

数据科学经典算法 KNN 已被嫌慢,ANN 比它快 380 倍
电子说
描述
数据科学经典算法 KNN 已被嫌慢,ANN 比它快 380 倍。
在模式识别领域中,K - 近邻算法(K-Nearest Neighbor, KNN)是一种用于分类和回归的非参数统计方法。K - 近邻算法非常简单而有效,它的模型表示就是整个训练数据集。就原理而言,对新数据点的预测结果是通过在整个训练集上搜索与该数据点最相似的 K 个实例(近邻)并且总结这 K 个实例的输出变量而得出的。KNN 可能需要大量的内存或空间来存储所有数据,并且使用距离或接近程度的度量方法可能会在维度非常高的情况下(有许多输入变量)崩溃,这可能会对算法在你的问题上的性能产生负面影响。这就是所谓的维数灾难。
近似最近邻算法(Approximate Nearest Neighbor, ANN)则是一种通过牺牲精度来换取时间和空间的方式从大量样本中获取最近邻的方法,并以其存储空间少、查找效率高等优点引起了人们的广泛关注。
近日,一家技术公司的数据科学主管 Marie Stephen Leo 撰文对 KNN 与 ANN 进行了比较,结果表明,在搜索到最近邻的相似度为 99.3% 的情况下,ANN 比 sklearn 上的 KNN 快了 380 倍。
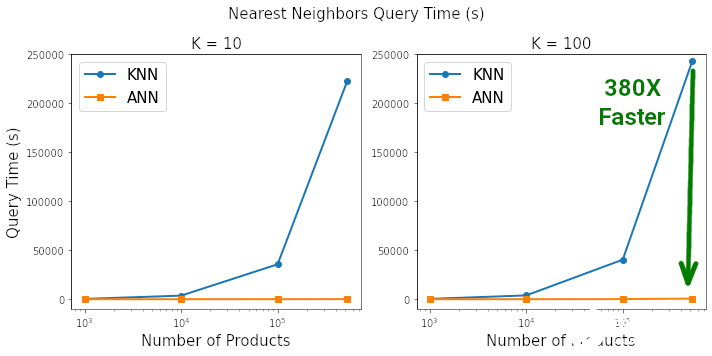
作者表示,几乎每门数据科学课程中都会讲授 KNN 算法,但它正在走向「淘汰」!
KNN 简述
在机器学习社区中,找到给定项的「K」个相似项被称为相似性搜索或最近邻(NN)搜索。最广为人知的 NN 搜索算法是 KNN 算法。在 KNN 中,给定诸如手机电商目录之类的对象集合,则对于任何新的搜索查询,我们都可以从整个目录中找到少量(K 个)最近邻。例如,在下面示例中,如果设置 K = 3,则每个「iPhone」的 3 个最近邻是另一个「iPhone」。同样,每个「Samsung」的 3 个最近邻也都是「Samsung」。

KNN 存在的问题
尽管 KNN 擅长查找相似项,但它使用详细的成对距离计算来查找邻居。如果你的数据包含 1000 个项,如若找出新产品的 K=3 最近邻,则算法需要对数据库中所有其他产品执行 1000 次新产品距离计算。这还不算太糟糕,但是想象一下,现实世界中的客户对客户(Customer-to-Customer,C2C)市场,其中的数据库包含数百万种产品,每天可能会上传数千种新产品。将每个新产品与全部数百万种产品进行比较是不划算的,而且耗时良久,也就是说这种方法根本无法扩展。
解决方案
将最近邻算法扩展至大规模数据的方法是彻底避开暴力距离计算,使用 ANN 算法。
近似最近距离算法(ANN)
严格地讲,ANN 是一种在 NN 搜索过程中允许少量误差的算法。但在实际的 C2C 市场中,真实的邻居数量比被搜索的 K 近邻数量要多。与暴力 KNN 相比,人工神经网络可以在短时间内获得卓越的准确性。ANN 算法有以下几种:
Spotify 的 ANNOY
Google 的 ScaNN
Facebook 的 Faiss
HNSW
分层的可导航小世界(Hierarchical Navigable Small World, HNSW)
在 HNSW 中,作者描述了一种使用多层图的 ANN 算法。在插入元素阶段,通过指数衰减概率分布随机选择每个元素的最大层,逐步构建 HNSW 图。这确保 layer=0 时有很多元素能够实现精细搜索,而 layer=2 时支持粗放搜索的元素数量少了 e^-2。最近邻搜索从最上层开始进行粗略搜索,然后逐步向下处理,直至最底层。使用贪心图路径算法遍历图,并找到所需邻居数量。
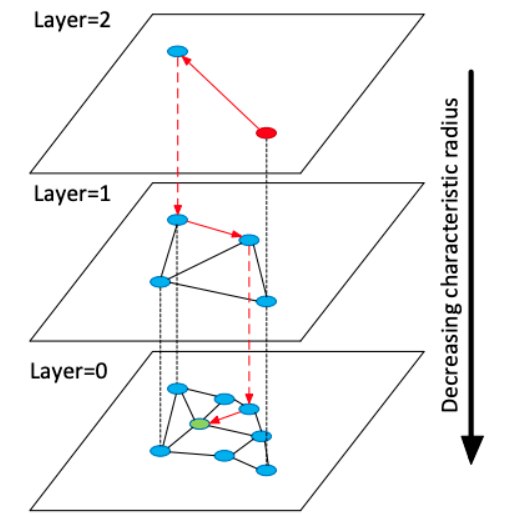
HNSW 图结构。最近邻搜索从最顶层开始(粗放搜索),在最底层结束(精细搜索)。
HNSW Python 包
整个 HNSW 算法代码已经用带有 Python 绑定的 C++ 实现了,用户可以通过键入以下命令将其安装在机器上:pip install hnswlib。安装并导入软件包之后,创建 HNSW 图需要执行一些步骤,这些步骤已经被封装到了以下函数中:
