

深度学习:四种利用少量标注数据进行命名实体识别的方法
描述
导读
近年来,深度学习方法在特征抽取深度和模型精度上表现优异,已经超过了传统方法,但无论是传统机器学习还是深度学习方法都依赖大量标注数据来训练模型,而现有的研究对少量标注数据学习问题探讨较少。本文将整理介绍四种利用少量标注数据进行命名实体识别的方法。
面向少量标注数据的NER方法分类
基于规则、统计机器学习和深度学习的方法在通用语料上能取得良好的效果,但在特定领域、小语种等缺乏标注资源的情况下,NER 任务往往得不到有效解决。然而迁移学习利用领域相似性,在领域之间进行数据共享和模型共建,为少量标注数据相关任务提供理论基础。本文从迁移的方法出发,按照知识的表示形式不同,将少量标注数据NER 方法分为基于数据增强、基于模型迁移、基于特征变换、基于知识链接的方法。如图1所示,在这 20 多年间,四种方法的发文数量基本呈上升趋势,整体而言,当前的研究以数据增强、模型迁移为主,而其他的方法通常配合前两种方法使用,在研究中也值得关注。
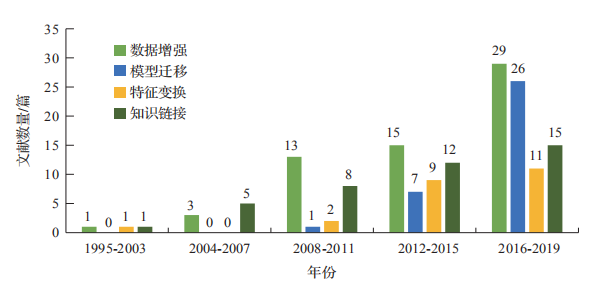
图1 1995年-2019年四种方法的使用情况
基于数据增强的NER方法
数据增强的方法即:在少量数据集训练模型导致过拟合时,通过样本选择、权重调整等策略以创建高质量样本集,再返回分类器中迭代学习,使之能够较好地完成学习任务的方法。
(1)样本选择。在面向少量标注数据时,最直接的策略是挑选出高质量样本以扩大训练数据。其中,样本选择是数据增强式 NER 的核心模块,它通过一定的度量准则挑选出置信度高、信息量大的样本参与训练,一种典型的思路为主动学习采样,例如 Shen 等利用基于“不确定性”标准,通过挖掘实体内蕴信息来提高数据质量。在实践中,对于给定的序列 X=(x1, x2,…xi) 和标记序列Y=(y1, y2,…yi),x 被预测为 Y 的不确定性可以用公式(1)来度量,其中 P(y) 为预测标签的条件分布概率,M 为标签的个数,n 为序列的长度:
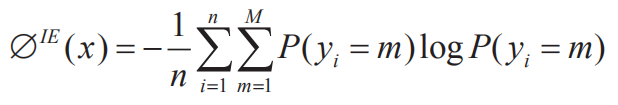
为了验证主动学习采样的性能,在人民日报(1998 年)语料中进行实验,共迭代十次,其中 Random 为迭代中随机采样,ALL 为一次训练完所有数据的结果,Active-U 为利用数据增强的结果。实验结果(如图 2)表明,利用数据增强方法在第 7 次迭代中就能达到拟合,节省了 30% 的标注成本。
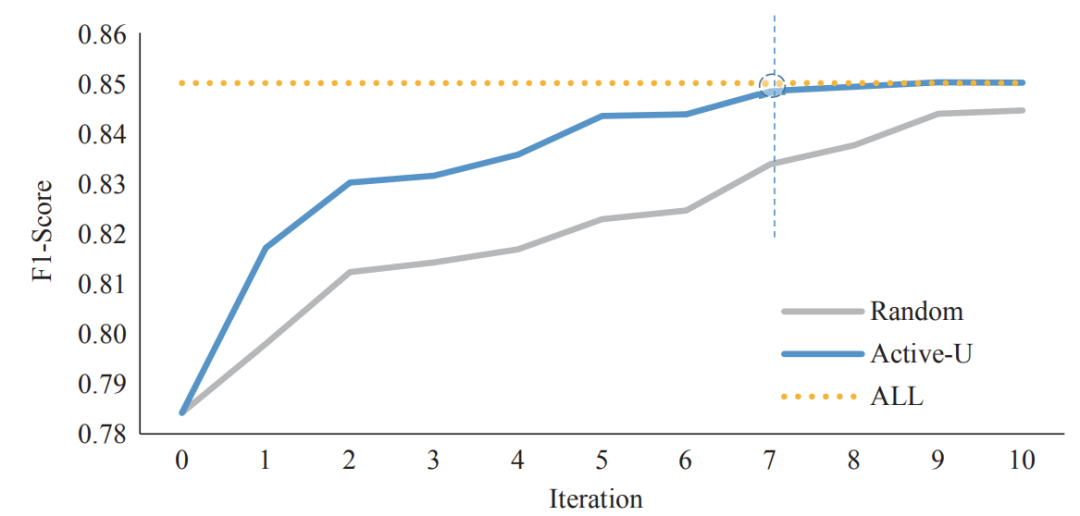
