

如何使用较小的语言模型,并用少量样本来微调语言模型的权重
描述
2020年,GPT-3可谓火出了圈。
不仅讲故事的本职工作做得风生水起,还跨界玩起了网页设计、运维、下象棋……
不过,尽管表现惊艳,GPT-3背后到底是实实在在的1750亿参数,想要在实际应用场景中落地,难度着实不小。
现在,针对这个问题,普林斯顿的陈丹琦、高天宇师徒和MIT博士生Adam Fisch在最新论文中提出,使用较小的语言模型,并用少量样本来微调语言模型的权重。

并且,实验证明,这一名为LM-BFF(better few-shot fine-tuning fo language models)的方法相比于普通微调方法,性能最多可以提升30%。
详情如何,一起往下看。
方法原理
首先,研究人员采用了基于提示的预测路线。
所谓基于提示的预测,是将下游任务视为一个有遮盖(mask)的语言建模问题,模型会直接为给定的提示生成文本响应。
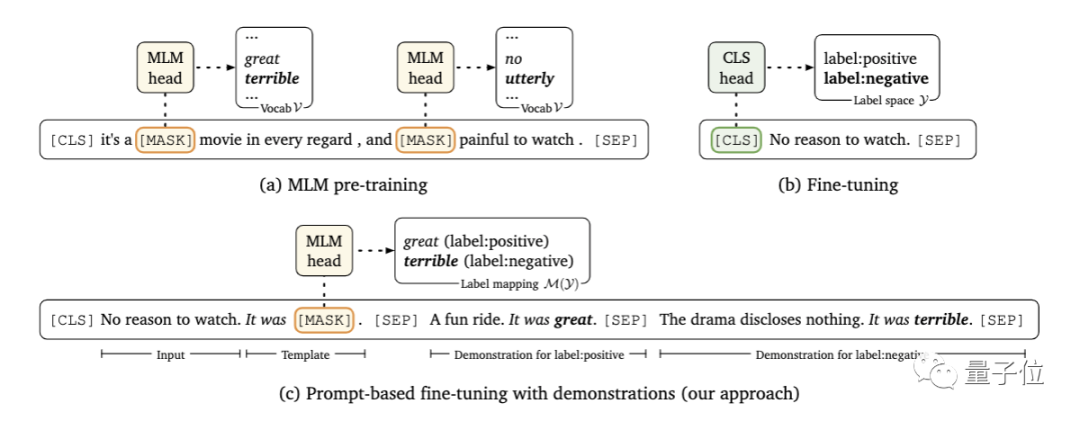
这里要解决的问题,是寻找正确的提示。这既需要该领域的专业知识,也需要对语言模型内部工作原理的理解。
在本文中,研究人员提出引入一个新的解码目标来解决这个问题,即使用谷歌提出的T5模型,在指定的小样本训练数据中自动生成提示。
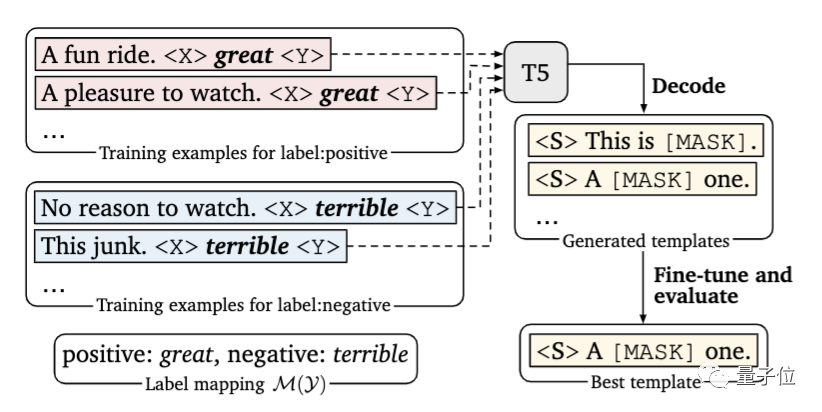
其次,研究人员在每个输入中,以额外上下文的形式添加了示例。
问题的关键在于,要有限考虑信息量大的示例,一方面,因为可用示例的数量会受到模型最大输入长度的限制;另一方面,不同类型的大量随机示例混杂在一起,会产生很长的上下文,不利于模型学习。
为此,研究人员开发了一种动态的、有选择性的精细策略:对于每个输入,从每一类中随机抽取一个样本,以创建多样化的最小演示集。
另外,研究人员还设计了一种新的抽样策略,将输入与相似的样本配对,以此为模型提供更多有价值的比较。
实验结果
那么,这样的小样本学习方法能实现怎样的效果?
