

一种简单高效的pipeline方法,在多个基准上获得了新的SOTA结果
描述
端到端关系抽取涉及两个子任务:命名实体识别和关系抽取。近期研究多采用 joint 方式建模两个子任务,而陈丹琦等人新研究提出一种简单高效的 pipeline 方法,在多个基准上获得了新的 SOTA 结果。
端到端关系抽取旨在识别命名实体,同时抽取其关系。近期研究大多采取 joint 方式建模这两项子任务,要么将二者统一在一个结构化预测网络中,要么通过共享表示进行多任务学习。 而近期来自普林斯顿大学的 Zexuan Zhong、陈丹琦介绍了一种非常简单的方法,并在标准基准(ACE04、ACE05 和 SciERC)上取得了新的 SOTA 成绩。该方法基于两个独立的预训练编码器构建而成,只使用实体模型为关系模型提供输入特征。通过一系列精心检验,该研究验证了学习不同的语境表示对实体和关系的重要性,即在关系模型的输入层融合实体信息,并集成全局语境信息。 此外,该研究还提出了这一方法的高效近似方法,只需要在推断时对两个编码器各执行一次,即可获得 8-16 倍的加速,同时准确率仅小幅下降。
论文链接:https://arxiv.org/pdf/2010.12812.pdf pipeline 方法重回巅峰? 从非结构化文本中抽取实体及其关系是信息抽取中的基本问题。这个问题可以分解为两个子任务:命名实体识别和关系抽取。 早期研究采用 pipeline 方法:训练一个模型来抽取实体,另一个模型对实体之间的关系进行分类。而近期,端到端关系抽取任务已经成为联合建模子任务系统的天下。大家普遍认为,这种 joint 模型可以更好地捕获实体与关系之间的交互,并有助于缓解误差传播问题。 然而,这一局面似乎被一项新研究打破。近期,普林斯顿大学 Zexuan Zhong 和陈丹琦提出了一种非常简单的方法,该方法可以学习基于深度预训练语言模型构建的两个编码器,这两个模型分别被称为实体模型和关系模型。它们是独立训练的,并且关系模型仅依赖实体模型作为输入特征。实体模型基于 span-level 表示而构建,关系模型则建立在给定 span 对的特定语境表示之上。 