

NVMe-oF的优势及未来
描述
NVMe over Fabric(又名NVMe- oF)是一种新兴技术,它支持对数据中心的计算和存储进行分解。美光科技正通过与Marvell、Foxconn-Ingrasys和英伟达(NVIDIA)等关键技术合作伙伴的合作,共同解锁NVMe-oF技术可以带来的优势。我们还在开发创新技术,如异构存储器存储引擎(HSE),这将有助于使用NVMe-oF优化对闪存的大规模访问。
NVMe-oF是什么?
NVMe- oF从字面上来看是网络上的NVMe协议的扩展,其扩展范围远远超出了目前搭载SSD的服务器。NVMe早在2011年就出现了,而fabrics扩展则在2016年首次标准化。NVMe-oF继承了NVMe的所有优点,包括轻量级和高效的命令集、多核感知和协议并行性。NVMe-oF是真正的网络无关的,因为它支持所有常见的fabrics,包括光纤通道、InfiniBand和以太网。图1比较了NVMe和NVMe- of模型,并标注出了用户可用的各种网络和网络传输选项。
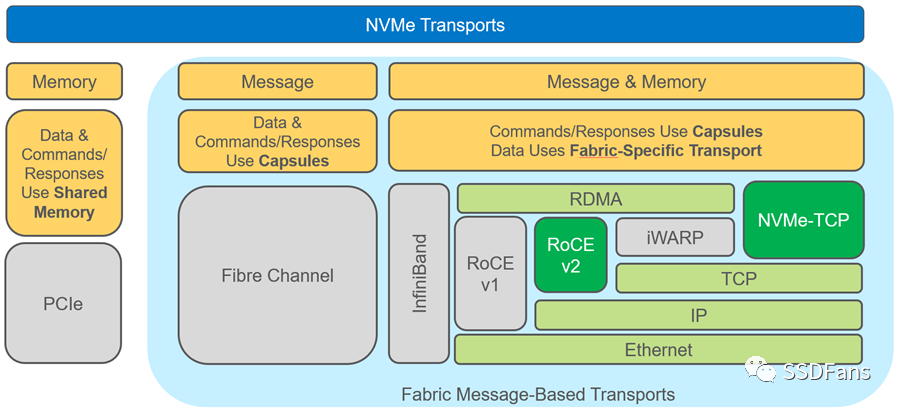
图1 NVMe和NVMe-oF模型对比
从图1可以看出,有两种以太网传输选项,RoCE v2和NVMe-TCP,每一种都各有优缺点。RoCE v2延迟较低,但需要专用的支持RDMA的NIC (RNIC);NVMe-TCP不需要专用的RNIC,但是其传输延迟和CPU使用率都更高,它使用的是标准NIC。相比之下,RoCE v2目前在市场上更为流行。
NVMe over Fabrics的优势是什么?
