

评估K8s可用的最常见的存储解决方案
描述
如果你正在运行K8s,其中最大的难题之一是如何为k8s集群选择正确的存储技术,你可能会考虑使用通过动态预配置的块存储卷。实际上,这很大程度上取决于您要运行的工作负载的类型。本篇文章的目标主要是评估K8s可用的最常见的存储解决方案,并进行基本性能测试。
目前CNCF的存储格局和解决方案已经更新,它已从2019年的30个解决方案增长到目前的45个解决方案,还进行了公共云集成的管理扩展,例如AWS EBS,Google永久磁盘或Azure磁盘存储。一些新解决方案像Alluxio一样,更侧重于分布式文件系统或对象存储。
本文的目标是采用K8s可用的最常见的存储解决方案,并准备基本的性能比较。文章使用以下后端在Azure AKS上执行所有测试:
-
AKS native storage class — Azure native premium
-
AWS cloud volume mapped into instance — Azure hostPath with attached Azure managed disk
-
OpenEBS with cStor backend
-
OpenEBS MayaStor
-
Portworx
-
Gluster managed by Heketi
-
Ceph managed by Rook
-
Longhorn
相比于19年的存储方案,GlusterFS Heketi在性能结果上排名倒数第二,它的改进为零,并且大多数情况下是一个沉寂的项目(Heketi作为REST协调器而不是GlusterFS本身)。如果查看它们的官方GitHub,您会发现他们近乎将其置于维护模式,并且云本地存储功能没有任何更新。
另外根据GIGAOM 2020报告, PortWorx仍然是K8s的顶级商业存储解决方案。但是,从性能的角度来看,版本2.0和2.5之间的发行说明中并没有重大的技术或体系结构更改。最好的开源存储,是通过Rook精心策划的CEPH,他发布了2个新版本,并推出了一个新的CEPH版本,称为Octopus。Octopus对缓存机制进行了一些优化,并使用了更现代的内核接口。今年唯一的主要体系结构更改发生在OpenEBS中,它引入了一个称为MayaStor的新后端。这个后端看起来非常有前途。这些k8s常用的解决方案性能到底怎么样了?我们一起来看下。
本机Azure存储
之所以选择该存储类,是为了获得所有测试的基准。此存储类应提供最佳性能。Azure动态创建托管磁盘,并将其映射到具有k8s作为Pod卷的VM。
无需使用任何特殊功能。当您配置新的AKS群集时,将自动预定义2个存储类,分别称为“默认”和“高级托管”。高级类对卷使用基于SSD的高性能和低延迟磁盘。
优点
-
AKS上的默认设置无需执行任何操作。
缺点
-
故障转移情况下非常慢,有时需要将近10分钟才能将卷重新连接到其他节点上的Pod。
$ kubectl get storageclassesNAME PROVISIONER AGEdefault (default) kubernetes.io/azure-disk 8mmanaged-premium kubernetes.io/azure-disk 8m$ kubectl get pvcNAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGEdbench-pv-claim Bound pvc-e7bd34a4-1dbd-11e9-8726-ae508476e8ad 1000Gi RWO managed-premium 10s$ kubectl get poNAME READY STATUS RESTARTS AGEdbench-w7nqf 0/1 ContainerCreating 0 29s
OpenEBS
OpenEBS代表了新的容器附加存储(CAS)概念,其中是单个基于微服务的存储控制器和多个基于微服务的存储副本。它与Portworx一起属于云本机存储类别。
它是完全开源的,目前提供2个后端,分别是Jiva和cStor。我从Jiva开始,然后切换到cStor。cStor进行了一些改进,因为控制器及其副本部署在单个名称空间(安装openebs的名称空间)中,或者它使用原始磁盘而不是格式化分区。每个k8s卷都有其自己的存储控制器,该存储可以在节点上可用存储容量的允许范围内进行扩展。
如何在AKS上获取它?在AKS上安装其实非常容易。
1.我必须连接到所有k8s节点的控制台并安装iSCSI,因为它使用iSCSI协议在Pod和存储控制器与k8s节点之间进行连接。
apt-get updateapt install -y open-iscsi
2.然后,我将单个YAML定义应用于我的k8s集群
kubectl apply -f https://openebs.github.io/charts/openebs-operator-0.8.0.yaml
3.下一步,OpenEBS控制器在底层节点发现了我所有的磁盘。但是我必须手动确定附加的AWS托管磁盘。
kubectl get diskNAME AGEdisk-184d99015253054c48c4aa3f17d137b1 5mdisk-2f6bced7ba9b2be230ca5138fd0b07f1 5mdisk-806d3e77dd2e38f188fdaf9c46020bdc 5m
4.然后,将这些磁盘添加到标准StorageClass引用的自定义k8s资源StoragePoolClaim中。