虽然简单,但这一 pipeline 模型非常有效:在 3 个标准基准(ACE04、ACE05、SciERC)上,使用相同的预训练编码器,该模型优于此前所有的 joint 模型。 为什么 pipeline 模型能实现如此优秀的性能呢?研究者进行了一系列分析,发现:
实体模型和关系模型的语境表示本质上捕获了不同的信息,因此共享其表示会损害性能;
在关系模型的输入层融合实体信息(边界和类型)至关重要;
在两个子任务中利用跨句(cross-sentence)信息是有效的;
更强大的预训练语言模型能够带来更多的性能收益。
研究人员希望,这一模型能够引发人们重新思考联合训练在端到端关系抽取中的价值。 不过,该方法存在一个缺陷:需要为每个实体对运行一次关系模型。为了缓解该问题,研究者提出一种新的有效替代方法,在推断时近似和批量处理不同组实体对的计算。该近似方法可以实现 8-16 倍的加速,而准确率的下降却很小(例如在 ACE05 上 F1 分数下降了 0.5-0.9%)。这使得该模型可以在实践中快速准确地应用。 研究贡献 该研究的主要贡献有:
提出了一种非常简单有效的端到端关系抽取方法,该方法学习两个独立编码器,分别用于实体识别和关系抽取的。该模型在三个标准基准上达到了新 SOTA,并在使用相同的预训练模型的时,性能超越了此前所有 joint 模型。
该研究经过分析得出结论:对于实体和关系而言,相比于联合学习,学习不同的语境表示更加有效。
为了加快模型推断速度,该研究提出了一种新颖而有效的近似方法,该方法可实现 8-16 倍的推断加速,而准确率只有很小的降低。
方法 该研究提出的模型包括一个实体模型和一个关系模型。如下图所示,首先将输入句子馈入实体模型,该模型为每一个 span 预测实体类型;然后通过嵌入额外的 marker token 在关系模型中独立处理每对候选实体,以突出显示主语、宾语及其类型。
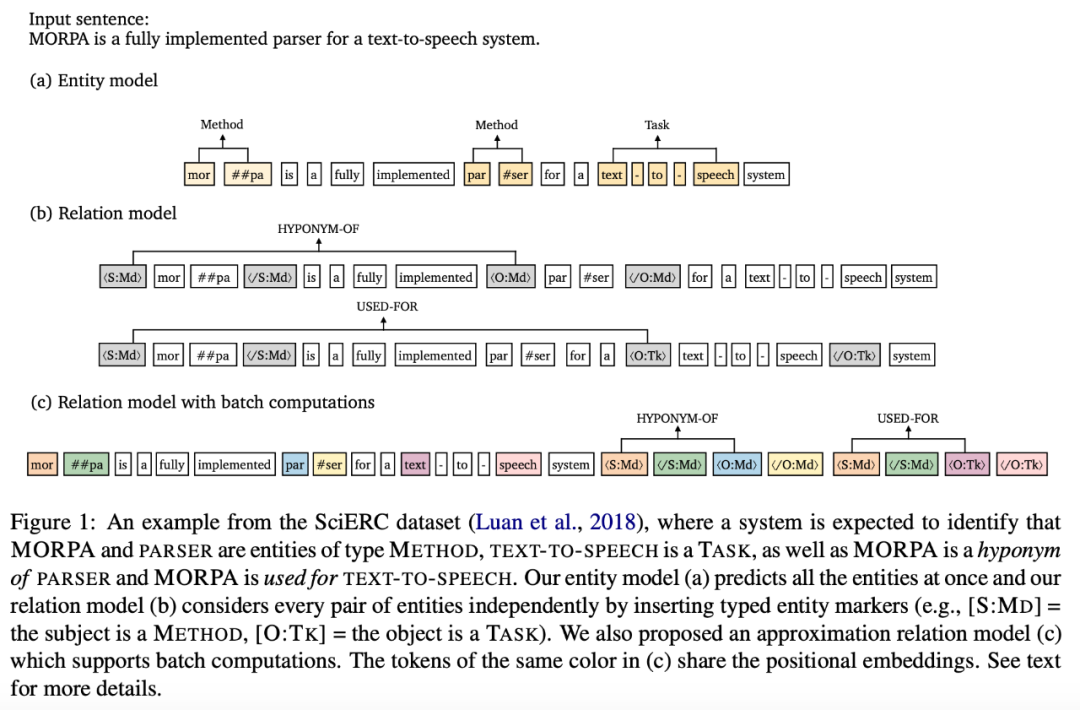
