

机器学习中的Multi-Task多任务学习
描述
概念
当在一个任务中要优化多于一个的目标函数[1] ,就可以叫多任务学习
一些例外
「一个目标函数的多任务」:很多任务中把loss加到一起回传,实质优化的是一个目标函数, 但优化的是多个任务,loss相加是多任务学习的一种正则策略,对多个任务的参数起一种类似与均值约束的作用[2],所以也叫multi-task
「多个目标函数的单任务」:一些NLP中用main-task和auxiliary-task 辅助任务,很多辅助任务的loss并不重要,个人觉得这种虽然是多个loss,但是就是为了main-task ,不应该算多任务
动机
应用上节省资源,一个模型跑多个任务,单倍的时间双倍的快乐
感觉上非常的直观,好不容易花了30分钟都出门了,肯定多逛几个个商场,顺便剪个头发做个指甲
从模型的角度,学习得的底层的概率分布通常是对多个任务都是有效的
两种常见方式
参数的硬共享机制:从几十年前开始到现在这种方式还在流行(Multitask Learning. Autonomous Agents and Multi-Agent Systems[3]),一般认为一个模型中任务越多,通过参数共享降低噪声导致过拟合的风险更低,在参数硬共享机制中loss直接相加就是一种最简单的均值约束。
参数的软共享机制:每个任务都由自己的模型,自己的参数。对模型间参数的距离进行正则化来保障参数空间的相似。
混合方式:前两种的混合
为什么会有效
1. 不同任务的噪声能有更好的泛化效果
由于所有任务都或多或少存在一些噪音,例如,当我们训练任务A上的模型时,我们的目标在于得到任务A的一个好的表示,而忽略了数据相关的噪音以及泛化性能。由于不同的任务有不同的噪音模式,同时学习到两个任务可以得到一个更为泛化的表示
2. 辅助特征选择作用
如果主任务是那种,噪音严重,数据量小,数据维度高,则对于模型来说区分相关与不相关特征变得困难。其他辅助任务有助于将模型注意力集中在确实有影响的那些特征上。
3. 特征交流机制
在不同的任务之间的特征交互交流,对于任务B来说很容易学习到某些特征G,而这些特征对于任务A来说很难学到。这可能是因为任务A与特征G的交互方式更复杂,或者因为其他特征阻碍了特征G的学习。
4. 相互强调(监督)机制
多任务学习更倾向于学习到大部分模型都强调的部分。学到的空间更泛化,满足不同的任务。由于一个对足够多的训练任务都表现很好的假设空间,对来自于同一环境的新任务也会表现很好,所以这样有助于模型展示出对新任务的泛化能力(Deep Multi-Task Learning with Low Level Tasks Supervised at Lower Layers[4]、Emotion-Cause Pair Extraction: A New Task to Emotion Analysis in Texts[5]),非常适合迁移学习场景。
5. 表示偏置机制
如归约迁移通过引入归约偏置来改进模型,使得模型更倾向于某些假设,能起到一种正则效果。常见的一种归约偏置是L1正则化,它使得模型更偏向于那些稀疏的解。在多任务学习场景中,这会导致模型更倾向于那些可以同时解释多个任务的解。
为什么无效
先说是不是,再问为什么.
