

AI:计算机视觉与自然语言处理融合的研究进展
描述
导读
通过语言给予智能体指示使其完成通用性的任务是人工智能领域的愿景之一。近年来有越来越多的学者试图通过融合计算机视觉与自然语言处理领域的相关技术以期实现此目标。
近年来,深度学习方法已经在计算机视觉、自然语言处理和自动语音识别等各个领域得到了广泛而深入的应用,推动了人脸识别、自动驾驶和语音识别等一系列技术的发展和成熟。在很多目标清晰、规则明确的任务比如物体检测、目标分割甚至是围棋、象棋领域达到甚至超越了人类的表现。但是当前深度学习领域的研究往往局限在特定领域甚至特定的任务上,对于环境往往也有许多假设或是限制,与通用人工智能或是自主智能体的目标相去甚远。
像图像描述、视觉问答和文本图像生成等视觉与语言交叉领域的研究,往往缺乏对于环境的理解,而近年来陆续出现的将视觉和语言与行为联系的研究,比如视觉语言导航、具身问答和交互式问答等,不但需要融合视觉与语言技术,还需要智能体针对基于文本的问题,在虚拟的空间环境中进行路径规划和探索,相对而言是对视觉与语言的深度融合。
下面先来了解一下早期研究较多的几个融合视觉与语言的任务。
图像描述
最早被提出的问题是图像描述,即根据给定图片自动生成语言描述。初期解决方案分为图像预处理、特征提取和文本生成三个模块,比如图像算子提取特征,SVM 检测可能存在的目标,根据目标属性生成句子,但是对于目标属性定义的依赖限制了描述的生成。近年来则大多基于深度学习提出解决方案,2015 年谷歌 DeepMind 团队和李飞飞团队分别提出了基于编码—解码框架的show and tell 和 neural talk 模型,均使用 CNN+RNN 的模式;生成对抗网络、深度强化学习和注意力机制也被陆续引入相关研究。随着解决方案的成熟,图像描述任务也不断扩展,比如基于群组的图像描述方法和生成文本的风格化问题等。
视觉问答
视觉问答可以视作图像描述问题的逻辑推理扩展,任务形式通常是,给定一幅图片和基于图片的问题,输出问题的正确答案,包括是或否的二元逻辑问题和多项选择以及图像中的文本信息等。解决方法基本可划分为四类:联合嵌入模型、注意力机制模型、模块化组合模型和知识库增强模型。联合嵌入方法将图像和文字在公共特征空间学习,注意力机制使用局部图像特征对不同区域的特征加权解决噪声问题,模块化组合模型引入不同功能的神经网络模块,知识库增强模型通过外部知识库解决需要先验知识的问题。作为视觉问答的拓展领域视频问答也越来越多受到学者的关注。
文本图像生成
文本图像生成则正好是图像描述的逆向问题,从给定文本描述生成图像。变分自编码器、基于流的生成模型和近似PixelCNN等方法都曾用于解决此问题。但是自生成对抗网络引入文本图像生成以来,因其卓越表现已成为主流方法。当前基于 GAN 的优化方向主要有:其一是调整网络结构,比如增加网络深度或者引入多个判别器,其二是充分利用文本信息,比如注意力机制和 MirrorGAN等工作,其三是增加额外约束,比如 Condition-GAN机制等工作,其四是分阶段生成,比如李飞场景图和语义中间层等工作。同样文本图像生成任务形式也得到了进一步拓展,比如基于多段落生成系列图片的故事可视化任务和文本生成视频等。
视觉对话
视觉对话可以视为图像描述问题的对话扩展,在 2017 年 CVPR 会议上由佐治亚理工学院的 Das A 等人提出,与视觉问答中单次交互不同,视觉对话要求智能体基于视觉内容与人类进行多次交流。具体讲,就是在给定图像、对话历史记录和关于图像问题的条件下,智能体必须基于图像内容,从历史记录中推断上下文,并准确地回答该问题。与此相似的还有‘Guess What?!’任务但是其仅限于答案为“是”或“否”的布尔型问题,Alamri H 等人则进一步引入了视频对话的任务。视觉对话目前的解决方案主要有基于深度强化学习的模型、注意力机制、条件变分自编码器方法和基于神经网络模块的架构等。
多模态机器翻译