此外,研究者还介绍了该方法与 DYGIE++ 的区别(DYGIE++ 与该方法很接近,并且是最强的基线方法)。 1. 该研究提出的方法对实体模型和关系模型使用不同的编码器,未使用多任务学习;预测得到的实体标签直接作为关系模型的输入特征。 2. 关系模型中的语境表示特定于每个 span 对。 3. 该方法用额外的语境扩展输入,从而纳入跨句信息。 4. 该方法未使用束搜索或图传播层,因此,该模型要简单得多。 有效的近似方法 该研究提出的方法较为简洁有效,但是它的缺点是需要对每一个实体对运行一次关系模型。为此,研究者提出一种新型高效的替代性关系模型。核心问题在于,如何对同一个句子中的不同 span 对重用计算,在该研究提出的原始模型中这是不可能实现的,因为必须为每个 span 对分别嵌入特定的实体标记。因此,研究者提出了一种近似模型,该模型对原始模型做了两个重要更改。 首先,该近似方法没有选择直接将实体标记嵌入原始句子,而是将标记的位置嵌入与对应 span 的开始和结束 token 联系起来:
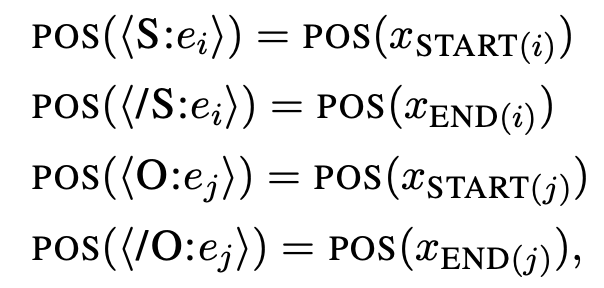
其次,近似方法为注意力层添加了约束:使文本 token 只注意文本 token 不注意标记 token,实体标记 token 则可以注意所有文本 token,4 个标记 token 全部与同一个 span 对关联。 这两项更改允许模型对所有文本 token 重用计算,因为文本 token 独立于实体标记 token。因而,该方法可以在运行一次关系模型时批量处理来自同一个句子的多个 span 对。 实验 研究人员在三个端到端关系抽取数据集 ACE04、ACE054 和 SciERC 上进行方法评估,使用 F1 分数作为评估度量指标。 下表 2 展示了不同方法的对比结果:
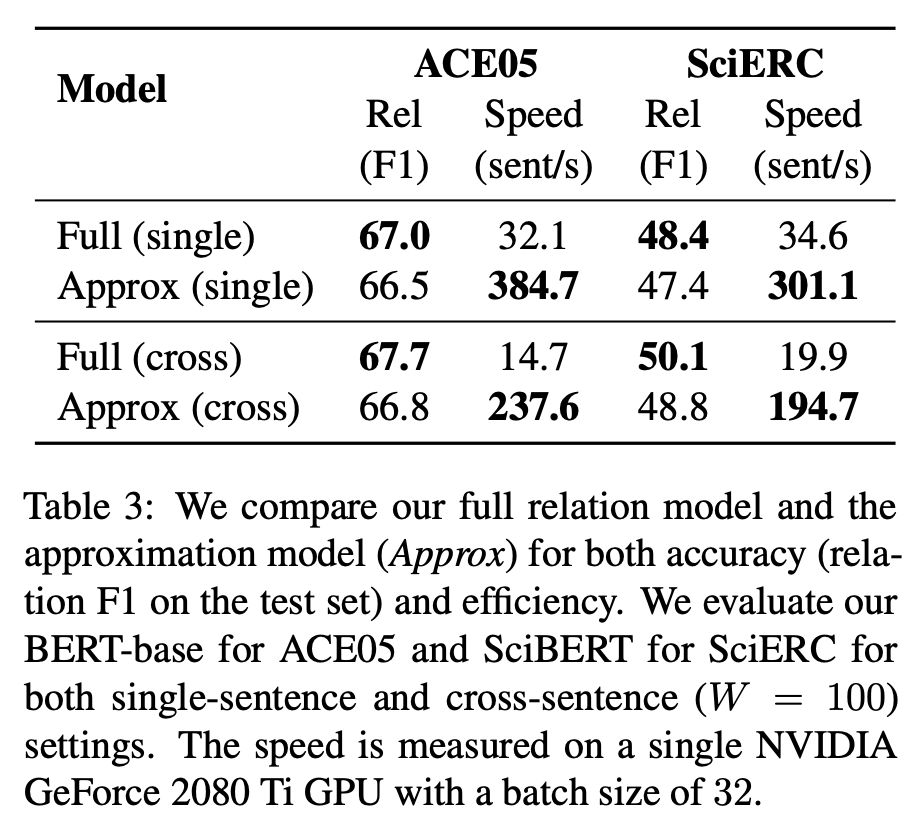
从图中可以看出,该研究提出的 single-sentence 模型实现了强大的性能,而纳入跨句语境后,性能结果得到了一致提升。该研究使用的 BERT-base(或 SciBERT)模型获得了与之前工作类似或更好的结果,包括那些基于更大型预训练语言模型构建的模型,使用较大编码器 ALBERT 后性能得到进一步提升。 近似方法的性能 下表展示了完全关系模型和近似模型的 F1 分数与推断速度。在两个数据集上,近似模型的推断速度显著提升。
