

语义分割方法发展过程
描述
语义分割
目的:给定一张图像,我们要对这张图像上的每个pixel逐一进行分类,结果展示如下图:
上图中的实例分割是语义分割的延伸,要区别出相同类别的不同个体。
应用场景:无人驾驶、辅助医疗等。
语义分割方法发展过程:
1.灰度分割(Gray Level Segmentation)
语义分割的最简单形式是对一个区域设定必须满足的硬编码规则或属性,进而指定特定类别标签. 编码规则可以根据像素的属性来构建,如灰度级强度(gray level intensity). 基于该技术的一种分割方法是 Split and Merge 算法. 该算法是通过递归地将图像分割为子区域,直到可以分配标签;然后再合并具有相同标签的相邻子区域。
这种方法的问题是规则必须是硬编码的. 而且,仅使用灰度级信息是很难表示比如人类等复杂类别的. 因此,需要特征提取和优化技术来正确地学习复杂类别的特征表示。
2.条件随机场(Conditional Random Fields)
CRFs 是一类用于结构化预测的统计建模方法. 不同于分类算法,CRFs 在进行预测前,会考虑像素的邻近信息(neighboring context),如像素间的关系. 这使得 CRFs 成为语义分割的理想候选者. 这里介绍下 CRFs 在语义分割中的应用.
图像中的每个像素都是与有限的可能状态集相关. 在语义分割中,target 类别标签就是可能状态集. 将一个状态(或,label u) 分配给的单个像素 x 的成本(cost) 被称为一元成本(unary cost). 为了对像素间的关系进行建模, 还进一步考虑将一对标签(labels (u, v)) 分配给一对像素 (x, y),其被成为成对成本(pairwise cost). 可以采用直接相邻的像素对作为像素对(Grid CRF);也可以采用图像中所有的像素构建像素对(Denser CRF)。
图像中所有 unary cost 和 pairwise cost 的相加和作为 CRF 的能量函数(或损失函数,loss). 求解最小化即可得到较好的分割输出。
深度学习极大地简化了语义分割的流程(pipeline),并得到了较高质量的分割结果
3.FCN
FCN方法的提出成功的将深度学习方法成功的引入到了语义分割领域,由于要预测的图像是一个二维的表示,因此提出了全卷积网络用来抽取图像中的特征,将得到的高级语义特征上采样到指定的维度,从而得到了最终的预测结果,从而自然的形成了Encoder-Decoder框架,这也成为了语义分割领域中通用框架之一。
具体的模型图如下:
由于在Encoder中获取到图像的高级语义,但是其并不是最终分割的结果,因此作者采用转置卷积的方法将该高级特征上采样到指定的维度,从而得到最终的分割结果。由于直接上采样之后的结果并不好,因此在改论文中引入了跳跃模型就是将不同卷积层下获取到的特征相融合,从而改善模型的效果,其具体结构如下所示:
4.U-NET, SegNet 等
为了改善FCN中的弊端,随后提出了很多模型最经典的是U-Net,SegNet,但是他们的本质上并没有改变Encoder-Decoder模型的架构。
5.DeepLab系列
DeepLab的出现带来了一个新的方法就是扩展卷积(空洞卷积)方法,卷积层引入了一个称为 “扩张率(dilation rate)”的新参数,该参数定义了卷积核处理数据时各值的间距。其目的是为了扩大模型的感受野,使其能够感受到更大范围下的特征信息。具体的体现如下所示:
扩展卷积方法的提出让人们可以去除Encoder-Decoder框架的限制。随后deeplab算法的改进也提出了例如多尺度学习的通则红描述方法(ASPP等)
6.NOW
面对监督式方法---最近的方法大家更注重于实时的语义分割任务,也就是轻量级的语义分割网络的设计。当然还有一些其他的方法,例如针对不同的领域设计不同的语义分割网络、改进上采样方法等。