---apiVersion: storage.k8s.io/v1kind: StorageClassmetadata:name: openebs-customannotations:: cstor: |name: StoragePoolClaimvalue: "cstor-disk"provisioner: openebs.io/provisioner-iscsi---apiVersion: openebs.io/v1alpha1kind: StoragePoolClaimmetadata:name: cstor-diskspec:name: cstor-disktype: diskmaxPools: 3poolSpec:poolType: stripeddisks:diskList:disk-2f6bced7ba9b2be230ca5138fd0b07f1disk-806d3e77dd2e38f188fdaf9c46020bdcdisk-184d99015253054c48c4aa3f17d137b1
完成这些步骤后,我便能够通过k8s PVC动态配置新卷。
优点
-
开源的
-
Maya在资源使用可视化方面做得很好。您可以轻松地在k8s集群中部署多个服务,并轻松设置监视和日志记录以收集集群的所有重要方面。这是调试的理想工具。
-
总的来说,CAS概念–我非常喜欢容器存储背后的想法,并且我相信会有未来。
-
OpenEBS背后的社区—我能够在几分钟内解决任何问题。Slack上的团队非常有帮助。
缺点
-
不成熟-OpenEBS是一个相当新的项目,尚未达到稳定版本。核心团队仍在进行后端优化,这将在接下来的几个月中显著提高性能。
-
Kubelet和存储控制器之间的iSCSI连接由k8s服务实现,这在某些覆盖网络CNI插件(例如Tungsten Fabric)中可能是一个问题。
-
需要在Kubernetes节点上安装其他软件(iSCSI),这使其在托管Kubernetes集群的情况下不切实际。
注意:OpenEBS团队在文档中调整了相关的测试用例场景
https://github.com/kmova/openebs/tree/fio-perf-tests/k8s/demo/dbench
Portworx
Portworx是为k8s设计的另一种容器本机存储,专注于高度分布式的环境。它是一个主机可寻址的存储,其中每个卷都直接映射到其连接的主机。它提供基于应用程序I/O类型的自动调整。那里有更多信息。不幸的是,它是本篇文章中唯一的不开源的存储解决方案。但是,它免费提供3个节点试用版。
如何在AKS上安装它?在AKS上安装也非常容易。我使用了可在其网站上找到的Kubernetes spec生成器。
1.首选,我选择了Portworx托管的etcd来简化设置,并填充了k8s 1.11.4版本。
2.我必须将数据网络接口修改为azure0,因为我使用的是具有高级联网功能的Azure cni。否则,Portworx将使用来自docker bridge的IP地址而不是VM接口。
3.最后一步,网站生成器向我提供了渲染的k8s YAML清单以应用于我的集群。
4.引导后,我在每个k8s节点上运行了Portworx Pod
root@aks-agentpool-20273348-0:~# kubectl get pods -o wide -n kube-system -l name=portworxNAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODEportworx-g9csq 1/1 Running 0 14m 10.0.1.66 aks-agentpool-20273348-2 <none>portworx-nt2lq 1/1 Running 0 14m 10.0.1.4 aks-agentpool-20273348-0 <none>portworx-wcjnx 1/1 Running 0 14m 10.0.1.35 aks-agentpool-20273348-1 <none>
我创建了具有高优先级和3个副本的Storage Class,然后可以配置k8s pvc。
优点
-
易于部署-具有详细配置的网站配置器。
-
AKS集群的配置器,不需要任何其他步骤,如ceph或glusterfs。
-
云原生存储,它可以在硬件集群和公共云上运行。
-
存储感知的服务等级(COS)和应用感知的I/O调整
缺点
-
闭源,专有供应商解决方案。
GlusterFS Heketi
GlusterFS是众所周知的开源存储解决方案。它沿用Ceph,这是RedHat支持的传统开源存储之一。Heketi是用于GlusterFS的RESTful卷管理接口。它提供了一种释放动态配置的GlusterFS卷功能的便捷方法。如果没有此访问权限,则必须手动创建GlusterFS卷并将其映射到k8s pv。
如何在AKS上安装它?我使用了默认的Heketi快速入门指南。
-
首先,我基于示例一创建了一个拓扑文件,其中包含磁盘和主机名。
https://github.com/gluster/gluster-kubernetes/blob/master/deploy/topology.json.sample
2.由于Heketi主要是在基于RHEL的操作系统上开发和测试的,因此我在使用Ubuntu主机的AKS上遇到了一个问题,该内核路径错误。这是解决此问题的PR。
https://github.com/gluster/gluster-kubernetes/pull/557
+++ b/deploy/kube-templates/glusterfs-daemonset.yaml@@ -67,7 +67,7 @@ spec:mountPath: "/etc/ssl"readOnly: true- name: kernel-modules- mountPath: "/usr/lib/modules"+ mountPath: "/lib/modules"readOnly: truesecurityContext:capabilities: {}@@ -131,4 +131,4 @@ spec:path: "/etc/ssl"- name: kernel-moduleshostPath:- path: "/usr/lib/modules"+ path: "/lib/modules"
