

215.数组中的第K个最大元素(Medium)
描述
读完本文,可以去力扣解决如下题目:
215.数组中的第 K 个最大元素(Medium)
快速选择算法是一个非常经典的算法,和快速排序算法是亲兄弟。
原始题目很简单,给你输入一个无序的数组nums和一个正整数k,让你计算nums中第k大的元素。
那你肯定说,给nums数组排个序,然后取第k个元素,也就是nums[k-1],不就行了吗?
当然可以,但是排序时间复杂度是O(NlogN),其中N表示数组nums的长度。
我们就想要第k大的元素,却给整个数组排序,有点杀鸡用牛刀的感觉,所以这里就有一些小技巧了,可以把时间复杂度降低到O(NlogK)甚至是O(N),下面我们就来具体讲讲。
力扣第 215 题「数组中的第 K 个最大元素」就是一道类似的题目,函数签名如下:
int findKthLargest(int[] nums, int k);
只不过题目要求找第k个最大的元素,和我们刚才说的第k大的元素在语义上不太一样,题目的意思相当于是把nums数组降序排列,然后返回第k个元素。
比如输入nums = [2,1,5,4], k = 2,算法应该返回 4,因为 4 是nums中第 2 个最大的元素。
这种问题有两种解法,一种是二叉堆(优先队列)的解法,另一种就是标题说到的快速选择算法(Quick Select),我们分别来看。
二叉堆解法
二叉堆的解法比较简单,实际写算法题的时候,推荐大家写这种解法,先直接看代码吧:

二叉堆(优先队列)是比较常见的数据结构,可以认为它会自动排序,我们前文 手把手实现二叉堆数据结构 实现过这种结构,我就默认大家熟悉它的特性了。
看代码应该不难理解,可以把小顶堆pq理解成一个筛子,较大的元素会沉淀下去,较小的元素会浮上来;当堆大小超过k的时候,我们就删掉堆顶的元素,因为这些元素比较小,而我们想要的是前k个最大元素嘛。当nums中的所有元素都过了一遍之后,筛子里面留下的就是最大的k个元素,而堆顶元素是堆中最小的元素,也就是「第k个最大的元素」。
二叉堆插入和删除的时间复杂度和堆中的元素个数有关,在这里我们堆的大小不会超过k,所以插入和删除元素的复杂度是O(logK),再套一层 for 循环,总的时间复杂度就是O(NlogK)。空间复杂度很显然就是二叉堆的大小,为O(K)。
这个解法算是比较简单的吧,代码少也不容易出错,所以说如果笔试面试中出现类似的问题,建议用这种解法。唯一注意的是,Java 的PriorityQueue默认实现是小顶堆,有的语言的优先队列可能默认是大顶堆,可能需要做一些调整。
快速选择算法
快速选择算法比较巧妙,时间复杂度更低,是快速排序的简化版,一定要熟悉思路。
我们先从快速排序讲起。
快速排序的逻辑是,若要对nums[lo..hi]进行排序,我们先找一个分界点p,通过交换元素使得nums[lo..p-1]都小于等于nums[p],且nums[p+1..hi]都大于nums[p],然后递归地去nums[lo..p-1]和nums[p+1..hi]中寻找新的分界点,最后整个数组就被排序了。
快速排序的代码如下:

关键就在于这个分界点索引p的确定,我们画个图看下partition函数有什么功效:
索引p左侧的元素都比nums[p]小,右侧的元素都比nums[p]大,意味着这个元素已经放到了正确的位置上,回顾快速排序的逻辑,递归调用会把nums[p]之外的元素也都放到正确的位置上,从而实现整个数组排序,这就是快速排序的核心逻辑。
那么这个partition函数如何实现的呢?看下代码:
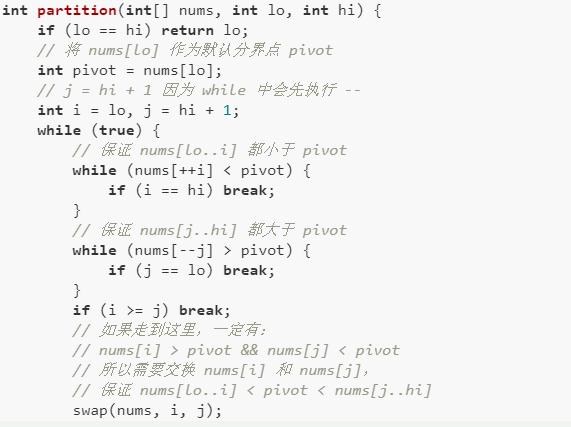