使用NVMe就意味着只能使用基于PCIe交换机的服务器机架。虽然这是一种完全有效的存储扩展方法,但它的范围是非常有限的。NVMe-oF则允许在数据中心范围内连接无数的存储空间。
如今,NVMe-oF已经很成熟了,许多用户接受了将全闪存阵列(AFA)连接到服务器的技术。然而,NVMe-oF的优势只有在计算和存储完全分开时才能完全发挥出来。也就是说,通过网络将一个NVMe SSD池提供给一个服务器池,这种方式允许按需提供计算和存储。计算和存储的分解提升了存储的可伸缩性和可共享性,并支持可组合性,如图2所示。
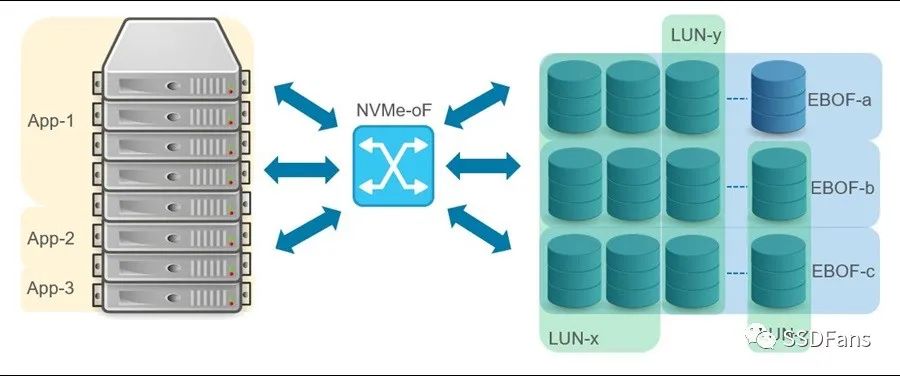
图2 计算和存储分解图
分类存储的另一个维度是存储服务(即数据保护、复制、压缩等)。存储服务可以由服务器(onload模型)管理,也可以卸载到接近实际存储的数据处理单元(DPU)。onload模型需要消耗额外的CPU周期和网络带宽,可以实现成本最小化,而卸载模型的成本较高,并且根据供应情况,可能产生瓶颈。由于onload模型的TCO(总成本)优势,大规模追求低成本存储使其附加了存储策略。
什么是EBOF、JBOF和JBOD ?
全闪存阵列有两种接入方式: 通过网络接入(EBOF)和直接连接 (JBOF)。不要混淆JBOF和JBOD(只是一堆磁盘)。JBOD通常用于在PCIe上使用NVMe扩展机架中的存储。EBOF或JBOF可以使用NVMe-oF在数据中心之间扩展存储。如图3所示,JBOF使用PCIe交换机向SSD扩展,而EBOF使用以太网交换机向SSD扩展。JBOF和EBOF都使用NVMe-oF连接回服务器。
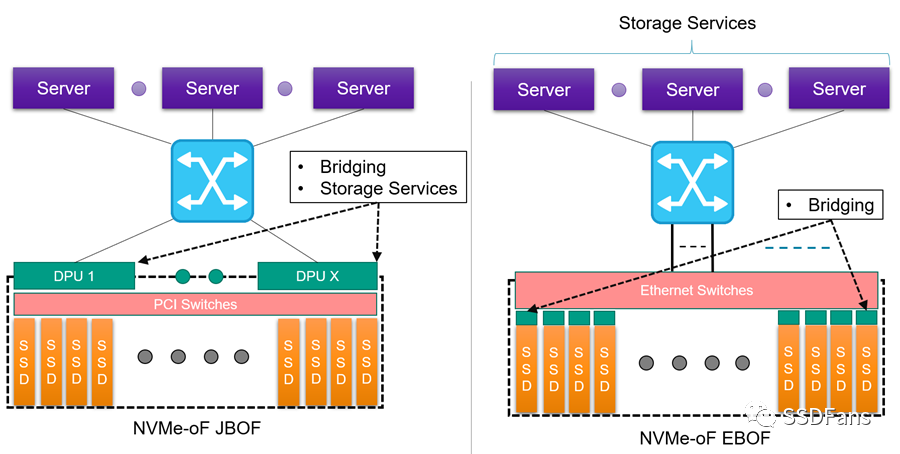
图3 EBOF 和 JBOF对比图
除了以太网和PCIe交换之外,这两种方法的主要区别在于从NVMe到NVMe-oF的转换发生在哪里。在JBOF上,转换或桥接是在外围使用一个或多个DPU (x DPU到y SSD, x:y比率)。在EBOF上,桥接在SSD载体完成(x桥接到x SSD, 1:1的比例)。虽然JBOF有使用DPU的处理能力来运行存储服务的优势,但它确实存在一个潜在的瓶颈,并且和EBOF模型相比,带来了额外的成本,具有一些新功能。当桥与固态硬盘的比例不是1:1时,成本权衡和瓶颈问题就开始显现出来了。
使用Marvell 88SN2400和Foxconn-Ingrasys EBOF测试系统
