叫后缀表示法,也成为逆波兰表示法。相对的,我们平常用的表示法叫中缀表示法,也就是符号方中间,比如1+4。而后缀表示法则写成1,4,+。
转换成这种写法的好处是没有先乘除后加减的影响,也没有括号了,直接算就行了。
具体怎么转换的可以找本讲编译原理的书看看,这里不展开讲了。
转换成这种形式之后我们就可以把它改成成汇编语言了。
从头开始处理,最开始是1,一个数字,那就存入寄存器:
MOV 1
之后是4,+,那就加一下:
ADD 4
然后是2,*,那就乘一下(介于我们设计的乘法器暂时只能乘2,这个0是占位的):
SHL 0
最后是3,+,那再加一下:
ADD 3
最后我们把翻译好的汇编整理一下:
MOV 1
ADD 4
SHL 0
ADD 3
再简单的转换成机器语言,就可以拿到我们设计的简单CPU上运行了。
其实到了这一步,应该把这个问题都讲清楚了:C语言写出来的东西是怎么翻译成二进制的,电脑又是怎么运行这个二进制的。
只不过题主最后还提到栈和硬件的关系,这里就再多说几句。
其实栈是一种数据结构,跟CPU无关。只不过栈这个数据结构实在太常用了,以至于CPU会针对性的进行优化。为了能让我们的CPU也能用栈,我们给它增加几个组件。
第一,增加一组寄存器。现在有两组寄存器了,我们分别成为A和B。
第二,增加两个指令,RDA/RDB和WRA/WRB,分别为把指定内存地址的数据读到寄存器A/B,和把寄存器A/B的内容写到指定地址。
顺便再说下内存,内存有个地址总线,有个数据总线。比如你要把1100这个数字存到0011这个地址,就把1100接到数据总线,0011接到地址总线,都准备好了啪嚓一按开关(对,就是我们前面提到的那个开关),就算是存进去了。
什么叫DDR内存呢,就是你按这个开关的时候存进去一个数字,抬起来之前你把地址和数据都更新一下,然后一松手,啪!又进去一个。也就是正常的内存你按一下进去1个数据,现在你按一下进去俩数据,这就叫双倍速率(Double Data Rate,简称DDR)
加了这几个命令之后我们发现按原来的设计,CPU每个指令针脚控制一个模块的方式的话针脚不够用了。所以我们就需要加一个解码器了(decoder)。
于是我们选择用第二个位作为是否选择寄存器的针脚。如果为0,则第三第四位可以正常激活位移器和加法器;如果为1则只激活寄存器而不激活位移和加法器,然后用第四位来决定是寄存器A还是B。这样变成了:
0100,数据读入寄存器A
0101,数据读入寄存器B (我们把汇编指令定义为MOVB)
0001,数据与寄存器A相加,结果保存到寄存器A
0011,数据与寄存器B相加,结果保存到寄存器B(我们把汇编指令定义为ADDB)
0010,寄存器A数据向左位移一位(乘2)
最后我们可以用第一位来控制是不是进行内存操作。如果第一位为1则也不激活位移和加法器模块,然后用第三个针脚来控制是读还是写。这样就有了:
1100,把寄存器B的地址数据读入寄存器A(我们把汇编指令定义为RD)
1110,寄存器A的数据写到寄存器B指定的地址(我们把汇编指令定义为WR)
我们加了个解码器之后,加法器的激活条件从p4变成了(NOT (p1 OR p2)) AND p4。
加法器的输入则由第三个针脚判断,0则为寄存器A,1为寄存器B。这就是简单的指令解码啦。
当然我们也可以选择不向下兼容,另外设计一套指令。不过放到现实世界恐怕就要出大乱子了,所以你也可以想象我们平常用的x86背了个多大的历史包袱。
这个时候我们用栈的话,先栈地址初始化:
0101 1000 ; MOVB 16; 把栈底地址定义为1000
之后入栈的话,比如把数字3,4入栈:
1111 0011 ; WR 03; 把3写到内存,地址为1000
0011 0001 ; ADDB 01; 栈地址+1
1111 0100 ; WR 04; 把3写到内存,地址为1001
0011 0001 ; ADDB 01; 栈地址+1
这样就把3,4都保存到栈里了。
出栈的话反过来:
0011 1111 ; ADDB -1; 栈地址-1
1101 0000 ; RD 00; 把内容读入寄存器A,00是占位
0011 1111 ; ADDB -1; 栈地址-1
1101 0000 ; RD 00; 把内容读入寄存器A,00是占位
这样就依次得到4,3两个值。
所以,入栈出栈其实就是把数据写道指定的内存位置,CPU其实不知道你是在干啥。当然我们也可以让CPU知道。
接下来我们再改进一下,给CPU再加一个寄存器SP,并定义两个指令:一个PUSH,一个POP。动作分别是把数据写入SP的地址,然后SP=SP+1,POP的话反过来。
这样有什么好处呢?好处在于PUSH/POP这样的指令消耗特别少,速度特别快。而栈这种数据结构在各种程序里用的又特别频繁,设计成专用的指令则可以很大程度上提升效率。
当然前提是编译器知道这个指令,并且做了优化,所以同样的程序(c语言写的),编译参数不一样(打开/关闭某些特性),编译出来的东西也就不一样,在不同硬件上的运行的效率也就会不一样。
比如上古时代的mmx,今天的SSE4.2,AVX-512,给力不给力?特别给力,但你平常用的程序支不支持是另一码事,要支持怎么办?重新编译呗。
这个时候开源的优势就显示出来了,重新编译很方便。闭源的话你就要指望作者开恩啦。
对于大多数人来说,电脑就是个黑箱,我们很难理解它到底是怎用工作的。这个问题又很难一句两句解释清楚,因为它是一环扣一环的,每一环都很抽象,每一环都是基础值俩个学分,展开了讲没上限的那种。
这就导致了即使是系统学过计算机的人也不见得就有一个明确而清晰的思路。想用尽量短的篇幅和尽量简单的语言把这个事从头到位解释了一下,希望能给大家解答一些疑惑。
责任编辑:lq
-
und异常和cpu异步模式代码cpu无法识别2019-04-17 0
-
剖析CPU对代码的识别和读取2021-06-08 0
-
如何识别cpu芯片2010-02-24 2953
-
OBD_CAN读取代码2016-05-16 1352
-
cpu16_verilog源代码2016-05-24 536
-
xml和YAML文件的读取_源代码2016-06-06 698
-
CPU是如何识别代码的2020-04-12 3635
-
python文件读取的源代码免费下载2020-08-07 875
-
如何写出让CPU执行更快的代码?2020-10-29 2359
-
剖析一下CPU对代码的识别和读取2020-12-10 1642
-
简述单片机是如何识别程序代码的2021-03-26 4225
-
OBD_CAN的读取代码程序下载2022-01-18 448
-
单片机是如何识别程序代码的?2022-02-08 428
-
通过SFC 51读取CPU的指示灯状态2023-07-24 1681
全部0条评论

快来发表一下你的评论吧 !