熟悉快速排序逻辑的读者应该可以理解这段代码的含义了,这个partition函数细节较多,上述代码参考《算法4》,是众多写法中最漂亮简洁的一种,所以建议背住,这里就不展开解释了。
好了,对于快速排序的探讨到此结束,我们回到一开始的问题,寻找第k大的元素,和快速排序有什么关系?
注意这段代码:
int p = partition(nums, lo, hi);
我们刚说了,partition函数会将nums[p]排到正确的位置,使得nums[lo..p-1] < nums[p] < nums[p+1..hi]。
那么我们可以把p和k进行比较,如果p < k说明第k大的元素在nums[p+1..hi]中,如果p > k说明第k大的元素在nums[lo..p-1]中。
所以我们可以复用partition函数来实现这道题目,不过在这之前还是要做一下索引转化:
题目要求的是「第k个最大元素」,这个元素其实就是nums升序排序后「索引」为len(nums) - k的这个元素。
这样就可以写出解法代码:

这个代码框架其实非常像我们前文 二分搜索框架 的代码,这也是这个算法高效的原因,但是时间复杂度为什么是O(N)呢?按理说类似二分搜索的逻辑,时间复杂度应该一定会出现对数才对呀?
其实这个O(N)的时间复杂度是个均摊复杂度,因为我们的partition函数中需要利用 双指针技巧 遍历nums[lo..hi],那么总共遍历了多少元素呢?
最好情况下,每次p都恰好是正中间(lo + hi) / 2,那么遍历的元素总数就是:
N + N/2 + N/4 + N/8 + … + 1
这就是等比数列求和公式嘛,求个极限就等于2N,所以遍历元素个数为2N,时间复杂度为O(N)。
但我们其实不能保证每次p都是正中间的索引的,最坏情况下p一直都是lo + 1或者一直都是hi - 1,遍历的元素总数就是:
N + (N - 1) + (N - 2) + … + 1
这就是个等差数列求和,时间复杂度会退化到O(N^2),为了尽可能防止极端情况发生,我们需要在算法开始的时候对nums数组来一次随机打乱:

前文 洗牌算法详解 写过随机乱置算法,这里就不展开了。当你加上这段代码之后,平均时间复杂度就是O(N)了,提交代码后运行速度大幅提升。
总结一下,快速选择算法就是快速排序的简化版,复用了partition函数,快速定位第 k 大的元素。相当于对数组部分排序而不需要完全排序,从而提高算法效率,将平均时间复杂度降到O(N)。
责任编辑:xj
原文标题:快排亲兄弟:快速选择算法详解
文章出处:【微信公众号:算法与数据结构】欢迎添加关注!文章转载请注明出处。
-
[教程] Matlab中矩阵、向量及数组元素的引用方法和讨论2011-05-07 19684
-
关于大容量数组中某个元素的定位问题2014-06-17 1916
-
删除或替换数组中某元素2014-07-01 17040
-
【分享】labview数组应用2015-01-30 4371
-
两个一维数组中相同元素的个数2016-04-07 8332
-
LabVIEW数组至簇转换元素的对应问题2018-02-28 7769
-
LeetCode 215. Kth Largest Element in an Array2018-01-17 664
-
详解一道高频算法题:数组中的第 K 个最大元素2020-06-03 2751
-
Labview一维数组相同元素去重及相同元素个数源代码免费下载2020-08-31 2743
-
数组一维中相同元素个数统计2022-05-31 619
-
如何求三个数组的共同元素2022-08-17 1952
-
C 语言数组的基本结构2023-06-22 1485
-
c语言在数组中查找指定元素2023-11-24 6094
-
labview怎么查数组中相同元素的个数2023-12-28 6810
-
随机抽取SV数组中的一个元素方法实现2024-03-21 2300
全部0条评论

快来发表一下你的评论吧 !