通过与Marvell和Foxconn-Ingrasys的合作,我们一直在NVMe- oF环境中测试Micron 7300主流NVMe SSD,并在各种不同的应用程序和工作负载下进行测试。
在介绍测试结果之前,让我们先看一下Foxconn-Ingrasys EBOF和Marvell的88SN2400转换器控制器和PresteraCX 8500交换机。
Marvell的88SN2400是一款用于云和企业数据中心的SSD转换器的NVMe控制器。这与Marvell交换机相结合,本质上允许用户在NVMe和NVMe- oF之间进行转换或“桥接”。88SN2400转换器控制器是Foxconn-Ingrasys EBOF的一个关键组件,与Micron 7300 SSD一起,使高性能2U存储器达到高达73.1 GB/s的带宽和高达2000万IOPs。图4显示了Foxconn-Ingrasys EBOF,在2U机箱中有24 U.2插槽。
Foxconn-Ingrasys U.2 Carrier采用标准的U.2 SSD格式。U.2载波支持双以太网端口,以解决需要路径冗余的应用程序,它在驱动器侧有一个PCIe Gen3 x4用于NVMe SSD。
Marvell的88SN2400转换器控制器支持RoCE v2和NVMe-TCP传输。然而,在我们的测试中,我们关注的是RoCE v2。
如何使用NVIDIAGPUDirect存储(GDS)进行扩展?
我们一直在使用NVIDIAGPUDirect存储(GDS)在人工智能和机器学习工作负载方面进行大量工作。我们想通过将Foxconn-Ingrasys EBOF与Marvell的88SN2400转换器控制器连接到NVIDIA DGXA100系统,来了解在fabrics环境中事物是如何伸缩的。这是一个简单的gdsio (GPUDirect Storage I/O)工具测试,可以比较在NVMe-oF环境中使用和不使用GDS的带宽和延迟。
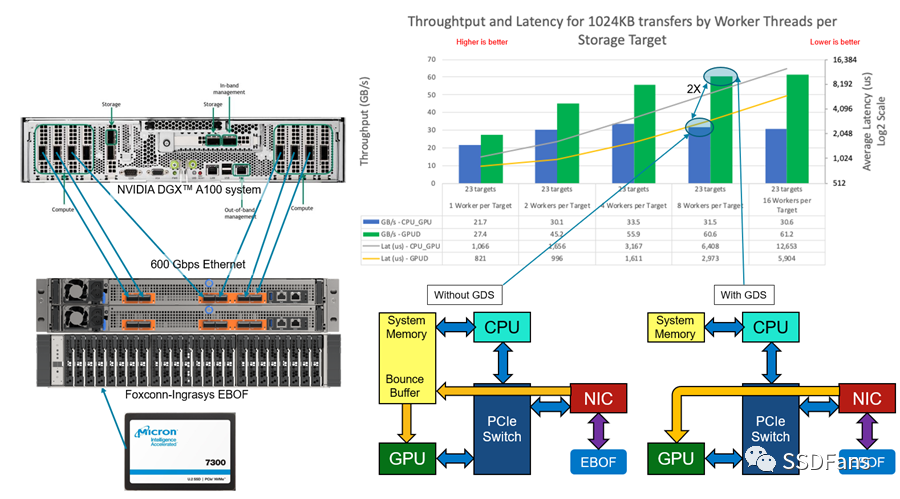
图6 DGX A100 with EBOF
在图6中,有一个装载了Micron 7300 SSD的EBOF,它使用8个计算网络端口中的6个直接连接到NVIDIA DGXA100,提供600gb /s的可用网络带宽。GDS可以让数据在对等点之间直接传输,跳过了在GDS未启用时使用的高延迟反弹缓冲区。在这个测试中,我们将SSD的全部能力(约61 GB/s)用于工作负载。未来的测试将添加一个以太网交换机,并进一步扩大EBOF的数量。
NVMe-oF如何与HSE形成规模?