图2 基于数据增强方法的实例
也有不同学者利用其他的度量准则,例如高冰涛等人通过评估源域样本在目标领域中的贡献度,并使用单词相似性和编辑距离,在源域样本集和目标样本集上计算权值来实现迭代学习。Zhang 等人充分考虑领域相似性,分别进行域区分、域依赖和域相关性计算来度量。这些方法利用无监督模式通过降低统计学习的期望误差来对未标记样本进行优化选择,能够有效减少标注数据的工作量。此外,半监督采样也是一种新的思路。例如在主动学习的基础上加入自学习(Self-Training)、自步学习(Self-Paced Learning,SPL)过程,这些方式通过对噪声样本增大学习难度,由易到难地控制选择过程,让样本选择更为精准。
(2)分类器集成。在数据增强中,训练多个弱分类器来获得一个强分类器的学习方式也是一种可行的思路。其中典型的为 Dai 等人提出集成式 TrAdaBoost 方法,它扩展了 AdaBoost 方法,在每次迭代的过程中,通过提高目标分类样本的采样权重、降低误分类实例样本的权重来提高弱分类器的学习能力。TrAdaBoost 利用少量的标签数据来构建对源域标签数据的样本增强,最后通过整合基准弱分类器为一个强分类器来进行训练,实现了少样本数据的学习。之后的研究针对 TrAdaBoost 进行了相应的改进也取得了不错的效果。例如,王红斌等人在分类器集成中增加迁移能力参数,让模型充分表征语义信息,在 NER 中提高精度也能显著减少标注成本。
基于模型迁移的NER方法
基于模型迁移的基本框架如图 3 所示,其核心思想是利用分布式词表示构建词共享语义空间,然后再迁移神经网络的参数至目标领域,这是一种固定现有模型特征再进行微调(Fine-Tuning) 的方法,在研究中共享词嵌入和模型参数的迁移对 NER 性能产生较大影响。
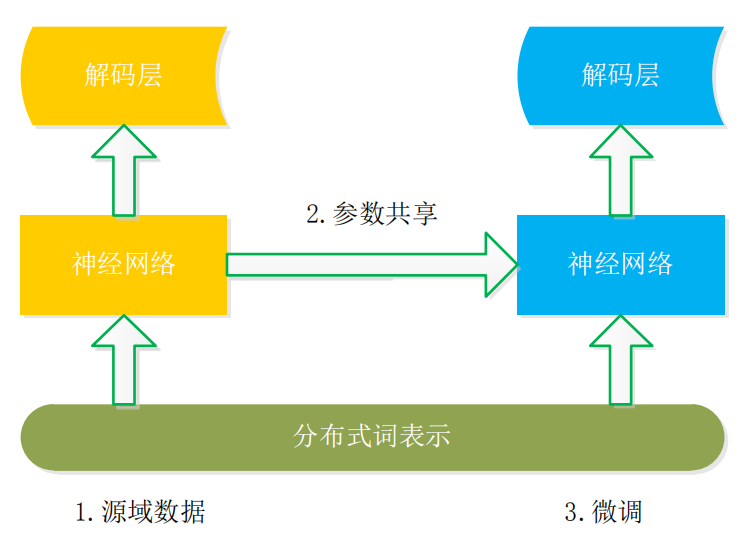
图3 模型迁移基本结构
(1)共享词嵌入。在 NLP 中,前期工作通常会借助语言预训练模型学习文本的词义信息,这种方式构建了公共的词嵌入表示空间,词嵌入在 NER 中通常作为输入。词向量是共享词嵌入的初步形式,此后,ELMo模型利用上下文信息的方式能解决传统词向量不擅长的一词多义问题,还能在一定程度上对词义进行预测逐渐受到人们关注。而 2018 年谷歌提出的 BERT预训练模型更是充分利用了词义和语义特性,BERT 是以双向 Transformer为编码器栈的语言模型,它能强有力地捕捉潜在语义和句子关系,基于 BERT 的 NER 在多个任务上也取得 state-of-the-art,其基本网络结构如图4所示。
