

一种多类原型模糊聚类的初始化方法
嵌入式设计应用
描述
一种多类原型模糊聚类的初始化方法
模糊聚类是非监督模式分类的一个重要分支,在模式识别和图像处理中已经得到了广泛的应用.但现有模糊聚类算法大都需要聚类数的先验知识,而且对初始化极为敏感,从而限制了它们的实际应用.此外对于多类原型样本集的聚类分析,还需要事先已知原型的类型及相应数目.为了克服这些限制,本文提出一种聚类原型先验知识的获取方法,并用来初始化多类原型模糊聚类,取得了较好的效果.
关键词:模糊聚类;数学形态学;细化;曲线拟合
An Initialization Method for Multi-Type Prototype Fuzzy Clustering
GAO Xin-bao,XUE Zhong,LI Jie,XIE Wei-xin
(School of Electronics Engineering,Xidian University,Xi'an 710071,China)
Abstract:Fuzzy clustering is an important branch of unsupervised classification,and has been widely used in pattern recognition and image processing.However,most of exiting fuzzy clustering algorithms are sensitive to initialization,and strongly depend on the number of clusters,which limits their applications.Moreover,it also needs to know the type and number of prototypes in advance in multi-type prototype fuzzy clustering.To overcome these limitation,a method for acquiring a priori knowledge about clustering prototype is proposed in this paper,which obtains better performance in initializing multi-type prototype fuzzy clustering.
Key words:fuzzy clustering;mathematical morphology;thinning;curve fitting
一、引 言
聚类分析是非监督模式分类的一个分支,其基本任务是把特征空间中一个未标记的模式样本集按照某种相似性准则划分到若干个子集中,使相似的样本尽量归为一类.传统的聚类分析是基于硬划分的,每个样本属于且只属于某一类.1973年Dunn[1]引入模糊集理论,定义了基于目标函数J2(U,v)的模糊c-均值聚类算法.后来,Bezdek[2]又推广到了一个目标函数的无限族,此后模糊c-均值聚类算法成为研究的主流.在模糊聚类中,样本不再仅属于某一类,而是以不同的程度分属于每一类,表达出了样本间的相近信息及事物在性态和类属方面的中介性,从而更符合人的分类方式.
随着模糊c-均值算法理论和应用的发展[3],为检测椭球状分布以外的模式子集,该算法被逐步推广到模糊c-线[4]、模糊c-壳[5]以及模糊c-二次曲线[6]等新型算法.新算法把聚类原型从点扩展到了线、面、壳等几何结构,把模糊聚类的应用范围从简单的模式分类拓宽到基元检测、曲线拟合等众多领域.作为上述算法的集成和统一,最近提出了一种多类原型模糊聚类算法[7],该算法中聚类原型不再是单一的形式,而是多类原型的混合,因此可以同时检测呈不同几何结构分布的样本子集.
然而上述各类算法大都依赖于聚类原型和聚类数的先验知识,即必须事先已知样本子集分布的几何结构及类别数,这限制了它们在生产自动化中的应用.此外,这些算法均采用局部搜索技术,因此对初始化极为敏感,即使在聚类原型和聚类数给定的情况下,如果种子点选择不当,也很容易陷于局部极值点,得不到最佳分类.
针对以上限制及缺点,本文提出了一种结合数学形态学、图像描述及曲线拟合等技术的初始化方法.本方法不仅可以估计各类原型的位置,而且能够自动获取原型的结构参数及数目,从而使聚类分析成为真正的机器自动学习算法.
以下,第二部分简要介绍多类原型的模糊聚类分析,第三部分引入几个数学形态学算子,第四部分给出聚类原型参数的自动获取方法,第五部分为实验结果及讨论,最后是结论及后续工作.
二、多类原型的模糊聚类
多类原型的模糊聚类[7]是传统模糊聚类的集成和统一,在这种分析方法中聚类原型不再是单一的形式,而是呈现多样化.它不仅能完成现有各种聚类算法的功能,即检测单一模式样本子集,而且可以用来分析呈多种几何结构分布的特征集.除模式分类外,该算法还能实现基元检测、物体识别等多种功能.