面对弱监督方法---目前出现了很多弱监督方法,就是通过学习图像分类的数据集(image-level tag)中的信息,来完成语义分割这种密度预测的任务。当然还有使用框架注释来标注数据(bounding-boxes tag)的。
语义分割领域中困难的地方:
1、数据问题:分割不像检测等任务,只需要标注一个类别就可以拿来使用,分割需要精确的像素级标注,包括每一个目标的轮廓等信息,因此使得制作数据集成本过高;
2、计算资源问题:现在想要得到较高的精度的语义分割模型就需要使用类似于ResNet101等深网络。同时,分割预测了每一个像素,这就要求feature map的分辨率尽可能的高,这都说明了计算资源的问题,虽然也有一些轻量级的网络,但精度还是太低了;
3、精细分割:目前的方法中对于图像中的大体积的东西能够很好的分类,但是对于细小的类别,由于其轮廓太小,从而无法精确的定位轮廓,造成精度较低;
4、上下文信息:分割中上下文信息很重要,否则会造成一个目标被分成多个part,或者不同类别目标分类成相同类别;
评价指标:
1、执行时间:速度或运行时间是一个非常有价值的度量,因为大多数系统需要保证推理时间可以满足硬实时的需求。然而在通常的实验中其影响是很不明显的,并且该指标非常依赖硬件设备及后台实现,致使一些比较是无用的。
2、内存占用:在运行时间相同的情况下,记录系统运行状态下内存占用的极值和均值是及其有价值的。
3、精确度:这里指的是逐像素标记的精度测量,假设共有k个类(从l0到lk其中有一个类别是属于背景的。),Pij表示本属于i类但是被预测为j类的像素个数,Pii表示为真正分对类的数量,而Pij与Pji分别被称为假正样本和假负样本。
1)Pixel Accuracy(PA,像素精度):标记正确的像素占总像素的比例
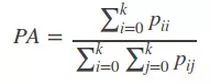
2)Mean Pixel Accuracy(MPA,平均像素精度):计算每个类内被正确分类像素数比例,之后求所有类的平均数。
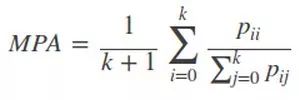
3)Mean Intersection over Union(MIoU,均交并比):为语义分割的标准度量,其计算两个集合的交集和并集之比,这两个集合分别为ground truth 与predicted segmentation,在每个类上计算IoU,之后将其求平均。
-----IoU即真正样本数量/(真正样本数量+假正样本数量+假负样本数量)
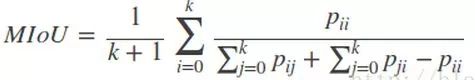
4)Frequency weighted Intersection over Union(FWIoU,频权交并):是MIoU的一种提升,这种方法根据每个类出现的频率为期设置权重。
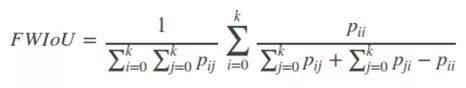
责任编辑:lq
-
图像分割和语义分割的区别与联系2024-07-17 3134
-
图像分割与语义分割中的CNN模型综述2024-07-09 3480
-
语义分割标注:从认知到实践2023-04-30 2044
-
图像语义分割的概念与原理以及常用的方法2023-04-20 7324
-
基于SEGNET模型的图像语义分割方法2021-05-27 947
-
基于深度神经网络的图像语义分割方法2021-04-02 1652
-
基于深度学习的三维点云语义分割研究分析2021-04-01 1506
-
分析总结基于深度神经网络的图像语义分割方法2021-03-19 1482
-
语义分割算法系统介绍2020-11-05 8026
-
了解示波器的发展过程很重要2019-07-24 1149
-
Facebook AI使用单一神经网络架构来同时完成实例分割和语义分割2019-04-22 3774
-
聚焦语义分割任务,如何用卷积神经网络处理语义图像分割?2018-09-17 1037
-
基于内容的图像分割方法综述2018-01-02 1312
-
光纤通信的发展过程2017-01-02 1176
全部0条评论

快来发表一下你的评论吧 !