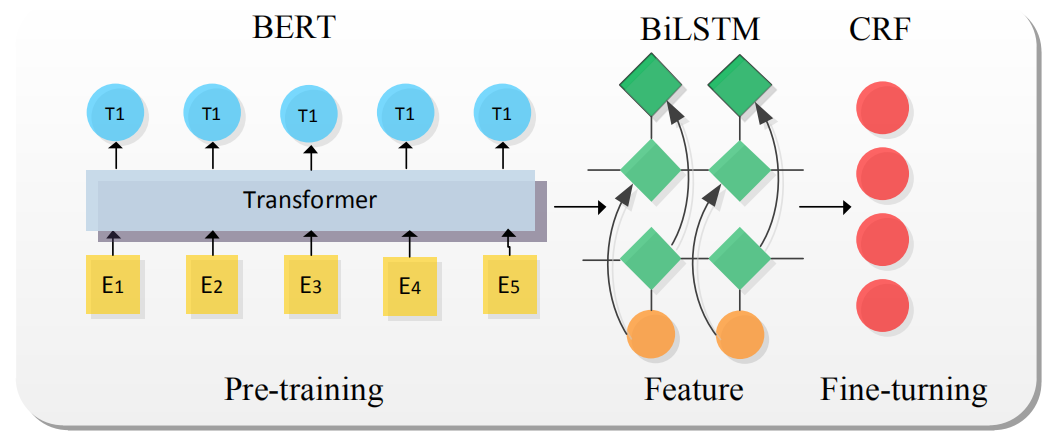
图4 模型迁移的基础方法-BERT-BiLSTM-CRF
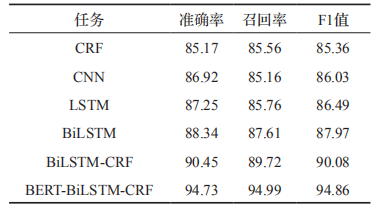
其中 BERT 作为语义表示输入,BiLSTM抽取特征,CRF 获取概率最大标签。与传统的NER 模型相比,该模型最关键的是 BERT 语言模型的引入,BERT 通过无监督建模的方式学习海量互联网语义信息,能充分表征实体的语义信息。在人民日报(1998年)语料中进行实验,实验结果(如表 1)表明,基于 BERT 的预训练迁移学习模型能有效提高分类的准确率。
表1 BERT-BiLSTM-CRF与其他方法的比较
(2)共享参数。共享词嵌入侧重于词义的表示,而共享参数则侧重于模型参数的迁移。例如,Jason 等人从神经网络迁移机制以及迁移哪些层进行大量实验,实验结论显示浅层网络学习知识的通用特征,具有很好的泛化能力,当迁移到第 3 层时性能达到饱和,继续迁移会导致“负迁移”的产生。Giorgi 等人基 于 LSTM 进行网络权重的迁移,首先将源领域模型参数迁移至目标领域初始化,之后进行微调使适应任务需要。而 Yang 等人从跨领域、跨应用、跨语言迁移出发测试模型迁移的可行性, 在 一 些 benchmarks 上实现了 state-of-the-art。整体而言,在处理 NER 任务时良好的语义空间结合深度模型将起到不错的效果,在迁移过程中模型层次的选择和适应是难点。
基于特征变换的NER方法
在面向少量标注数据 NER 任务时,我们希望迁移领域知识以实现数据的共享和模型的共建,在上文中我们从模型迁移的角度出发,它们在解决领域相近的任务时表现良好,但当领域之间存在较大差异时,模型无法捕获丰富、复杂的跨域信息。因此,在跨领域任务中,一种新的思路是在特征变换上改进,从而解决领域数据适配性差的问题。基于特征变换的方法是通过特征互相转移或者将源域和目标域的数据特征映射到统一特征空间,来减少领域之间差异的学习过程,下面主要从特征选择和特征映射的角度进行探讨。
(1)特征选择。即通过一定的度量方法选取相似特征并转换,在源域和目标域之间构建有效的桥梁的策略。例如 Daume 等人通过特征空间预处理实现目标域和源域特征组合,在只有两个域的任务中,扩展特征空间 R^F 至 R^3F,对应于域问题,扩展特征空间至 R^(K+1)F。然而当 Yi 与 YJ 标签空间差异较大时,这种线性组合效果可能不理想,Kim 等人从不同的角度出发,进行标签特征的变换,第一种是将细粒度标签泛化为粗粒度标签。例如源域标签中