3.我遇到的AKS的另一个问题是非空磁盘,因此我使用了擦拭来清理glusterfs的磁盘。该磁盘以前没有用于其他任何用途。
wipefs -a /dev/sdc/dev/sdc: 8 bytes were erased at offset 0x00000218 (LVM2_member): 4c 56 4d 32 20 30 30 31
4.最后一步,我运行命令gk-deploy -g -t topology.json,该命令在由heketi控制器控制的每个节点上部署了glusterfs pod。
root@aks-agentpool-20273348-0:~# kubectl get po -o wideNAME READY STATUS RESTARTS IP NODE NOMINATED NODEglusterfs-fgc8f 1/1 Running 0 10.0.1.35 aks-agentpool-20273348-1glusterfs-g8ht6 1/1 Running 0 10.0.1.4 aks-agentpool-20273348-0glusterfs-wpzzp 1/1 Running 0 10.0.1.66 aks-agentpool-20273348-2heketi-86f98754c-n8qfb 1/1 Running 0 10.0.1.69 aks-agentpool-20273348-2
然后,我面临着动态配置的问题。Heketi restURL对k8s控制平面不可用。我尝试了kube dns记录,pod IP和svc IP。两者都不起作用。因此,我不得不通过Heketi CLI手动创建卷。
root@aks-agentpool-20273348-0:~# export HEKETI_CLI_SERVER=http://10.0.1.69:8080root@aks-agentpool-20273348-0:~# heketi-cli volume create --size=10 --persistent-volume --persistent-volume-endpoint=heketi-storage-endpoints | kubectl create -f -persistentvolume/glusterfs-efb3b155 createdroot@aks-agentpool-20273348-0:~# kubectl get pvNAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGEglusterfs-efb3b155 10Gi RWX Retain Available 19s
然后,必须为我的dbench工具将现有的PV映射到PVC。
kind: PersistentVolumeClaimapiVersion: v1metadata:name: glusterfs-efb3b155spec:accessModes:ReadWriteManystorageClassName: ""resources:requests:storage: 10GivolumeName: glusterfs-efb3b155kubectl get pvcNAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGEBound glusterfs-efb3b155 10Gi RWX 36m
从k8s上的Heketi Gluster安装获得更多输出。
gluster volume info vol_efb3b15529aa9aba889d7900f0ce9849Volume Name: vol_efb3b15529aa9aba889d7900f0ce9849Type: ReplicateVolume ID: 96fde36b-e389-4dbe-887b-baae32789436Status: StartedSnapshot Count: 0Number of Bricks: 1 x 3 = 3Transport-type: tcpBricks:Brick1: 10.0.1.66:/var/lib/heketi/mounts/vg_5413895eade683e1ca035760c1e0ffd0/brick_cd7c419bc4f4ff38bbc100c6d7b93605/brickBrick2: 10.0.1.35:/var/lib/heketi/mounts/vg_3277c6764dbce56b5a01426088901f6d/brick_6cbd74e9bed4758110c67cfe4d4edb53/brickBrick3: 10.0.1.4:/var/lib/heketi/mounts/vg_29d6152eeafc57a707bef56f091afe44/brick_4856d63b721d794e7a4cbb4a6f048d96/brickOptions Reconfigured:transport.address-family: inetnfs.disable: onperformance.client-io-threads: offkubectl get svcNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEheketi ClusterIP 192.168.101.758080/TCP 5h heketi-storage-endpoints ClusterIP 192.168.103.661/TCP 5h root@aks-agentpool-20273348-0:~# kubectl get endpointsNAME ENDPOINTS AGEheketi 10.0.1.69:8080 5hheketi-storage-endpoints 10.0.1.35:1,10.0.1.4:1,10.0.1.66:1 