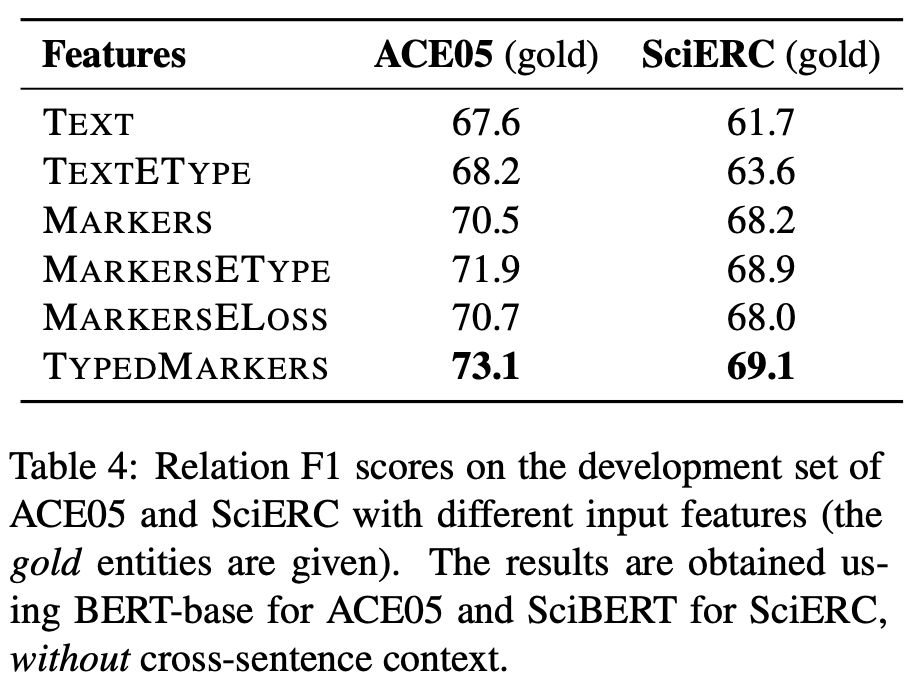
这个 pipeline 模型为什么超过了 joint 模型? 除了展示方法和性能以外,该研究还深入分析了这一 pipeline 模型取得如此优秀性能的原因。 键入文本标记(typed text marker)的重要性 该研究认为,为不同 span 对构建不同语境表示非常重要,早期融合实体类型信息可以进一步提升性能。 为了验证键入文本标记的作用,研究者使用其不同变体在 ACE05 和 SciERC 数据集上进行实验,包括 TEXT、TEXTETYPE、MARKERS、MARKERSETYPE、MARKERSELOSS、TYPEDMARKERS 六种。 下表 4 展示了这些变体的性能,从中可以看出不同的输入表示确实对关系抽取的准确率产生影响。
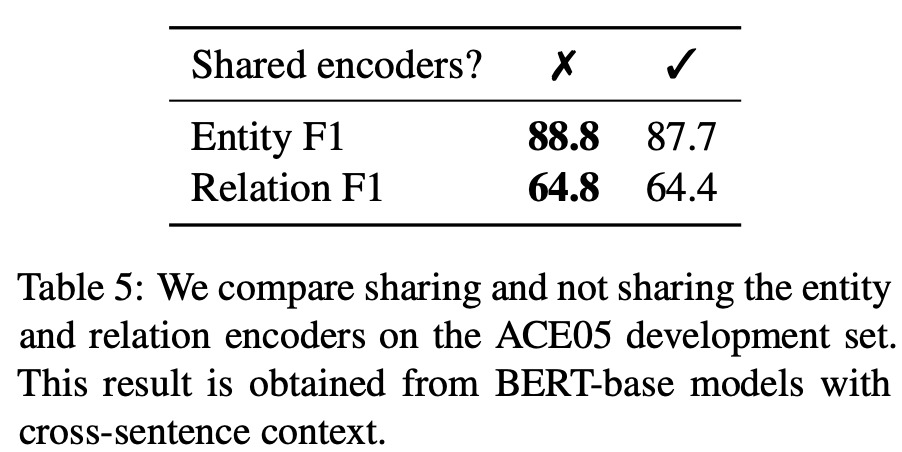
实体和关系如何交互 人们对 joint 模型的主要认知是,对两个子任务之间交互的建模对彼此有所帮助。但这项研究并未采取这种方式,而是使用了两个独立的编码器。 研究人员首先研究了共享两个表示编码器能否提升性能。如下表 5 所示,简单地共享编码器对实体 F1 和关系 F1 分数均有所损害。研究人员认为,其原因在于两个任务具备不同的输入格式,需要不同的特征来预测实体类型和关系,因此使用单独的编码器可以学得更好的任务特定特征。
该研究的分析结果显示: 实体信息有助于预测关系,但实验未表明关系信息可以大幅提升实体性能。 仅共享编码器对该研究提出的方法无益。 如何缓解 pipeline 方式中的误差传播问题 pipeline 训练的一个主要缺陷是误差传播问题。使用 gold 实体(及其类型)进行关系模型训练,使用预测实体进行推断,可能会导致训练和测试之间存在差异。 