importhnswlib importnumpy asnpdef fit_hnsw_index(features, ef= 100, M= 16, save_index_file= False): # Convenience function to create HNSW graph # features : list of lists containing the embeddings # ef, M: parameters to tune the HNSW algorithm num_elements = len(features) labels_index = np.arange(num_elements) EMBEDDING_SIZE = len(features[ 0]) # Declaring index # possible space options are l2, cosine or ip p = hnswlib.Index(space= ‘l2’, dim=EMBEDDING_SIZE) # Initing index - the maximum number of elements should be known p.init_index(max_elements=num_elements, ef_construction=ef, M=M) # Element insertion int_labels = p.add_items(features, labels_index) # Controlling the recall by setting ef # ef should always be 》 k p.set_ef(ef) # If you want to save the graph to a file ifsave_index_file: p.save_index(save_index_file) returnp
创建 HNSW 索引后,查询「K」个最近邻就仅需以下这一行代码:
ann_neighbor_indices, ann_distances = p.knn_query(features, k)
KNN 和 ANN 基准实验
计划
首先下载一个 500K + 行的大型数据集。然后将使用预训练 fasttext 句子向量将文本列转换为 300d 嵌入向量。然后将在不同长度的输入数据 [1000. 10000, 100000, len(data)] 上训练 KNN 和 HNSW ANN 模型,以度量数据大小对速度的影响。最后将查询两个模型中的 K=10 和 K=100 时的最近邻,以度量「K」对速度的影响。首先导入必要的包和模型。这需要一些时间,因为需要从网络上下载 fasttext 模型。
# Imports # For input data pre-processing importjson importgzip importpandas aspd importnumpy asnp importmatplotlib.pyplot asplt importfasttext.util fasttext.util.download_model( ‘en’, if_exists= ‘ignore’) # English pre-trained model ft = fasttext.load_model( ‘cc.en.300.bin’) # For KNN vs ANN benchmarking fromdatetime importdatetime fromtqdm importtqdm fromsklearn.neighbors importNearestNeighbors importhnswlib
数据
使用亚[马逊产品数据集],其中包含「手机及配件」类别中的 527000 种产品。然后运行以下代码将其转换为数据框架。记住仅需要产品 title 列,因为将使用它来搜索相似的产品。