(2)特征映射。即为了减少跨领域数据的偏置,在不同领域之间构建资源共享的特征空间,并将各领域的初始特征映射到该共享空间上。利用预测的源标签嵌入至目标领域是一种常见策略。例如,Qu 等人从领域和标签差异出发,首先训练大规模源域数据,再度量源域和目标域实体类型相关性,最后通过模型迁移的方式微调。其基本步骤为:
1、通过 CRF学习大规模数据的知识;
2、使用双层神经网络学习源域与目标域的命名实体的相关性;
3、利用 CRF 训练目标域的命名实体。
实验结果显示相较于 Baseline 方法 Deep-CRF,TransInit 方法能提高 160% 的性能。
标签嵌入的方式在领域之间有较多共享标签特征时迁移效果不错,但是这种假设在现实世界中并不普遍。一种新的思路是在编解码中进行嵌入适配(如图 5),这种方式利用来自预训练源模型的参数初始化 Bi-LSTM-CRF 基础模型,并嵌入词语、句子和输入级适配。具体而言,在词级适配中,嵌入核心领域词组以解决输入特征空间的领域漂移现象。在句子级适配中,根据来自目标域的标记数据,映射学习过程中捕获的上下文信息。在输出级适配中将来自 LSTM 层输出的隐藏状态作为其输入,为重构的 CRF 层生成一系列新的隐藏状态,进而减少了知识迁移中的损失。
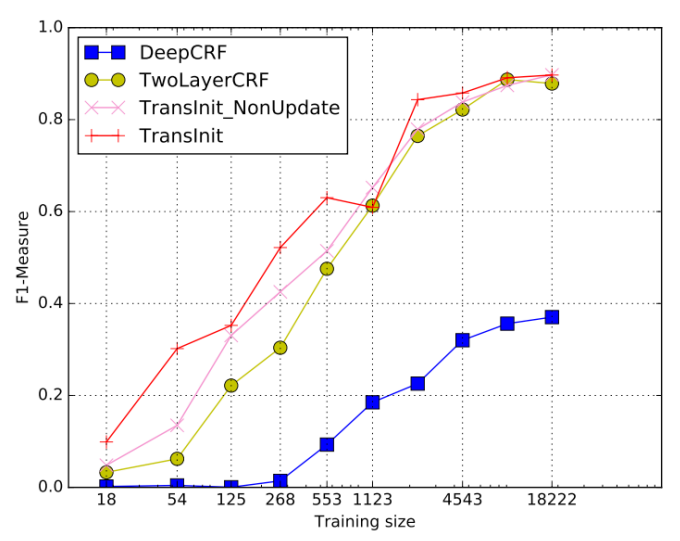
图5 特征变换方法TransInit实验结果
基于知识链接的NER方法
基于知识链接的 NER,即使用本体、知识库等结构化资源来启发式地标记数据,将数据的结构关系作为共享对象,从而帮助解决目标 NER 任务,其本质上是一种基于远程监督的学习方式,利用外部知识库和本体库来补充标注实体。例如 Lee 等人的框架(如图 6),在 Distant supervision 模块,将文本序列与 NE词典中的条目进行匹配,自动为带有 NE 类别的大量原始语料添加标签,然后利用 bagging和主动学习完善弱标签语料,从而实现语料的精炼。一般而言,利用知识库和本体库中的链接信息和词典能实现较大规模的信息抽取任务,这种方法有利于快速实现任务需求。
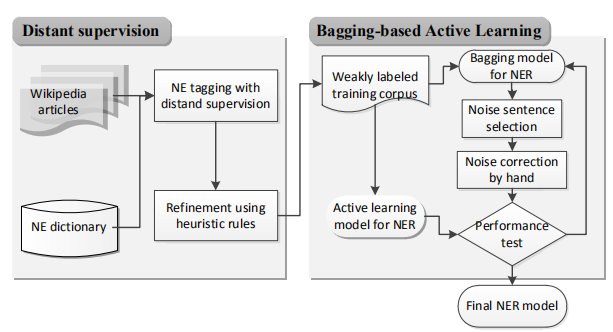
图6 知识链接与数据增强结合模型