设x为Rp中的一个子集x={x1,x2,…,xn}Rp,xk=(xk1,xk2,…,xkp)∈Rp称为特征矢量或模式矢量,xkj为观测样本xk的第j个特征.设Vcn是所有c×n阶的矩阵集合,c为[2,n)区间内的整数,则x的模糊c-划分空间为:
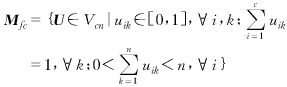 (1)
(1)
其中U矩阵的元素uik表示第k个样本xk属于第i个聚类的程度.设B={β1,β2,…,βc}为聚类原型集,其中为第i个模糊子集的模式原型,则多类原型的模糊划分可以通过极小化如下的目标函数而得到:
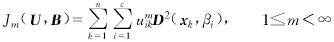 (2)
(2)
式中,m为模糊指数,m越大分类的模糊度越大,当时,退化为硬聚类算法;D(xk,βi)为样本xk与第i个原型βi的相似性测度,当c个原型βi(i=1,…,c)均为RP空间中的点、线或壳时,该算法分别退化为模糊c-均值、模糊c-线或模糊c-壳聚类.
Jm(U,B)通过U与B的迭代沿着一子序列而逐渐收敛到初始B(0)附近的极值点或鞍点[8],由于Jm(U,B)是一个多峰的复杂函数,因此原型B的初始化就变得尤为重要,一个随机的初始化,可能导致分类的错误.而如果初始化B(0)落到包含有最佳B*的收敛子序列中,则能保证Jm(U,B)最终收敛到全局最优点.此外,对于多类原型的模糊聚类算法必须事先已知原型的类型及相应的数目,否则将无法得到正确的聚类结果.因此需要有效的初始化方法来提供有关聚类原型的信息.
三、数学形态学的基本算子
为了设计一种多类原型模糊聚类的初始化方法,需要引入数学形态学中的几个基本算子和基本操作.首先介绍几个习惯表示符,令带有下划线的大写字母“A,B,…”表示N维离散空间中的二值点集;集合中的点定义为N维整数坐标的矢量,用相应的大写字母表示为“A,B,…”;并用带有下标的小写字母“a1,a2,…,aN”表示矢量A的各个分量,比如:A=(a1,a2,…,an,…,aN)T.
1.膨胀与腐蚀算子
设X,S,…ZN,且元素X=(x1,x2,…,xn,…,xN)T和S=(s1,s2,…,sn,…,sN)T都是具有离散坐标的N元组,如果用
(X)s={T∈ZN|T=X+S,X∈X} (3)
表示点集X平移S,则X被S膨胀可基于Minkowski加法而定义为:
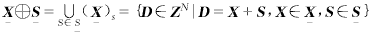 (4)
(4)
同样,基于Minkowski减法可以定义S对X的腐蚀操作
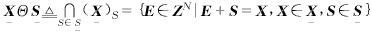 (5)
(5)
其中S称为结构元素.
2.开、闭运算
在实际中,膨胀、腐蚀算子很少单独使用,而是相互结合成对使用,这就是常见的数学形态学中的开运算和闭运算.设我们用XS表示集合X相对于S的结构开,则开运算Xs为集合X相对于结构元素S先腐蚀后膨胀的结果,即有
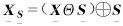 (6)
(6)
开运算具有平滑功能,它能消除集合X几何结构中孤立的小点,毛刺和小桥,使XS变成一个边缘相对光滑、简单的结构.
由对偶性,集合X相对于S的结构闭XS,即为先膨胀后腐蚀的结果,有
(7)
闭运算也具有过滤功能,能填平集合X几何结构中的孔洞、弥补小裂缝.
实验中,我们发现对集合X先相对于S作膨胀操作,然后再作开运算就不再改变其大体结构.因此下一节中我们将构造开、闭运算的链式操作来删除待聚类数据集中的细节,而保留模式子集结构的总体形状,以便获取聚类原型的有关信息.
四、聚类原型及聚类数的自动获取
在呈多类原型分布的模式集中,特征矢量在特征空间中的分布可用如下模型描述:
xk=βi+εi,xk∈ci,εi∈N(0,σi) (8)
其中xk为特征矢量;ci为矢量xk最贴近的模式子集,即有uik=maxcj=1uij;βi为模式子集或聚类ci的原型;N(0,σi)表示高斯分布.也就是说,贴近于同一个聚类的矢量按照正态分布模式聚集在原型的附近,σi反映了其聚散程度.由高斯分布的特点可知,聚类ci中的样本绝大多数都散布在邻域Δ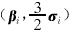 内,因此定义聚类ci的厚度为3σi.基于样本分布的这些形态特征,可以借助形态处理来提取聚类原型信息.