5hkubernetes 172.31.22.152:443 1droot@aks-agentpool-20273348-0:~# kubectl get endpoints heketi-storage-endpoints -o yamlapiVersion: v1kind: Endpointsmetadata:creationTimestamp: 2019-01-29T15:14:28Zname: heketi-storage-endpointsnamespace: defaultresourceVersion: "142212"selfLink: /api/v1/namespaces/default/endpoints/heketi-storage-endpointsuid: 91f802eb-23d8-11e9-bfcb-a23b1ec87092subsets:- addresses:- ip: 10.0.1.35- ip: 10.0.1.4- ip: 10.0.1.66ports:- port: 1protocol: TCP
优点
-
成熟的存储解决方案
-
比Ceph更轻
缺点
-
Heketi不是为公共管理的k8设计的。它与HW群集配合使用,安装更容易。
-
并非真正为“结构化数据”设计的,如SQL数据库。但是,您可以使用Gluster备份和还原数据库。
Ceph Rook
OpenStack私有云常见和Ceph进行搭配。它始终需要设计特定的硬件配置,根据数据类型生成pg组,配置日志SSD分区(在bluestore之前)并定义Crush Map。因此,当我第一次听说在3节点k8s集群中使用Ceph时,我不敢相信它实际上可以工作。但是,Rook编排工具给我留下了深刻的印象,该工具为我完成了所有痛苦的步骤,并且与k8s编排一起提供了一种非常简单的方法来处理整个存储集群的安装。
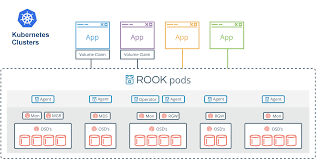
如何在AKS上安装它?在默认安装中,Rook不需要任何特殊步骤,并且如果您不希望使用高级配置,它会非常平滑。
1.我使用了Ceph快速入门指南
https://github.com/rook/rook/blob/master/Documentation/ceph-quickstart.md#ceph-storage-quickstart
2.我必须配置特定于AKS的FLEXVOLUME_DIR_PATH,因为它们使用/etc/kubernetes/volumeplugins/ 而不是默认的Ubuntu /usr/libexec。没有此更改,kubelet无法安装pvc 。
diff --git a/cluster/examples/kubernetes/ceph/operator.yaml b/cluster/examples/kubernetes/ceph/operator.yamlindex 73cde2e..33f45c8 100755--- a/cluster/examples/kubernetes/ceph/operator.yaml+++ b/cluster/examples/kubernetes/ceph/operator.yaml@@ -431,8 +431,8 @@ spec:# - name: AGENT_MOUNT_SECURITY_MODE# value: "Any"# Set the path where the Rook agent can find the flex volumes- # - name: FLEXVOLUME_DIR_PATH- # value: "" + - name: FLEXVOLUME_DIR_PATH+ value: "/etc/kubernetes/volumeplugins"# Set the path where kernel modules can be found# - name: LIB_MODULES_DIR_PATH# value: ""
3.然后,我必须指定要在deviceFilter中使用的设备。我的附加磁盘始终位于/dev/sdc上
diff --git a/cluster/examples/kubernetes/ceph/cluster.yaml b/cluster/examples/kubernetes/ceph/cluster.yamlindex 48cfeeb..0c91c48 100755a/cluster/examples/kubernetes/ceph/cluster.yamlb/cluster/examples/kubernetes/ceph/cluster.yaml-227,7 +227,7 @@ spec:storage: # cluster level storage configuration and selectionuseAllNodes: trueuseAllDevices: falsedeviceFilter:deviceFilter: "^sdc"location:config:
4.安装后,我使用以下配置创建了Ceph块池和存储类
apiVersion: ceph.rook.io/v1kind: CephBlockPoolmetadata:name: replicapoolnamespace: rook-cephspec:failureDomain: hostreplicated:size: 3---apiVersion: storage.k8s.io/v1kind: StorageClassmetadata:name: rook-ceph-blockprovisioner: ceph.rook.io/blockparameters:blockPool: replicapoolclusterNamespace: rook-cephfstype: xfsreclaimPolicy: Retain