(1)基于知识库。这种方式通常借用外部的知识库来处理 NER、关系抽取、属性抽取等任务,在现实世界中如 Dbpedia、YAGO、百度百科等知识库存在海量结构化信息,利用这些知识库的结构化信息框、日志信息可以抽取出海量知识。例如,Richman 等人利用维基百科知识设计了一种 NER 的系统,这种方法利用维基百科类别链接将短语与类别集相关联,然后确定短语的类型。类似地,Pan 等人利用一系列知识库挖掘方法为 200 多种语言开发了一种跨语言的名称标签和链接结构。在实践中,较为普遍的是联合抽取实体和实体关系。例如Ren 等的做法,该方法重点解决领域上下文
无关和远程监督中的噪声问题,其基本步骤为:
1、利用 POS 对文本语料进行切割以获得提及的实体;
2、生成实体关系对;
3、捕获实体与实体关系的浅层语法及语义特征;
4、训练模型并抽取正确的实体及关系。
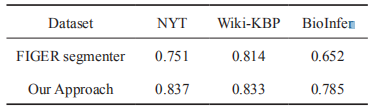
在 NYT 等语料上进行实验(如表 2),基于知识库的方法相较于基线方法有显著提高。
表2 不同语料下实体的F1值
(2)基于本体系统。该方式通过一定的规则,将本体库中的概念映射为实体。例如史树敏等人通过构建的 MPO 本体,首先利用CRF 获得高召回率的实体,再融合规则过滤噪声,最终获得较为精确的匹配模式。相似地,Lima 等人通过开发出 OntoLPER 本体系统,并利用较高的表达关系假设空间来表示与实体—实体关系结构,在这个过程中利用归纳式逻辑编程产生抽取规则,这些抽取规则从基
于图表示的句子模型中抽取特定的实体和实体关系实例。同样地,李贯峰等人首先从 Web网页提取知识构建农业领域本体,之后将本体解析的结果应用在 NER 任务中,使得 NER 的结果更为准确。这些方法利用本体中的语义结构和解析器完成实体的标准化,在面向少量标注的 NER 中也能发挥出重要作用。
四种方法比较
上述所介绍的 4 种面向少量标注的 NER 方法各有特点,本文从领域泛化能力、模型训练速度、对标注数据的需求和各方法的优缺点进行了细致地比较,整理分析的内容如表 3 所示。
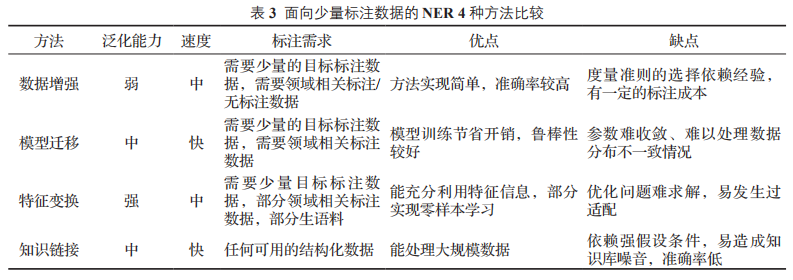
面向少量标注数据 NER,最直接的方法是数据增强,通过优先挑选高质量样本参与训练,这种方法在窄域中能实现较高的准确率。但是针对不同领域所需的策略也不同,领域的泛化能力一般。模型迁移从海量无结构化文本中获取知识,这种方式对目标领域的数据需求较少,只需“微调”模型避免了重新训练的巨大开销,但是它依赖领域的强相关性,当领域差异性太大时,容易产生域适应问题。