# Data: http://deepyeti.ucsd.edu/jianmo/amazon/ data = [] withgzip.open( ‘meta_Cell_Phones_and_Accessories.json.gz’) asf: forl inf: data.append(json.loads(l.strip)) # Pre-Processing: https://colab.research.google.com/drive/1Zv6MARGQcrBbLHyjPVVMZVnRWsRnVMpV#scrollTo=LgWrDtZ94w89 # Convert list into pandas dataframe df = pd.DataFrame.from_dict( data) df.fillna( ‘’, inplace= True) # Filter unformatted rows df = df[~df.title.str.contains( ‘getTime’)] # Restrict to just ‘Cell Phones and Accessories’ df = df[df[ ‘main_cat’]== ‘Cell Phones & Accessories’] # Reset index df.reset_index(inplace= True, drop= True) # Only keep the title columns df = df[[ ‘title’]] # Check the df print(df.shape) df.head
如果全部都可以运行精细搜索,你将看到如下输出:

亚马逊产品数据集。
嵌入
要对文本数据进行相似性搜索,则必须首先将其转换为数字向量。一种快速便捷的方法是使用经过预训练的网络嵌入层,例如 Facebook [FastText] 提供的嵌入层。由于希望所有行都具有相同的长度向量,而与 title 中的单词数目无关,所以将在 df 中的 title 列调用 get_sentence_vector 方法。
嵌入完成后,将 emb 列作为一个 list 输入到 NN 算法中。理想情况下可以在此步骤之前进行一些文本清理预处理。同样,使用微调的嵌入模型也是一个好主意。
# Title Embedding using FastText Sentence Embedding df[ ‘emb’] = df[ ‘title’].apply(ft.get_sentence_vector) # Extract out the embeddings column as a list of lists for input to our NN algos X = [item.tolist foritem indf[ ‘emb’].values]
基准
有了算法的输入,下一步进行基准测试。具体而言,在搜索空间中的产品数量和正在搜索的 K 个最近邻之间进行循环测试。在每次迭代中,除了记录每种算法的耗时以外,还要检查 pct_overlap,因为一定比例的 KNN 最近邻也被挑选为 ANN 最近邻。
注意整个测试在一台全天候运行的 8 核、30GB RAM 机器上运行大约 6 天,这有些耗时。理想情况下,你可以通过多进程来加快运行速度,因为每次运行都相互独立。
# Number of products for benchmark loop n_products = [ 1000, 10000, 100000, len(X)] # Number of neighbors for benchmark loop n_neighbors = [ 10, 100] # Dictionary to save metric results for each iteration metrics = { ‘products’:[], ‘k’:[], ‘knn_time’:[], ‘ann_time’:[], ‘pct_overlap’:[]} forproducts intqdm(n_products): # “products” number of products included in the search space features = X[ :products] fork intqdm(n_neighbors): # “K” Nearest Neighbor search # KNN knn_start = datetime.now nbrs = NearestNeighbors(n_neighbors=k, metric= ‘euclidean’).fit(features) knn_distances, knn_neighbor_indices = nbrs.kneighbors(X) knn_end = datetime.now metrics[ ‘knn_time’].append((knn_end - knn_start).total_seconds) # HNSW ANN ann_start = datetime.now p = fit_hnsw_index(features, ef=k* 10) ann_neighbor_indices, ann_distances = p.knn_query(features, k) ann_end = datetime.now metrics[ ‘ann_time’].append((ann_end - ann_start).total_seconds) # Average Percent Overlap in Nearest Neighbors across all “products” metrics[ ‘pct_overlap’].append(np.mean([len(np.intersect1d(knn_neighbor_indices[i], ann_neighbor_indices[i]))/k fori inrange(len(features))])) metrics[ ‘products’].append(products) metrics[ ‘k’].append(k) metrics_df = pd.DataFrame(metrics) metrics_df.to_csv( ‘metrics_df.csv’, index=False) metrics_df
运行结束时输出如下所示。从表中已经能够看出,HNSW ANN 完全超越了 KNN。
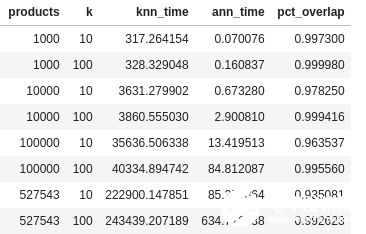
以表格形式呈现的结果。
结果
以图表的形式查看基准测试的结果,以真正了解二者之间的差异,其中使用标准的 matplotlib 代码来绘制这些图表。这种差距是惊人的。根据查询 K=10 和 K=100 最近邻所需的时间,HNSW ANN 将 KNN 彻底淘汰。当搜索空间包含约 50 万个产品时,在 ANN 上搜索 100 个最近邻的速度是 KNN 的 380 倍,同时两者搜索到最近邻的相似度为 99.3%。
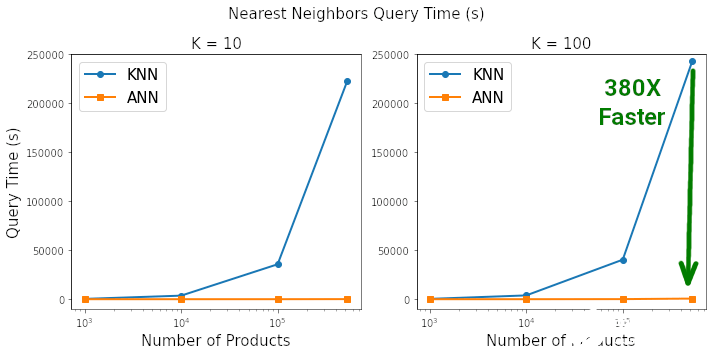
在搜索空间包含 500K 个元素,搜索空间中每个元素找到 K=100 最近邻时,HNSW ANN 的速度比 Sklearn 的 KNN 快 380 倍。
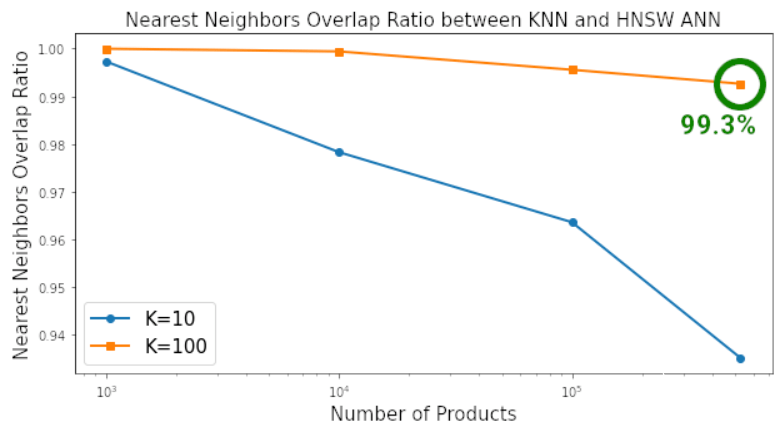
在搜索空间包含 500K 个元素,搜索空间中每个元素找到 K=100 最近邻时,HNSW ANN 和 KNN 搜索到最近邻的相似度为 99.3%。
基于以上结果,作者认为可以大胆地说:「KNN 已死」。
责任编辑:PSY
-
经典算法大全(51个C语言算法+单片机常用算法+机器学十大算法)2018-10-23 43937
-
基于kNN算法可以诊断乳腺癌2019-06-21 2135
-
Java的KNN算法2019-09-10 1820
-
KNN算法原理2019-11-01 2008
-
KNN分类算法及python代码实现2020-06-05 1972
-
使用KNN进行分类和回归2022-10-28 3751
-
利用KNN算法实现基于系统调用的入侵检测技术2009-06-13 798
-
基于一种优化的KNN算法在室内定位中的应用研究2013-05-06 1359
-
基于Spark框架与聚类优化的高效KNN分类算法2017-12-08 1590
-
结合LSH的KNN数据填补算法2017-12-23 1262
-
人工智能机器学习之K近邻算法(KNN)2018-05-29 3564
-
K-Means算法的简单介绍2018-07-05 5601
-
详解机器学习分类算法KNN2019-10-31 7400
-
可检测网络入侵的IL-SVM-KNN分类器2021-04-29 1171
-
KNN算法、分类回归树、随机森林的优缺点及应用实例2022-11-11 7996
全部0条评论

快来发表一下你的评论吧 !