5。最后,我通过以下部署工具检查状态:https://github.com/rook/rook/blob/master/Documentation/ceph-toolbox.md
ceph statuscluster:id: bee70a10-dce1-4725-9285-b9ec5d0c3a5ehealth: HEALTH_OKservices:mon: 3 daemons, quorum c,b,amgr: a(active)osd: 3 osds: 3 up, 3 indata:pools: 0 pools, 0 pgsobjects: 0 objects, 0 Busage: 3.0 GiB used, 3.0 TiB / 3.0 TiB availpgs:[root@aks-agentpool-27654233-0 /]#[root@aks-agentpool-27654233-0 /]#[root@aks-agentpool-27654233-0 /]# ceph osd status+----+--------------------------+-------+-------+--------+---------+--------+---------+-----------+| id | host | used | avail | wr ops | wr data | rd ops | rd data | state |+----+--------------------------+-------+-------+--------+---------+--------+---------+-----------+| 0 | aks-agentpool-27654233-0 | 1025M | 1021G | 0 | 0 | 0 | 0 | exists,up || 1 | aks-agentpool-27654233-1 | 1025M | 1021G | 0 | 0 | 0 | 0 | exists,up || 2 | aks-agentpool-27654233-2 | 1025M | 1021G | 0 | 0 | 0 | 0 | exists,up |+----+--------------------------+-------+-------+--------+---------+--------+---------+-----------+
优点
-
在大型生产环境中运行的强大存储
-
Rook使生命周期管理变得更加简单。
缺点
-
复杂且更重,甚至不适合在公共云中运行。最好只在配置正确的硬件群集上运行。
Longhorn
Longhorn是Rancher开发的用于K8s的云原生分布式块存储。它主要是为微服务用例设计的。它为每个块设备卷创建一个专用的存储控制器,并跨存储在多个节点上的多个副本同步复制该卷。Longhorn在附加了卷的节点上创建了Longhorn Engine,并在复制了卷的节点上创建了副本。与其他存储方案类似,整个控制平面正常运行,而数据平面由K8s编排。它是完全开源的。有趣的是,OpenEBS Jiva后端实际上是基于Longhorn的,或者至少最初是基于Longhorn的。主要区别在于Longhorn使用TCMU Linux驱动程序,而OpenEBS Jiva使用的是gotgt。
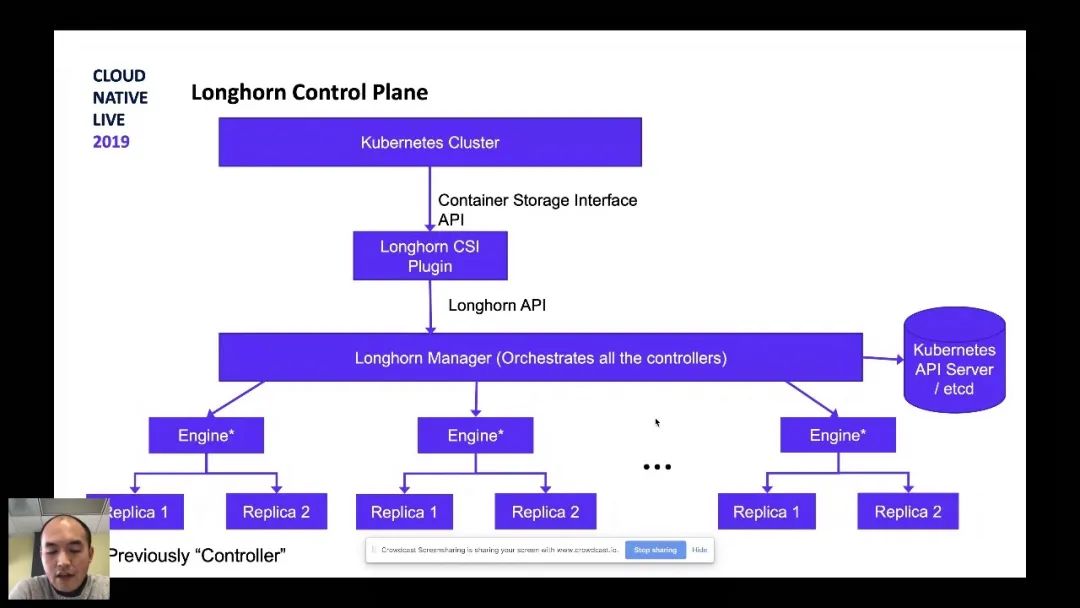
如何在AKS上获取它?当然也可以轻松安装到AKS,只需要运行一个命令,它将所有组件安装到我的AKS集群中
$ kubectl apply -f https://raw.githubusercontent.com/longhorn/longhorn/master/deploy/longhorn.yaml$ kubectl -n longhorn-system get poNAME READY STATUS RESTARTS AGEcsi-attacher-7965bb8b59-c4g2c 1/1 Running 0 116scsi-attacher-7965bb8b59-jqk9t 1/1 Running 0 116scsi-attacher-7965bb8b59-qrxl6 1/1 Running 0 116scsi-provisioner-5896666d9b-9lss2 1/1 Running 0 115scsi-provisioner-5896666d9b-v7wwd 1/1 Running 0 115scsi-provisioner-5896666d9b-vsq6v 1/1 Running 0 115scsi-resizer-98674fffd-27wgb 1/1 Running 0 115scsi-resizer-98674fffd-q6scx 1/1 Running 0 115scsi-resizer-98674fffd-rr7qc 1/1 Running 0 115sengine-image-ei-ee18f965-5npvk 1/1 Running 0 2m44sengine-image-ei-ee18f965-9lp7w 1/1 Running 0 2m44sengine-image-ei-ee18f965-h7b4x 1/1 Running 0 2m44sinstance-manager-e-27146777 1/1 Running 0 2m42sinstance-manager-e-58362831 1/1 Running 0 2m40sinstance-manager-e-6043871c 1/1 Running 0 2m43sinstance-manager-r-5cdb90bf 1/1 Running 0 2m40sinstance-manager-r-cb47162a 1/1 Running 0 2m41sinstance-manager-r-edd5778b 1/1 Running 0 2m42slonghorn-csi-plugin-7xzw9 2/2 Running 0 115slonghorn-csi-plugin-m8cp4 2/2 Running 0 115slonghorn-csi-plugin-wzgp8 2/2 Running 0 115slonghorn-driver-deployer-699db744fd-8j6q6 1/1 Running 0 3m8slonghorn-manager-c5647 1/1 Running 1 3m10slonghorn-manager-dlsmc 1/1 Running 0 3m10slonghorn-manager-jrnfx 1/1 Running 1 3m10slonghorn-ui-64bd57fb9d-qjmsl 1/1 Running 0 3m9s