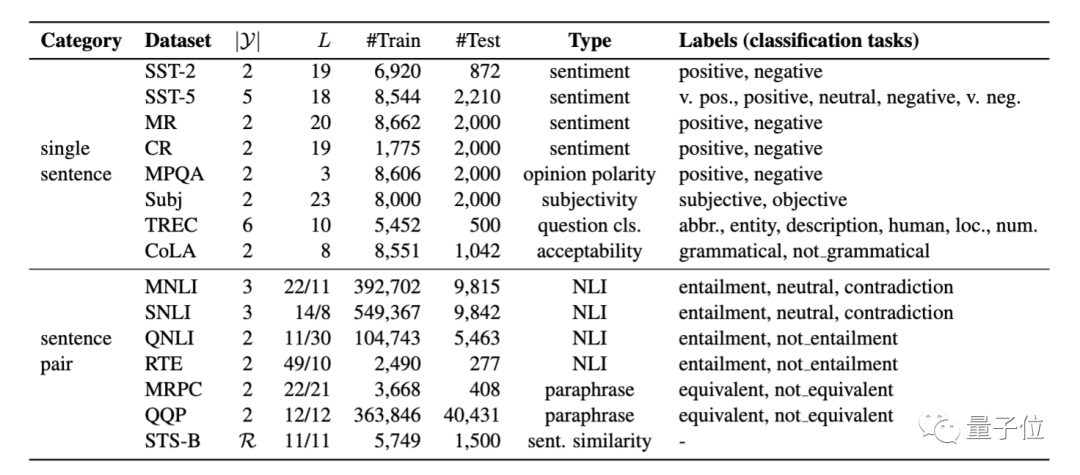
研究人员在8个单句、7个句子对NLP任务上,对其进行了系统性评估,这些任务涵盖分类和回归。
结果显示:
基于提示的微调在很大程度上优于标准微调;
自动提示搜索能匹敌、甚至优于手动提示;
加入示例对于微调而言很有效,并提高了少样本学习的性能。
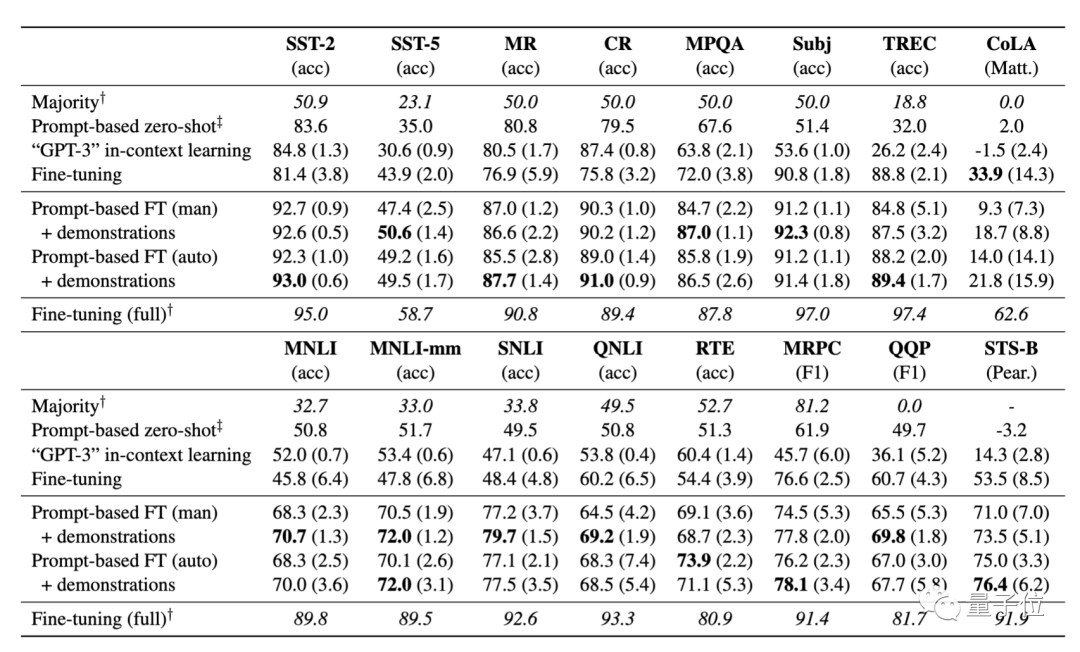
在K=16(即每一类样本数为16)的情况下,从上表结果可以看到,该方法在所有任务中,平均能实现11%的性能增益,显著优于标准微调程序。在SNLI任务中,提升达到30%。
不过,该方法目前仍存在明显的局限性,性能仍大大落后于采用大量样本训练获得的微调结果。
关于作者
论文有两位共同一作。
高天宇,清华大学本科生特等奖学金获得者,本科期间即发表4篇顶会论文,师从THUNLP实验室的刘知远副教授。
今年夏天,他本科毕业后赴普林斯顿攻读博士,师从本文的另一位作者陈丹琦。
此前,量子位曾经分享过他在写论文、做实验、与导师相处方面的经验。
Adam Fisch,MIT电气工程与计算机科学专业在读博士,是CSAIL和NLP研究小组的成员,主要研究方向是应用于NLP的迁移学习和多任务学习。
他本科毕业于普林斯顿大学,2015-2017年期间曾任Facebook AI研究院研究工程师。
至于陈丹琦大神,想必大家已经很熟悉了。她本科毕业于清华姚班,后于斯坦福大学拿下博士学位,2019年秋成为普林斯顿计算机科学系助理教授。
最后,该论文代码即将开源,如果还想了解更多论文细节,请戳文末论文链接详读~