为此,研究人员首先探究在训练阶段使用预测实体(而非 gold 实体)能否缓解这一问题。该研究采用 10-way jackknifing 方法,结果发现这一策略竟然降低了最终的关系性能。研究人员假设其原因在于训练阶段引入了额外的噪声。 在目前的 pipeline 方法中,如果在推断阶段 gold 实体没有被实体模型识别出来,则关系模型无法预测与该实体相关的任何关系。于是,研究人员考虑在训练和测试阶段,对关系模型使用更多 span 对。实验结果表明,这无法带来性能提升。 这些常识未能显著提升性能,而该研究提出的简单 pipeline 方法却惊人的有效。研究者认为误差传播问题并非不存在或无法被解决,我们需要探索更好的解决方案。
责任编辑:lq
-
Mamba入局图像复原,达成新SOTA2024-12-30 2237
-
一种简单高效配置FPGA的方法2024-10-24 2859
-
华为诺亚提出新型Prompting (PHP),GPT-4拿下最难数学推理数据集新SOTA2023-05-15 2008
-
一种简单的OpenHarmony环境搭建方法2022-03-14 4726
-
怎么设计一种新型的CMOS电流反馈运算放大器?2021-06-04 2040
-
求一种新的双T型选频网络电路的设计方法2021-04-23 2775
-
CMOS图像传感器优势十足 近年来获得了快速的发展2019-12-05 2990
-
为什么对话框按键获得了焦点但按ENTER没有反应?2019-11-11 2450
-
为什么我用示例项目从EEPROM阅读只获得了0xFF?2019-08-05 1198
-
一种基于ADSP21062的雷达信号处理系统调试设计2019-07-19 2679
-
在智能家居市场中,智能锁以其优质的性能获得了众多消费者的青睐2018-09-29 940
-
一种简单的逆变器输出直流分量消除方法2011-12-27 13877
-
一种结构简单的CMOS带隙基准电压源设计2010-01-11 988
-
一种低压曲率校正带隙基准电压源2009-06-29 827
全部0条评论

快来发表一下你的评论吧 !