Micron一直在研究一些惊人的技术,其中之一是异构内存存储引擎(HSE)。HSE是一个闪存感知的存储引擎,它提高了存储类内存(SCM)和SSD的性能。它还通过减少写放大增加了SSD的有效寿命,所有这些都在大规模部署的情况下进行。NVMe-oF是进一步扩大HSE规模的理想途径。为了验证HSE在Fabric附加存储环境下的有效性,我们使用MongoDB和YCSB (Yahoo!云服务基准)。在图7中,我们比较了使用本地Micron 7300 SSD的默认内置MongoDB存储引擎(WiredTiger)和使用Micron 7300 SSD的Micron HSE在EBOF中的性能。
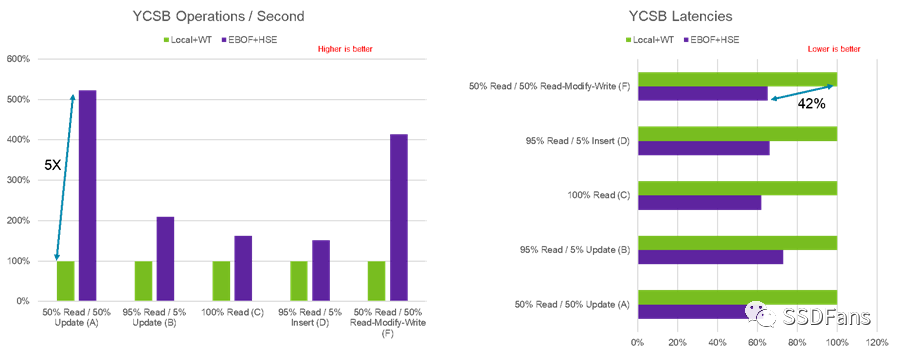
图7 WiredTiger和HSE对比图
与MongoDB中使用的带有本地SSD的传统WiredTiger存储引擎相比,HSE在fabric环境中的有效性是非常显著的。可以实现每秒5倍的YCSB操作改进,降低42%的延迟,同时增加了存储的可伸缩性。
NVMe-oF的未来是什么?
NVMe-oF是一种创新技术,它最终将使数据中心完全分解,在这些中心中,可以组合应用程序,然后以一种经济有效的方式动态地提供适量的计算和存储。
如今,人们使用低成本桥接器或基于处理器的平台来连接NVMe SSD,并将其桥接到EBOF或JBOF。在未来,我们可能会看到SSD的本地NVMe进一步降低TCO并提高性能。
美光科技正在设计下一代数据中心SSD,其功能和特性针对NVMe应用进行了优化。
责任编辑:xj
原文标题:再见,Intel!GPU直连NVMe SSD!
文章出处:【微信公众号:ssdfans】欢迎添加关注!文章转载请注明出处。
-
NVMe协议研究扫盲2025-06-02 1277
-
NVMe over Fabrics 国产 IP:高性能网络存储解决方案2025-12-12 1462
-
高性能网络存储设计:NVMe-oF IP的实现探讨2025-12-19 655
-
如何用MRAM和NVMe SSD构建未来的云存储的解决方案2021-01-11 1901
-
IBM大波存储阵列新增对NVMe-oF的支持2018-11-05 4714
-
业界首款NVMe-oF SSD转换器控制器能够降低总体拥有成本2018-11-23 1368
-
FCoE曾经想一统江湖,但现在已经无人问津,NVMe/TCP会重蹈覆辙吗?2019-03-21 12256
-
Marvell推出NVMe-oF以太网SSD技术和新一代SSD控制器解决方案2019-08-19 5896
-
SCM的大爆发将成为未来存储行业发展的趋势2019-11-24 1340
-
为什么NVMe/TCP是数据中心的更优选择2022-04-18 2441
-
SPDK Thread模型设计与实现 NVMe-oF的使用案例2022-07-03 3730
-
vSphere 7.0 U1中的NVMe-oF的性能表征2023-08-04 737
-
NVMe在光纤上的未来优势2023-08-25 549
全部0条评论

快来发表一下你的评论吧 !