多模态机器翻译则是对机器翻译工作的扩展,其目标是给定描述图片的源语言和图片本身,根据文本内容和图像提供的额外信息翻译成目标语言,同时 Specia 定义了两类任务,其一是单句源语言描述图片,其二是多句源语言描述图片,Elliott 等人进一步将任务二扩展到多种源语言(比如关于同一图片英语、法语和德语描述),Wang Xin 等人则进一步把任务扩展到视频层面。研究方向主要有:引入注意力机制,分解任务目标,充分发掘图片的视觉特征,强化学习方法的使用,无监督学习模型的扩展等。
除了以上任务之外,还有定位视频中文本位置的视频文本定位任务,判断文本描述和图片内容是否匹配的视觉蕴涵任务,问题必须基于图片内容进行推理才能回答的视觉推理任务等。包括上述问题在内的大部分早期研究往往是在视觉和语言的层次上不断扩展,比如将图片扩展到视频,从句子扩展到段落等,或者在此基础上加入逻辑层面的推理等。
但在一定意义上讲,上述任务仅仅是计算机视觉和自然语言处理两个任务的弱耦合,甚至部分任务可以把视觉部分和语言部分完全分离地进行训练,将其中一部分的输出作为另一部分的输入就能实现任务的要求,因此没有真正的发掘视觉与语言的内在联系,并且其更多的侧重于特定任务的完成,对于环境的感知是被动甚至缺失的。因此,为了真正发掘视觉与语言的内在联系,在最新的视觉与语言的研究中,加入了行为规划的部分,这使得智能体不但能够综合使用视觉与语言能力,还能够不断通过与环境主动地交互获取所需要的信息,在交互中完成对环境的理解,进而完成指定的任务。下面介绍在这最新研究方向上的任务,主要包括视觉语言导航和具身问答任务。
视觉与语言导航
视觉导航和语言导航相关研究
基于视觉的导航往往需要环境的先验信息,或者需要使用激光雷达、深度图或从运动中获取的数据以纯几何方法构建三维地图,或者需要人类指导的地图构造过程。并且在地图构造的过程中,即使环境有明显的模式或特征,但是在被完全建模之前也是不能被观察到的。环境构建与路径规划之间的分离使得系统变得脆弱,因此越来越多的研究开始转向端到端的学习方式——不需要显式的模型或状态估计便可实现从环境图像到路径行为的转换。
同时学者很早就开始关注对于自然语言的理解,引入语言指引的导航策略也受到过许多关注,但是其往往对于语言或环境作出了一定程度的抽象,比如语言指令限制在特定范围或假设语言命令有固定的结构以及将环境中的物体做特定标记,或者将智能体限制在只需要有限知觉的视觉受限环境中。近年来虽然有很多新的多模态非结构化的仿真平台比如 House3D 、 AI2-THOR和HoME等,但是其基于人工合成而非真实图像的模型一定程度上限制了环境建模的准确性和丰富性。
视觉语言导航任务内容
Qi Wu 等人在 2018 年 CVPR 会议上提出了视觉语言导航任务,要求智能体在给定语言指令的情况下,在作者提供的 Matterport3D simulator 仿真环境中,从随机初始位置到达目标位置,并且其仿真环境构建于包含大量基于真实图像生成的 RGB-D 全景图的数据集 Matterport3D。但是其相对复杂和具体的语言描述与实际不太相符。因此在 2019 年,Qi Wu 等人进一步提出被称为 RERERE(remote embodied referring expressions in real indoor environments) 的任务,精简指令的同时引入了对于环境的理解。
视觉语言导航任务最新进展
Qi Wu 提出任务的同时,同时提出了将智能体建模为基于长短期记忆(long short term memory, LSTM) 序列到序列结构 (sequence-to-sequence architecture)注意力机制循环神经网络的解决方案和随机移动策略和最短路径策略两种基线算法以及人类在此任务中的表现(成功率 86.4%)。
视觉语言导航任务也可以视为在给定语言指导条件下寻找从起始点到目标点最佳路径的轨迹搜索问题,基于此 Fried D 提出 speaker-follower 系统,系统中的 speaker 模型用于学习路径描述,follower 模型用于预测和执行路径,并使用全景行为空间代替视觉运动空间的方式使得智能体可以感知当前位置 360°全景视觉。