2.将带有ext4文件系统的/dev/sdc1挂载到/var/lib/longhorn,这是卷存储的默认路径。最好在Longhorn安装之前将磁盘安装到那里。
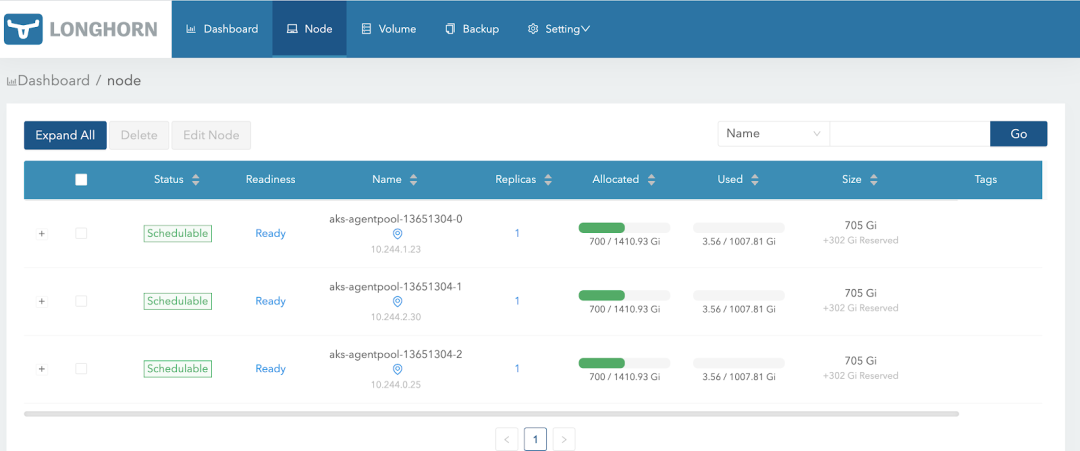
Longhorn中节点磁盘配置的屏幕截图
3.最后一步是创建一个具有3个副本定义的默认存储类。
# kubectl create -f https://raw.githubusercontent.com/longhorn/longhorn/master/examples/storageclass.yamlkind: StorageClassapiVersion: storage.k8s.io/v1metadata:name: longhornprovisioner: driver.longhorn.ioallowVolumeExpansion: trueparameters:numberOfReplicas: "3"staleReplicaTimeout: "2880" # 48 hours in minutesfromBackup: ""
优点
-
开源的
-
云原生存储,它可以在硬件集群和公共云上运行。
-
易于部署,它只需要一个命令,并且“开箱即用”。
-
自动卷备份/还原到S3
缺点
-
它使用标准文件系统(ext4或xfs)到/var/lib/longhorn的挂载点。每个卷就像一个磁盘文件。它可以随着许多控制器副本进行扩展,从而带来额外的网络开销。类似于我为OpenEBS Jiva描述的内容。
-
卷的挂载有时会花费很长时间(几分钟),并且会显示最终从中恢复的错误。
OpenEBS MayaStor
上文有介绍OpenEBS使用cStor的方案,其性能结果确实很差。但是一年半后的时间,OpenEBS团队引入了一个名为MayStor的新后端。
这是用Rust编写的云原生声明性数据平面,由2个组件组成:
-
以CSI概念和数据平面实现的控制平面。与以前的后端相比,主要区别在于利用NVMe而不是NVMe-oF,这有望为存储敏感型工作负载提供更好的IOPS和延迟价值。
-
这种存储设计的另一个优点是,它在主机用户空间中完全用尽了内核,并消除了由不同Linux发行版中可用的各种内核引起的差异。它根本不依赖于内核进行访问。下面的链接中,详细介绍了MayStor的设计说明。
https://blog.mayadata.io/openebs/mayastor-crossing-the-chasm-to-nvmf-infinity-and-beyond
如何在AKS上获取它?在AKS上进行安装也非常简单,我遵循了他们的快速入门指南。
-
我必须在AKS群集中的每个节点上用512个数字配置2MB的大页面。
echo 512 | sudo tee /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages
但是我决定通过下面的k8s daemonset强制执行它们,而不是通过ssh进入我的每个实例。
apiVersion: apps/v1kind: DaemonSetmetadata:name: hugepages-ensurenamespace: mayastorlabels:app: hugepages-ensurespec:selector:matchLabels:name: hugepages-ensureupdateStrategy:type: OnDeletetemplate:metadata:name: hugepages-ensurelabels:name: hugepages-ensureapp: hugepages-ensurespec:containers:name: shellimage: busybox:latestimagePullPolicy: IfNotPresentcommand:/bin/shargs:-c"while true; do echo 512 | tee /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages;grep HugePages /proc/meminfo; sleep 6000; done"volumeMounts:mountPath: /host-rootname: host-rootsecurityContext:privileged: truednsPolicy: ClusterFirstWithHostNethostNetwork: truevolumes:name: host-roothostPath:path: /
2.我必须标记我的存储节点VM。
kubectl label node aks-agentpool-13651304-0 openebs.io/engine=mayastorlabeledkubectl label node aks-agentpool-13651304-1 openebs.io/engine=mayastorlabeledkubectl label node aks-agentpool-13651304-2 openebs.io/engine=mayastorlabeled
