

哈工大讯飞联合实验室发布的中文ELECTRA系列预训练模型再迎新成员
描述
哈工大讯飞联合实验室发布的中文ELECTRA系列预训练模型再迎新成员。我们基于大规模法律文本训练出中文法律领域ELECTRA系列模型,并且在法律领域自然语言处理任务中获得了显著性能提升。欢迎各位读者下载试用相关模型。
项目地址:http://electra.hfl-rc.com
中文法律领域ELECTRA
我们在20G版(原版)中文ELECTRA的基础上加入了高质量2000万裁判文书数据进行了二次预训练,在不丢失大规模通用数据上学习到的语义信息,同时使模型对法律文本更加适配。本次发布以下三个模型:
legal-ELECTRA-large, Chinese: 24-layer, 1024-hidden, 16-heads, 324M parameters
legal-ELECTRA-base, Chinese: 12-layer, 768-hidden, 12-heads, 102M parameters
legal-ELECTRA-small, Chinese: 12-layer, 256-hidden, 4-heads, 12M parameters
快速加载
哈工大讯飞联合实验室发布的所有中文预训练语言模型均可通过huggingface transformers库进行快速加载访问,请登录我们的共享页面获取更多信息。
https://huggingface.co/HFL
模型键值如下:
hfl/chinese-legal-electra-large-discriminator
hfl/chinese-legal-electra-large-generator
hfl/chinese-legal-electra-base-discriminator
hfl/chinese-legal-electra-base-generator
hfl/chinese-legal-electra-small-discriminator
hfl/chinese-legal-electra-small-generator
效果评测
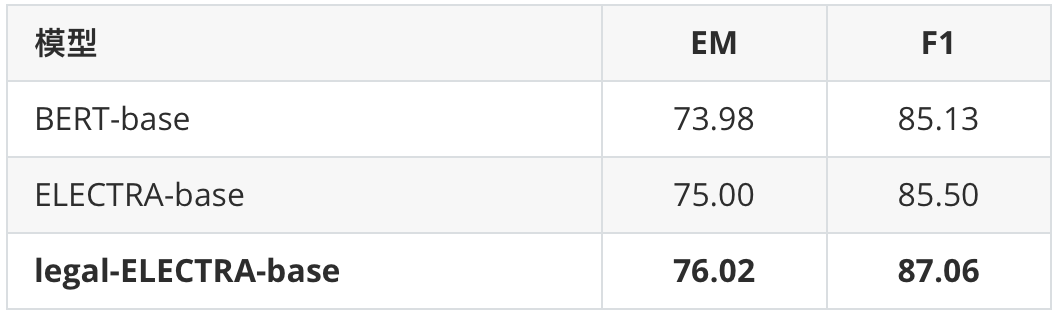
我们在罪名预测以及要素抽取任务上进行了基线测试。其中罪名预测任务使用的是CAIL 2018数据,要素抽取任务为in-house实际应用。可以看到本次发布的法律领域ELECTRA模型均相比通用ELECTRA模型获得了显著性能提升。
表1 罪名预测任务
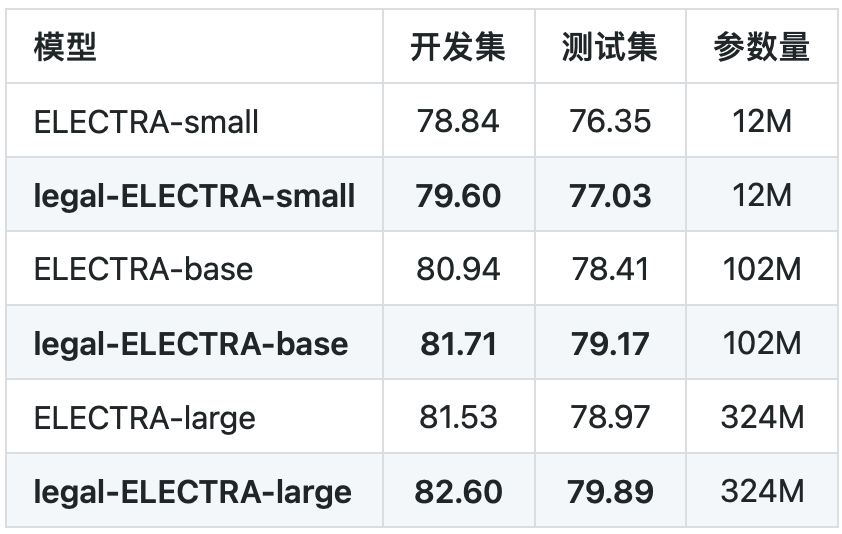
表2 要素抽取任务
其他相关资源
TextBrewer知识蒸馏工具
http://textbrewer.hfl-rc.com
中文BERT、RoBERTa、RBT系列模型
http://bert.hfl-rc.com
中文XLNet系列模型
http://xlnet.hfl-rc.com
中文MacBERT模型
http://macbert.hfl-rc.com
责任编辑:xj
原文标题:哈工大讯飞联合实验室发布法律领域ELECTRA预训练模型
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
-
【年终福利来了!!!】开放实验室校园行----北斗专家走进长沙理工大学2015-12-24 4114
-
lims实验室管理系统是什么?实验室信息管理系统介绍!2021-11-03 17816
-
模型动力电学实验室2.02006-04-10 1062
-
哈工大四系FPGA上机实验编程部分2017-10-20 1130
-
哈工大讯飞联合实验室发布基于全词覆盖的中文BERT预训练模型2019-07-18 6851
-
华为终端软件和科大讯飞共建生态联合创新实验室,探索跨终端分布式新体验2020-05-11 3241
-
字符感知预训练模型CharBERT2020-11-27 2712
-
九联科技与科大讯飞签约 共建智能硬件联合创新实验室2022-11-20 2707
-
飞腾与大商所飞泰共建 “行业信创联合实验室”2021-12-31 1923
-
飞腾基础软件联合实验室将推动合作资源共享2023-07-14 1695
-
科大讯飞发布“讯飞星火V3.5”:基于全国产算力训练的全民开放大模型2024-02-04 2327
-
谷歌模型训练软件有哪些功能和作用2024-02-29 1651
-
西井科技和香港理工大学签署合作协议,将共建联合创新实验室2024-04-29 1508
-
华工科技联合哈工大实现国内首台激光智能除草机器人落地2024-09-06 2266
-
小米与聚飞光电成立联合实验室2024-11-27 1316
全部0条评论

快来发表一下你的评论吧 !