为解决视觉语言导航任务中的解决跨模态基标对准问题和增强泛化能力,Xin Wang 等人提出基于强化学习和模仿学习的策略,引入了强化跨模态匹配方法和自监督模仿学习方法。
在之前的研究中,视觉语言导航任务中主要评价指标是任务完成度即最终位置与目标位置之间的关系,因此语言指示在导航任务所发挥的作用难以量化。谷歌研究院的 Jain V 等人因此提出可刻画预测路径与语言指示之间契合度的评价标准 CLS(coverage weighted by length score),并根据此指标扩展了 R2R 数据集,提出包含更多节点和更多样化路径的 R4R(room-for-room)数据集。
在实际导航场景中,使用者更倾向于利用简练的语言给定任务的内容而非具体详尽地描述路径的所有信息,因此 Qi Wu 等人进一步提出 remote embodied referring expressions in
real indoor environments(RERERE) 的任务,其中包含类似“去带条纹墙纸的卧室”的导航部分和类似“把放在凳子旁边的枕头拿给我”的指称表达部分,并提供了被称为导航—指向模型的基线算法。
具身问答
具身认知概念
具身认知 (embodied cognition) 这一概念是随着哲学、人工智能和相关领域的发展关于认知的本质被重新思考和定义的过程中诞生的,新的研究越来越倾向于认为大多数现实世界的思考常常发生在非常特殊通常也十分复杂的环境中,出于非常实际的目的,并且利用外部事物的可交互性和可操作性 ,即认知是一种非常具体化和情景化的活动。身体的解剖学结构、身体的活动方式、身体的感觉和运动体验都决定了人类怎样认识和看待世界。简而言之,具身认知理论认为人的生理体验与心理状态之间是有着深刻的内在联系。因此具身相关任务的内涵,就是将任务具体化到可交互的场景中,而非传统的静态图片或无法互动的视频。
具身问答任务内容
具身问答 (embodied question answering) 是 Das 等人在 2018 年 CVPR 会议上提出的任务,将智能体随机安放在三维环境中的某个位置,并且以语言的形式提出类似“汽车的颜色是什么”或者“有多少个房间里有椅子”等类似需要环境信息的问题,为了得到问题的答案,智能体需要自主地对环境进行探索并且收集所需要的信息,最后对问题作出解答。智能体仅依靠单目全景 RGB 摄像头与环境交互,而没有类似环境地图、自身定位的全局表示或类似物体信息、房间描述的结构表示,当然也没有关于任务本身的额外信息,即先验知识几乎为零,需要智能体充分理解任务内容的情况下,通过与具体环境的不断交互,实现对环境的理解,进而完成问题的回答。
具身问答任务最新进展
Das 等人提供的基线算法中智能体视觉、语言、导航和回答四个部分的实现,其中视觉部分基于通过 CNN 将 RGB 图像生成固定大小的表示,语言部分使用 LSTM 编码,导航部分引入包含选择动作(前进,左转,右转)的规划模块和指定执行次数(1, 2…)的控制模块的自适应倍率计算方法,问答部分计算智能体轨迹最后五帧的图像-问题相似性的视觉编码与问题的 LSTM 编码进行比较并输出结果。
在上述研究的基础上,受人类将行为概念化为一系列更高层次语义目标(比如为了吃夜宵,人类会将其抽象为“离开卧室—走到厨房—打开冰箱—找到甜点”而不会详尽地规划路线)的启发,Das 等人进一步提出了模块化学习策略,将学习目标加以分解。
Yu L 等人则把 EQA 任务扩展为 MT-EQA(multi-target EQA) 即在问题形式中引入了多目标,比如类似“卧室里的梳妆台比厨房里的烤箱更大么”这样的问题。
Wijmans E 等人设计了基于三维点云格式的具身问答数据集 MP3D-EQA,设计并测试了多达 16 种不同的导航策略组合,提出损失加权方案 Inflection Weighting 以提高行为模仿的有效性。
相关数据集介绍