3.然后,我应用了MayaStor存储库中指定的所有清单。
https://github.com/openebs/Mayastor/tree/develop/deploy
kubectl create -f nats-deployment.yamlkubectl create -f csi-daemonset.yamlkubectl create -f mayastorpoolcrd.yamlkubectl create -f moac-rbac.yamlkubectl create -f moac-deployment.yamlkubectl create -f mayastor-daemonset.yamlkubectl get po -n mayastorNAME READY STATUS RESTARTS AGEhugepages-ensure-5dr26 1/1 Running 0 47hhugepages-ensure-tpth6 1/1 Running 0 47hhugepages-ensure-z9mmh 1/1 Running 0 47hmayastor-csi-7rf2l 2/2 Running 0 47hmayastor-csi-hbqlb 2/2 Running 0 47hmayastor-csi-jdw7k 2/2 Running 0 47hmayastor-g9gnl 1/1 Running 7 47hmayastor-j7j4q 1/1 Running 4 47hmayastor-kws9r 1/1 Running 4 47hmoac-7d487fd5b5-hfvhq 3/3 Running 0 41hnats-b4cbb6c96-8drv4 1/1 Running 0 47h
4.当所有内容都在运行时,您可以开始创建用于卷置备的存储池。在我的情况下,我创建了3个存储池,每个节点有一个磁盘。
cat <apiVersion: openebs.io/v1alpha1kind: MayastorPoolmetadata:name: pool-on-node-1namespace: mayastorspec:disks:/dev/sdcnode: aks-agentpool-13651304-1EOFkubectl -n mayastor get MayastorPoolNAME NODE STATE AGEaks-agentpool-13651304-0 online 40haks-agentpool-13651304-1 online 46haks-agentpool-13651304-2 online 46h
5.在继续进行StorageClass定义之前,检查每个存储池的状态很重要。状态必须可见。
kubectl -n mayastor describe msp pool-on-node-1Name: pool-on-node-1Namespace: mayastorLabels:API Version: openebs.io/v1alpha1Kind: MayastorPoolMetadata:Creation Timestamp: 2020-08-19T0852ZGeneration: 1Resource Version: 45513Self Link: /apis/openebs.io/v1alpha1/namespaces/mayastor/mayastorpools/pool-on-node-1UID: 5330a0be-bebe-445a-9285-856511e318dcSpec:Disks:/dev/sdcNode: aks-agentpool-13651304-1Status:Capacity: 1098433691648Disks:aio:///dev/sdcReason:State: onlineUsed: 1073741824Events:
6.该过程的最后一步是StorageClass定义,在其中,我配置了3个副本以具有与之前的存储解决方案相同的测试环境。
cat <kind: StorageClassapiVersion: storage.k8s.io/v1metadata:name: mayastorparameters:repl: '3'protocol: 'iscsi'provisioner: io.openebs.csi-mayastorEOF
完成这些步骤后,我便能够通过K8s PVC动态预配新卷。
优点
-
具有强大社区支持的开源
-
云原生存储,它可以在硬件集群和公共云上运行。
-
与仅具有一个队列的SCSI相比,NVMe的使用旨在实现高度并行性,并且可以具有64K队列。
-
它使用NVMe-oF作为传输方式,可以在各种传输方式(nvmf,uring,pcie)上工作,并且完全在用户空间(目标用户和发起者)中完成。在用户空间中运行可以避免进行大量的系统调用,避免后期崩溃/崩溃等。而且它与内核无关,因此跨云或物理环境的linux类型之间没有区别。
缺点
-
早期版本-OpenEBS MayaStor的版本为0.3,因此它仍然存在一些限制和稳定性问题。但是,它们走在正确的轨道上,并且在几个月后,它可能是在K8中存储的首选。
-
需要在Kubernetes节点上支持2MB的大页面。但是,与1GB的大页面相比,几乎在所有物理或虚拟环境中都可用。
性能测试结果
重要说明:单个存储性能测试的结果无法单独评估,但必须将测量结果相互比较。这里多种执行比较测试的方法是相对比较简单的。
为了进行验证,我使用了与Azure AKS 3节点群集和每个实例均附有1TB高级SSD托管磁盘的完全相同的实验室。
为了运行测试,我决定使用称为Dbench的负载测试器。这是Pod的K8s部署清单,在其中运行FIO,这是带有8个测试用例的Flexible IO Tester。在Docker映像的入口点中指定了测试:
-
随机读写带宽
-
随机读写IOPS
-
读写延迟
-
顺序读/写
-
混合读/写IOPS
首先,我运行了Azure PVC测试以获得与去年进行比较的基准。结果几乎相同,因此我们可以假设条件保持不变,并且使用相同的存储版本将获得相同的数量。可从https://gist.github.com/pupapaik/76c5b7f124dbb69080840f01bf71f924获得来自2019年所有测试的更新的完整测试输出以及新的MayStor和Longhorn测试
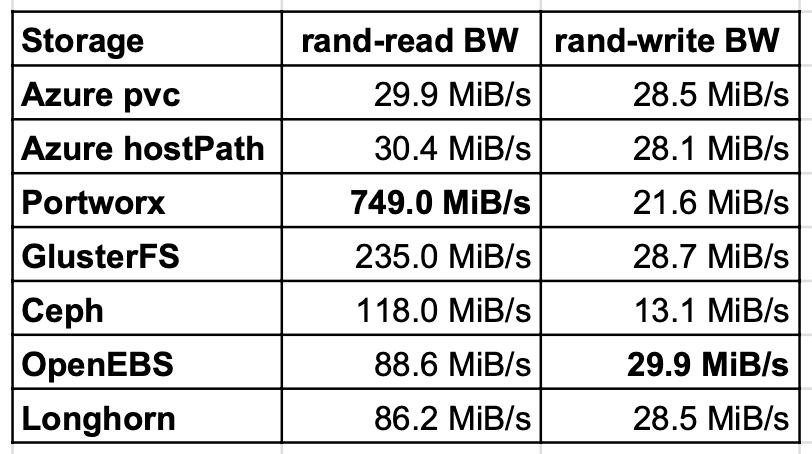
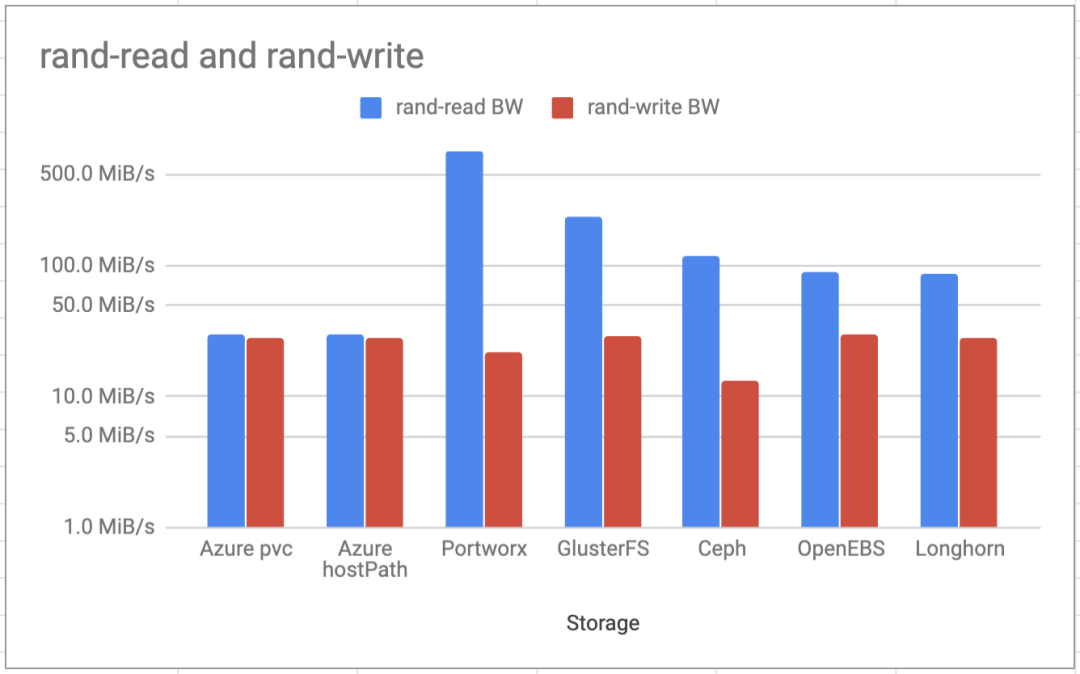
随机读写带宽
随机读取测试表明,GlusterFS,Ceph和Portworx的读取性能比Azure本地磁盘上的主机路径好几倍。OpenEBS和Longhorn的性能几乎是本地磁盘的两倍。原因是读取缓存。对于OpenEBS,写入速度最快,但是Longhorn和GlusterFS的值也几乎与本地磁盘相同。
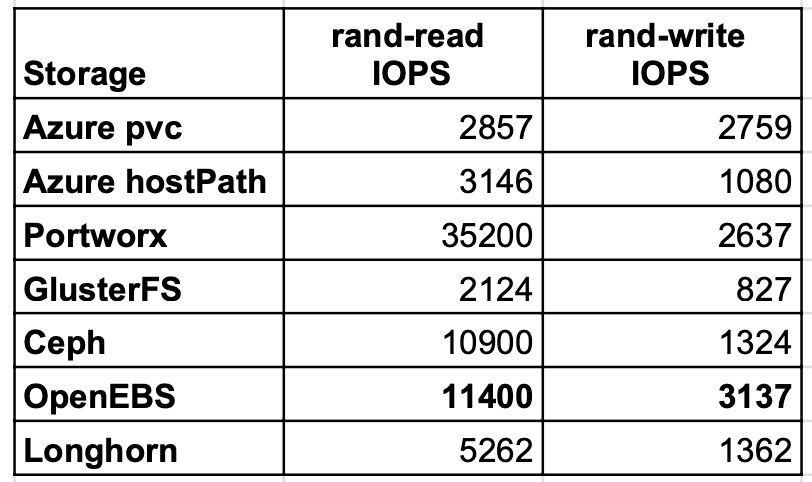
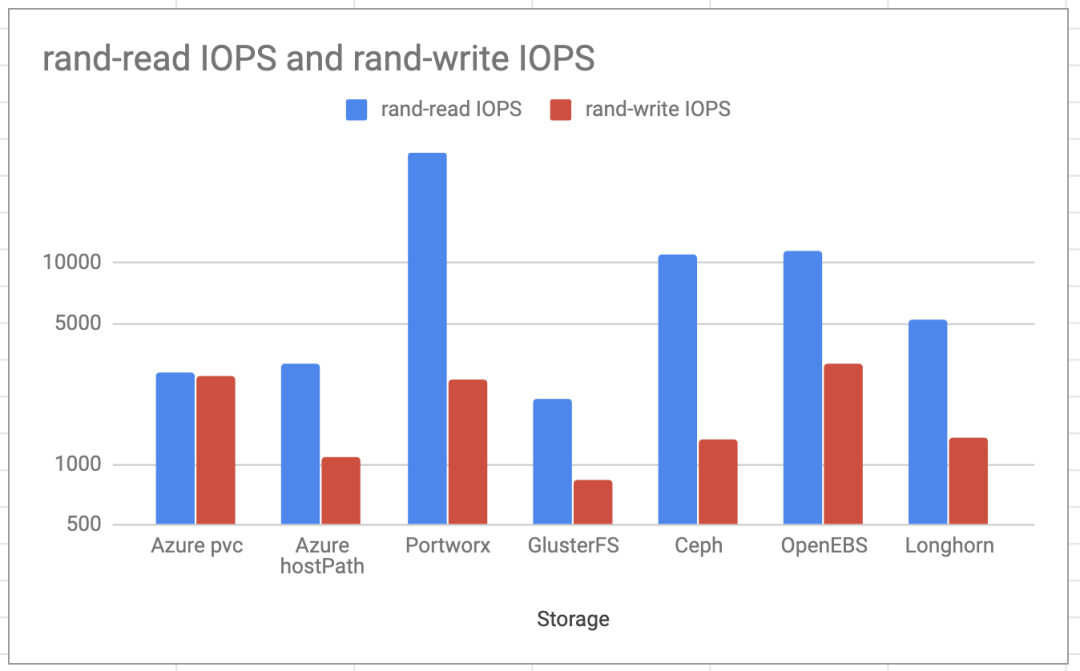
随机读写IOPS
Portworx和OpenEBS在随机IOPS测试中表现出最好的结果。这次,OpenEBS在写入方面的IOPS比本地Azure PVC更好,这在技术上几乎是不可能的。它很可能与在测试用例运行的不同时间处的Azure存储负载有关。
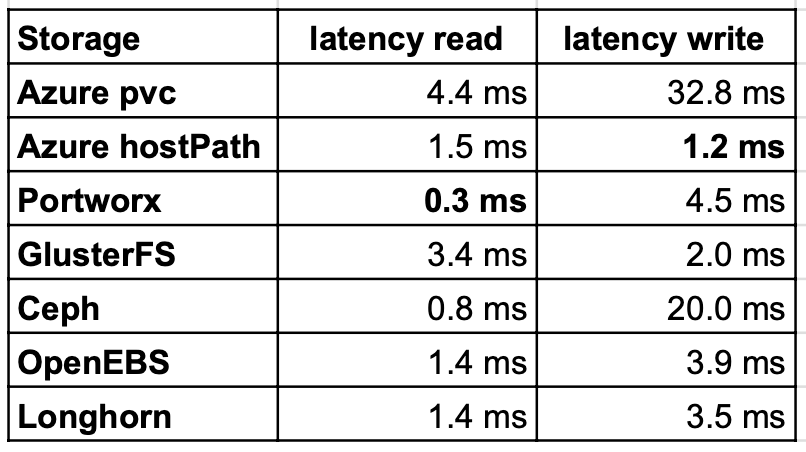
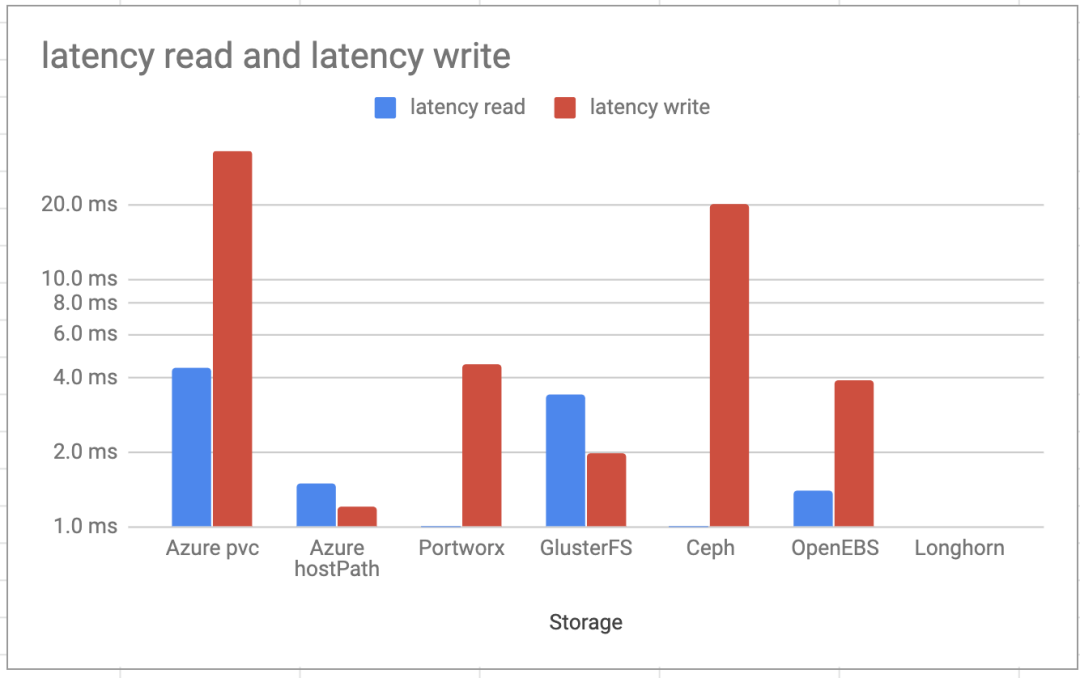
读写延迟
延迟读取获胜者与上次相同。LongHorn和OpenEBS几乎是PortWorx的两倍。这仍然不错,因为本机Azure pvc比大多数其他经过测试的存储要慢。但是,在OpenEBS和Longhorn上写入期间的延迟更好。GlusterFS仍然比其他存储要好。
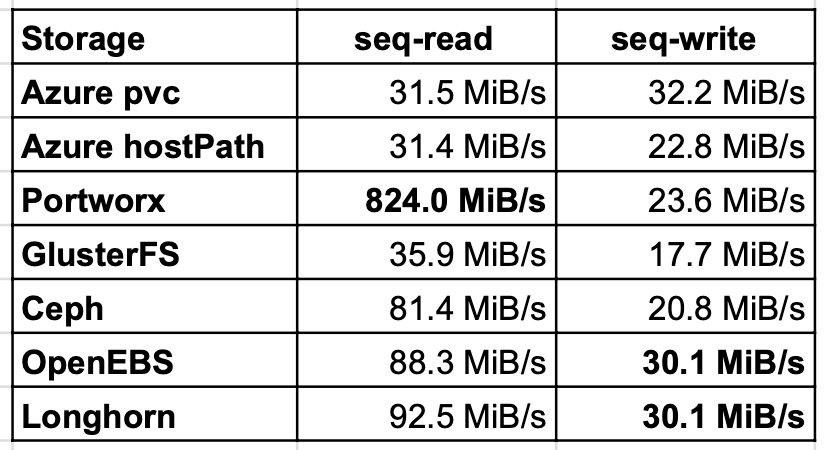
顺序读/写
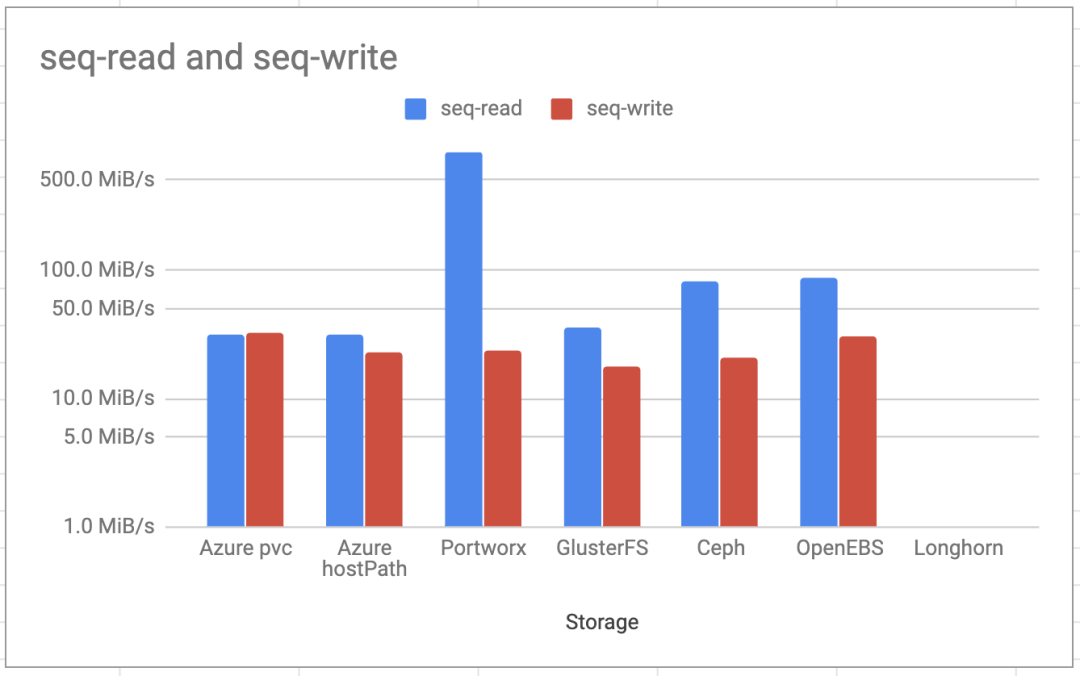
顺序读/写测试显示的结果与随机测试相似,但是Ceph的读性能比GlusterFS高2倍。写入结果几乎都处于同一水平,OpenEBS和Longhorn达到了相同的水平。
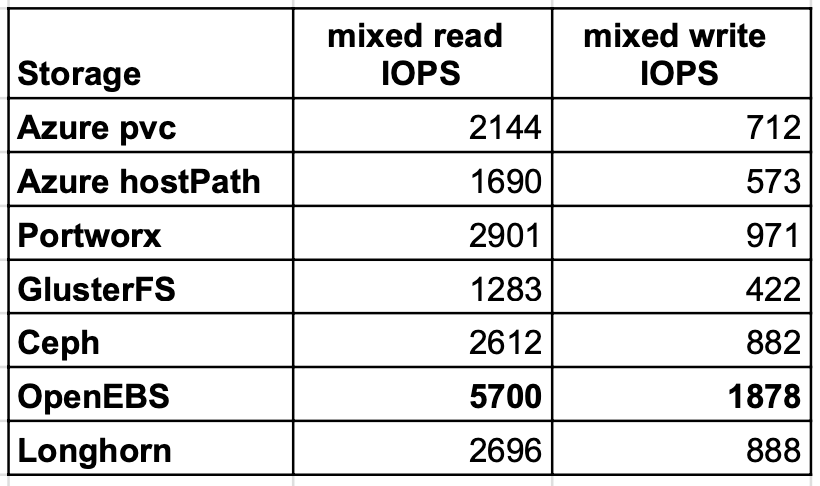
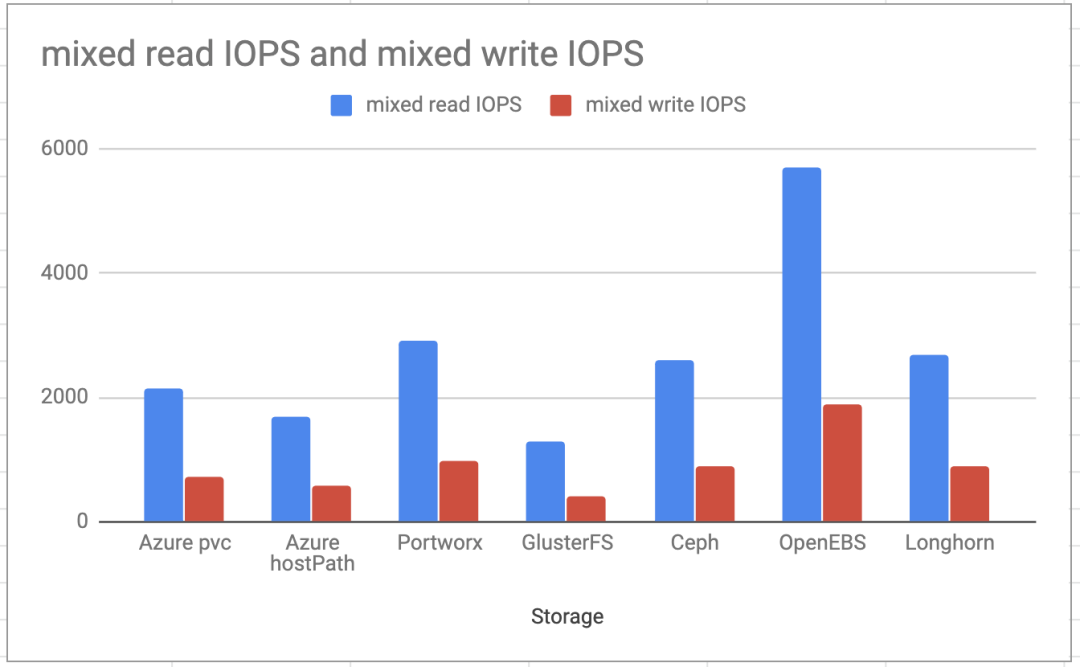
混合读/写IOPS
最后一个测试用例验证了混合读写IOPS,在读写方面,OpenEBS交付的速度几乎是PortWorx或Longhorn的两倍。
结论
该文章验证了一个开放源代码项目在一年内可以有多大的变化!作为演示,让我们看一下在完全相同的环境下,OpenEBS cStor和OpenEBS MayaStor的IOPS的比较。
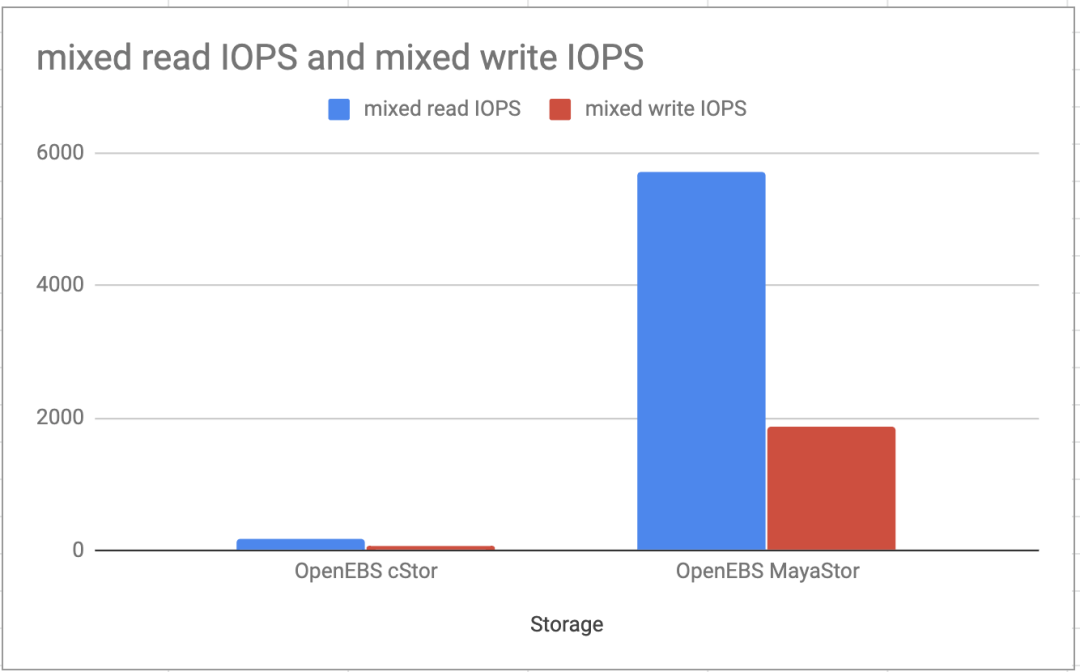
OpenEBS cStor和MayaStor之间的混合读写IOPS比较
在选择存储空间时,请仅将结果作为标准之一,不要仅根据文章做出最终判断。我们可以从上述的测试中得出以下结论:
-
Portworx和OpenEBS是AKS上最快的容器存储。
-
围绕NVMe的稳健设计,OpenEBS似乎已成为最好的开源容器存储选项之一。
-
对于硬件集群,Ceph是最好的开源后端存储。对于公共云而言,操作过于复杂,最终与默认的云存储类相比并没有增加太多价值。
-
对于简单的块存储用例,Longhorn绝对是有效的选择,它与OpenEBS Jiva后端非常相似。
当然,以上只是评测容器存储选项的一种方法。存储评测应该还包括缩放和稳定性等。后期将密切关注CNCF存储领域中其他正在发展的项目,并从性能测试和扩展中带来跟多有趣的更新。
参考链接
1.https://medium.com/volterra-io/kubernetes-storage-performance-comparison-9e993cb27271
2.https://medium.com/volterra-io/kubernetes-storage-performance-comparison-v2-2020-updated-1c0b69f0dcf4
责任编辑:xj
原文标题:K8s最常见的存储解决方案之性能评测
文章出处:【微信公众号:存储社区】欢迎添加关注!文章转载请注明出处。
-
一文带你彻底搞懂K8s网络2026-02-06 901
-
K8s存储类设计与Ceph集成实战2025-08-22 1273
-
什么是 K8S,如何使用 K8S2025-06-25 276
-
k8s和docker区别对比,哪个更强?2024-12-11 1662
-
k8s云原生开发要求2024-10-24 1491
-
k8s是什么意思?kubeadm部署k8s集群(k8s部署)|PetaExpres2023-07-19 1953
-
mysql部署在k8s上的实现方案2022-09-26 3789
-
K8S(kubernetes)学习指南2022-06-29 935
-
简单说明k8s和Docker之间的关系2021-06-24 4457
-
Docker不香吗为什么还要用K8s2021-06-02 4374
-
k8s容器运行时演进历史2021-02-02 2846
-
k8s volume中的本地存储和网络存储2020-03-25 2003
-
OpenStack与K8s结合的两种方案的详细介绍和比较2018-10-14 28685
-
全面提升,阿里云Docker/Kubernetes(K8S) 日志解决方案与选型对比2018-02-28 3616
全部0条评论

快来发表一下你的评论吧 !