相较于模型迁移,特征变换更加注重细粒度知识表示,这种方法利用特征重组和映射,丰富特征表示,减少知识迁移中的损失,在一定程度上能实现“零样本”学习,但是这种方法往往难以求出优化解,过适配现象也会造成消极影响。知识链接能利用任何结构化信息,通过知识库、本体库中的语义关系来辅助抽取目标实体,但是这种方法易产生噪声,实体的映射匹配依赖强假设条件,所需的知识库通常难以满足领域实体的抽取。
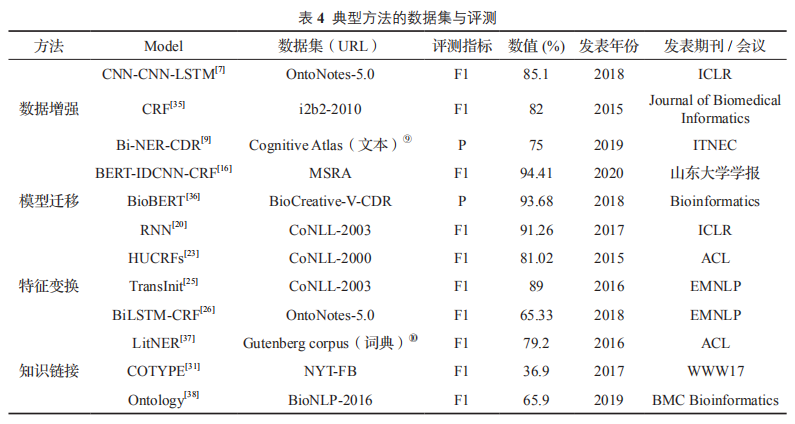
方法评测比较
如表4所示四类面向少量标注数据的典型方法与评测信息如下:
结语
当有大量标注数据可供模型训练时,NER任务往往能够得到很好的结果。但是在一些专业领域比如生物医药领域,标注数据往往非常稀缺,又由于其领域的专业性,需要依赖领域专家进行数据标注,这将大大增加数据的标注成本。而如果只用少量的标注数据就能得到同等效果甚至更好的效果,这将有利于降低数据标注成本。
参考资料:
[1]石教祥,朱礼军,望俊成,王政,魏超.面向少量标注数据的命名实体识别研究[J].情报工程,2020,6(04):37-50.
责任编辑:xj
原文标题:综述 | 少量标注数据下的命名实体识别研究
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
-
HanLP分词命名实体提取详解2019-01-11 3561
-
基于结构化感知机的词性标注与命名实体识别框架2019-04-08 2112
-
HanLP-命名实体识别总结2019-07-31 2278
-
基于神经网络结构在命名实体识别中应用的分析与总结2018-01-18 5388
-
自然语言基础技术之命名实体识别相对全面的介绍2019-04-17 5825
-
思必驰中文命名实体识别任务助力AI落地应用2021-02-22 2923
-
新型中文旅游文本命名实体识别设计方案2021-03-11 1375
-
判断识别高压电缆的四种案例以及判断方法2021-05-13 6721
-
命名实体识别的迁移学习相关研究分析2021-04-02 1528
-
基于字语言模型的中文命名实体识别系统2021-04-08 1012
-
基于神经网络的中文命名实体识别方法2021-06-03 912
-
基于深度学习的自动识别评价对象方法2021-06-10 977
-
关于边界检测增强的中文命名实体识别2021-09-22 4223
-
基于序列标注的实体识别所存在的问题2022-07-28 2979
-
什么是嵌套实体识别2022-09-30 3022
全部0条评论

快来发表一下你的评论吧 !