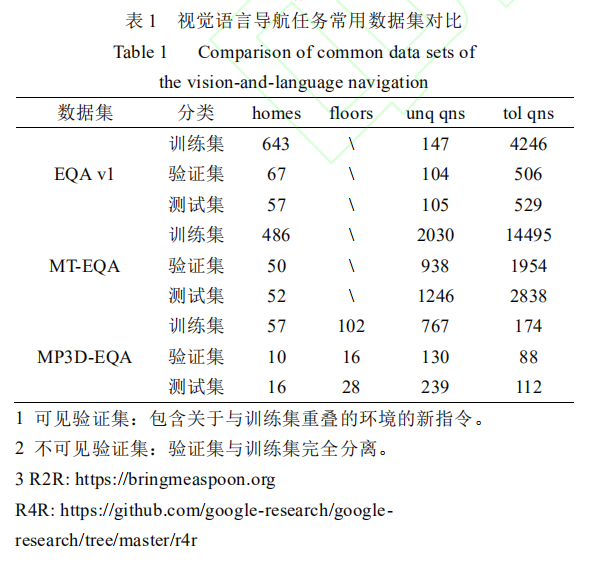
视觉语言导航任务主要包含 3 个数据集,其一是 Qi Wu等人在提出视觉语言导航任务时开源的 R2R(room-to-room) 数据集,其二是 Jain V 等人在改进任务评价方法时开源的R4R(room-for-room) 数据集,其三是 Qi Wu 等人提出RERERE 任务时建立的数据集(暂未开源)。表 1 是三个数据集的简单对比,从对比中可以发现,因为 R4R 数据集更倾向于使得智能体运动轨迹更加符合导航指令而非最短距离,因此参考路径的长度要大于最短路径的长度;而 RERERE 任务则倾向于使用更加简洁的指令,因此指令平均长度要小于R2R。
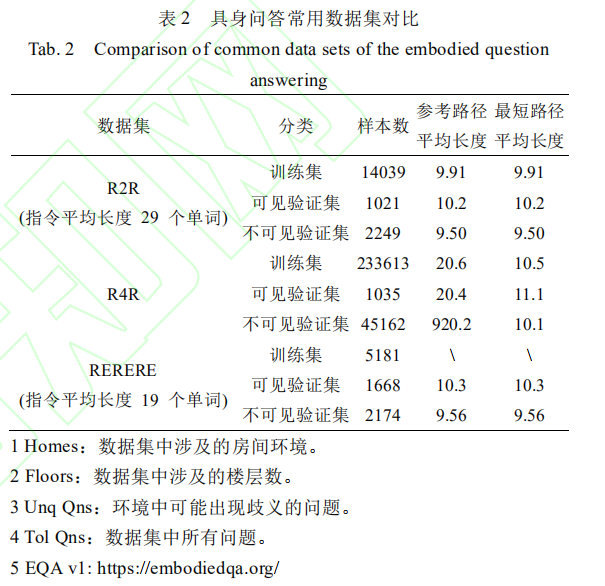
具身问答任务数据集主要包括 3 个数据集,其一是 Das等人开源的 EQA(embodied question answering) v1 数据集,其二是 Yu L 等人引入多目标任务时提出的 MT-EQA(multitarget EQA) 数据集,其三是 Wijmans E 等人将任务中的数据类型替换为点云时提出的数据集 MP3D-EQA 数据集,后两个数据集暂时未开源。表 2 是三个数据集的内容对比。需要注意的是,数据集中包含被称为 unique question 的问题,是指可能产生歧义的问题,比如房间中同时存在两台冰箱时,问题 ‘What room is the air conditioner located in?’ 就会产生歧义。
计算机视觉与自然语言处理融合未来方向展望
真实环境迁移与泛化能力
视觉与自然语言结合的任务取得了令人瞩目的进展,从早期简单将两部分技术简单串联加和的形式扩展到需要智能体借助视觉和语言理解环境并且采取行动的深度融合,但是绝大部分任务都是基于现有的数据集在模拟的环境中进行。诚然,考虑到目前表现较好的算法均是基于需要大量试错的深度强化学习方法,在真实环境中训练的确会消耗大量的时间与精力,但是在模拟环境表现完美的模型迁移到真实环境中也可能会遇到很多意料之外的问题。
而现有的绝大部分研究只是在数据集上达到了较高的精度(比如视觉语言导航任务中 SOTA 算法在可见验证集和不可见验证集上分别达到了73.0%和 61.3%的成功率),仅有少数学者将算法在实际环境中加以验证。因此未来研究重要方向之一是如何将模型迁移到真实环境中。在此过程中,泛化能力又是其中关键,即智能体若遇到训练集中未出现的环境或者未遇到的物体,能否根据过往经验作出较为合理的反应,可能的解决方案是借鉴已经在视觉对话、常识推理和事实预测等方向得到广泛使用和验证的外部知识库方法,即利用事实性或常识性的先验知识提高智能体对于环境的理解和认知能力。
与环境更强大的交互能力
目前已经开源的数据集中,智能体与环境之间的交互相对有限,仅涉及打开微波炉、移动物体或到达指定位置等基本操作,并且可采取的运动形式限制在特定范围(比如前进、左转和右转),虽然在最新的研究中已经涉及类似“把放在凳子旁边的枕头拿给我”这类相对较为复杂的交互形式,但是显然与真实环境的交互方式和运动形式有较大的差距,并且简化了真实环境中的诸多物理性限制,比如“去厨房拿一个鸡蛋”和“去厨房拿一把勺子”语言指示,在真实的环境中智能体需要考虑分别以何种的力度夹取鸡蛋和勺子,而现有的数据集并不考虑此类区别。
另一个比较有前景的方向是与物联网的深度结合,电视、空调和冰箱等对于人类而言需要后天习得交互方式的电器,却因其规则明确和易于联网的性质能够与智能体直接交互。最后就是对环境中其他信息的利用,比如利用声音信息对不可见物体的非视距重建、使用工具达成指定目标甚至与环境中其他智能体的对话交流等。这些与环境的相对复杂的交互是目前研究所欠缺的,但也是未来智能体在真实环境中运行所需要的。
推理能力的引入