内,因此定义聚类ci的厚度为3σi.基于样本分布的这些形态特征,可以借助形态处理来提取聚类原型信息.
一个聚类原型信息自动获取的流程可由图1所示的框图来表示:
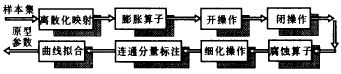
|
图1 聚类原型信息自动获取框图 框图中各部分的功能简介如下: M:Y→X,YRP,XZP (9) 该映射M等效为矢量量化处理,选取合适的分辨率Re则可简化后续的操作. ‖pij-pil‖δi,pij、pil∈SPik 其中Pi为第i个连通分量CCi中ni个交叉点组成的集合,δi的大小依据第i个聚类的厚度来选取,可近似为倍的聚类厚度,即为3σi. 五、实验结果与讨论 |
|
图2 球型及抛物线型混合分布数据的聚类原型自动获取 如图3(a)所示为包含六类模式子集的人造数据,其中四类为球状分布两类为交叉的线状分布.由于原型出现交叉给初始化带来一定的难度.线状分布的样本集形态学处理后连为一体,形成一个大的连通分量,本文方法删除交叉点后得到八个连通子分量(其中两条线段被断为四段),细化及拟合后得到的原型显示在图3(b)中.由于四条线段符合合并准则,本文方法把四条线段合并成了两条,如图3(c)所示,最后得到聚类数c=6,六个样本子集分别为四个球型分布的子集和两个呈线状分布的子集,同时获得各个聚类原型参数.以此初始化多类原型模糊聚类即可获得更为准确的聚类原型. 图3 球型及线型混合分布数据的聚类原型自动获取 图4所示为本文方法应用于编队飞机目标架次识别的实验结果.实验数据为在某常规获戒雷达(VHF波段)上录取的四架编队战斗机的回波.基于编队目标间距引起回波多谱勒的变化,可以利用时频分析实现目标架次的分辨[11].图4(a)为原始回波数据Wigner-Ville分布生成的灰度图像,可看出编队目标回波为多个线性调频信号,从而对架次的识别就转化为对连续直线的检测(图中明暗相间的直线段为Wigner-Ville分布引起的交叉干扰项,不代表任何信号自身项,应予以抑制).图4(b)为预处理后得到的二值图像,可见直线段淹没在干扰点中.在具体应用中有许多先验知识可以用来简化问题,比如在该实验中,我们只检测连续的直线段,因此可以省略形态学处理部分.图4(c)为最终检测的结果,包括直线段的条数和直线方程.尽管Radon变换同样也可以检测直线,但本文方法所用时间仅为Radon变换的三分之一,精度还高于Radon变换[12].如果进一步获得线性调频信号的起止频率以及变化率等细微信息,可以用本文方法得到的参数初始化模糊c-线聚类或多类原型模糊聚类算法,以细调原型参数,获得相应信息.这在电子对抗中将有重要应用. |
|
图4 编队飞机架次识别实验结果(线性调频信号数目及参数的获取) 上述三个实验表明,本文方法简单可行、可靠性高,同时具有广泛的应用前景. 六、结论及后续工作 |
- 相关推荐
- 热点推荐
- �
-
一种基于聚类和竞争克隆机制的多智能体免疫算法2021-12-29 817
-
一种基于图聚类的安全态势评估方法2009-04-02 702
-
改进的模糊聚类特征压缩及其应用2009-12-26 856
-
一种新的模糊系统建模方法研究与应用2010-01-12 581
-
基于粒子群模糊C均值聚类的快速图像分割2012-10-16 1024
-
基于满意模糊聚类的热工过程多模型建模方法2017-01-07 639
-
一类基于PID控制的新型模糊控制方法_张恩勤2017-02-07 747
-
一种聚类个数自适应的聚类方法(简称SKKM)2017-11-03 2609
-
一种改进的BIRCH算法聚类方法2017-11-10 915
-
一种以遗传模拟退火算法的数据流聚类2017-11-22 1612
-
一种局部搜索自适应核模糊聚类方法2017-11-27 822
-
一种新的基于流行距离的谱聚类算法2017-12-07 1004
-
中点密度函数的模糊聚类算法2017-12-26 830
-
基于模糊C均值聚类的软件多缺陷定位方法2021-06-02 893
全部0条评论

快来发表一下你的评论吧 !