传送门
论文地址:
https://arxiv.org/abs/2012.15723v1
项目地址:
https://github.com/princeton-nlp/LM-BFF
责任编辑:xj
原文标题:【前沿】陈丹琦团队最新论文:受GPT-3启发,用小样本学习给语言模型做微调,性能最高提升30%
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
-
【「基于大模型的RAG应用开发与优化」阅读体验】+大模型微调技术解读2025-01-14 2337
-
大语言模型开发语言是什么2024-12-04 1549
-
大语言模型如何开发2024-11-04 1195
-
大语言模型的预训练2024-07-11 1939
-
大模型为什么要微调?大模型微调的原理2024-07-10 8993
-
【大语言模型:原理与工程实践】大语言模型的预训练2024-05-07 1573
-
【大语言模型:原理与工程实践】核心技术综述2024-05-05 1192
-
【大语言模型:原理与工程实践】揭开大语言模型的面纱2024-05-04 892
-
【大语言模型:原理与工程实践】探索《大语言模型原理与工程实践》2024-04-30 1336
-
大语言模型简介:基于大语言模型模型全家桶Amazon Bedrock2023-12-04 1739
-
一种基于乱序语言模型的预训练模型-PERT2022-05-10 2618
-
基于深度学习的自然语言处理对抗样本模型2021-04-20 1496
全部0条评论

快来发表一下你的评论吧 !