目前无论是视觉语言导航还是具身问答,所给的任务都相对直接(比如根据语言提示到达某个房间或者回答环境中某物体是什么颜色等),但是现实生活中更多是是需要推理能力的问题,比如类似视觉推理任务中的比较、属性识别和逻辑运算等初级推理能力,以及演绎、归纳和类比等高级推理能力。虽然在部分研究中已经涉及推理能力,但仍相对简单,未来可能会引入类似“房间装修是什么风格?”或者“到书房中取一本散文集。”
这种涉及相对高级推理能力的任务,前者需要智能体基于房间的整体特征比如吊灯的样式、桌椅的摆放和墙纸的花饰等信息归纳推理得出装修风格的答案,后者则需要智能体能够区分散文、小说或诗歌等不同的文体。当然目前视觉和自然语言方面的进展距离解决此类问题仍有较大空间,但是推理能力尤其是高级推理能力的研究不失为一个值得关注的研究方向。
三维数据的使用
三维点云数据可以提供比图像更丰富和准确的信息,Wijmans E 等人发现在具身问答任务中点云信息可以提升智能体避障能力的学习,Wang Y 等人甚至发现仅仅将二维的双目视觉图像转换为三维点云数据就能大幅提高目标检测的准确度,因此点云数据可能不单在信息内容方面甚至是在数据表示方面均提供了更多的信息。但是一方面受制于点云数据获取的成本和难度,成本百元的相机模组在短短几秒钟内便可获取千万像素级别的高精度图像,但是点云获取设备往往动辄数十万获取时间也往往需要数分钟甚至数小时。
另一方面基于点云的深度学习研究相对滞后于图像,虽然得益于 Point Net++、ASCN、和 SplatNet等方法的提出,点云数据固有的无序性和旋转性不再是应用深度学习技术的障碍,但是学术界对于点云数据的研究仍远远少于图像数据。因此不论是点云数据集的构建还是基于点云数据的研究均不同程度的存在一些困难。后续的研究可能需要更多的引入点云格式的环境信息,为了弥补目前点云数据获取困难的状况,基于双目视觉的三维重建可能是很有希望的辅助手段之一。
学习目标的优化
建构主义者认为,学习是学习者在与环境交互作用的过程中主动地建构内部心理表征的过程。而本文现在已经拥有了多个可交互的模拟环境,因此后续的研究可以在不断地交互进行比如对自然语言的理解或者对环境中工具的使用等能力的学习和提升。此外从表 1 的分类中可以看出,视觉语言导航、具身问答以及交互式问答等在语言层面仍停留于“问答”阶段,即针对单一问题给出正确的答案,未来的研究中很有可能将目标优化到“对话”层面,即针对多个有内在逻辑联系的问题分别给出正确答案,同时问题之间的内在联系也有助于智能体更好地理解环境。
注:本文旨在学习和分享,如内容上有不到之处,欢迎批评指正
参考文献:
[1]李睿,郑顺义,王西旗.视觉—语言—行为:视觉语言融合研究综述[J/OL].计算机应用研究:1-8[2020-09-06].https://doi.org/10.19734/j.issn.1001-3695.2019.09.0512.
责任编辑:xj
原文标题:一文了解计算机视觉与自然语言处理融合的研究进展
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
-
自然语言处理与机器学习的关系 自然语言处理的基本概念及步骤2024-12-05 2630
-
自然语言处理与机器学习的区别2024-11-11 2217
-
计算机视觉与自然语言处理的区别2024-07-10 3127
-
自然语言处理属于人工智能的哪个领域2024-07-03 3350
-
自然语言处理的概念和应用 自然语言处理属于人工智能吗2023-08-23 2599
-
自然语言处理(NLP)的学习方向2020-07-06 13876
-
自然语言处理的发展简史2020-05-11 11002
-
【推荐体验】腾讯云自然语言处理2019-10-09 2815
-
语义理解和研究资源是自然语言处理的两大难题2019-09-19 2512
-
自然语言处理研究的基本问题及发展趋势2018-09-21 9322
-
深度学习在自然语言处理方面的研究进展2018-07-19 7992
-
什么是自然语言处理_自然语言处理常用方法举例说明2017-12-28 18605
全部0条评论

快来发表一下你的评论吧 !