在Identifying beneficial task relations for multi-task learning in deep neural networks[6]中,作者探究到底是什么让multi-task work, 作者使用严格意义上相同的参数用NLP任务做了对比实验,图中分别是两个任务结合时与单任务loss的对比,大部分多任务的效果比不上单任务,作者的结论是单任务的主要特征在起作用,那些多任务结合效果好的情况,是「主任务比较难学(梯度下降比较缓慢),辅助任务比价好学的时候,多任务会有好效果」
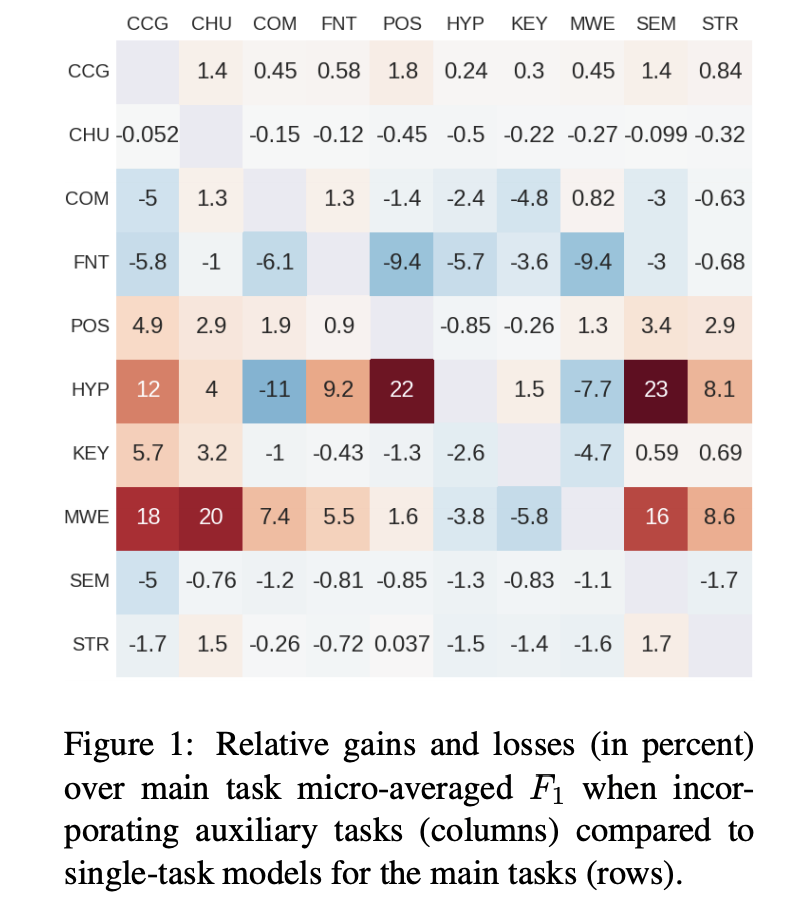
为什么会无效?因为所有有效的原因都有它的负向效果
不同任务的噪声提高泛化,在模型容量小的时候引入的噪声也无法忽视。
特征的选择,交流这些起作用的机制会产生一种负迁移(Negative Transfer),共享的信息交流的信息反而是一种误导信息
...
Muti-task的一些思路
1. 对任务间的不同强制加稀疏性约束的正则化项
如块稀疏正则化,对于不同任务的参数,加l1正则,或者l1/lx, x>1等的正则,起任务参数的选择,让模型自动去选择应该共享哪些参数, 在keras的multi-task框架中,就是多个任务的loss相加后,用一个优化器优化,就是这种思路
2. 对中间层添加矩阵先验,可以学习任务间的关系
3. 共享合适的相关结构
高层次监督(High Supervision),共享大部分结构,后面直接输出分叉那种共享(就是大多数人入手的multi-task),个人觉得除非有很精致的一些调整,感觉效果很难超多个single-task.
低层次监督(Low Supervision),Deep Multi-Task Learning with Low Level Tasks Supervised at Lower Layers中,在NLP中,作者使用deep bi-RNN低层开始对各个任务分别建模,不共享的部分模型更新时不受其他任务影响,效果不错。
4. 建模任务之间的关系
建模任务之间的关系有非常多的方式,如,加各种约束项,这个约束项,让不同任务的参数空间,尽量平均, 有很多方式花式拓展,正则也是一种约束项,loss相加也是一种建立任务之间关系的约束项目,如 Learning Multiple Tasks with Kernel Methods[7]对模型聚类 ,a是任务参数,让各种任务参数空间尽量靠近
a是各个任务的参数
特征交互,在 Emotion-Cause Pair Extraction: A New Task to Emotion Analysis in Texts 中,作者通过不同任务的高层特征交互,同时完成情感向判断和情感向原因提取,这跟有些多模态特征fusion的方式很相似,
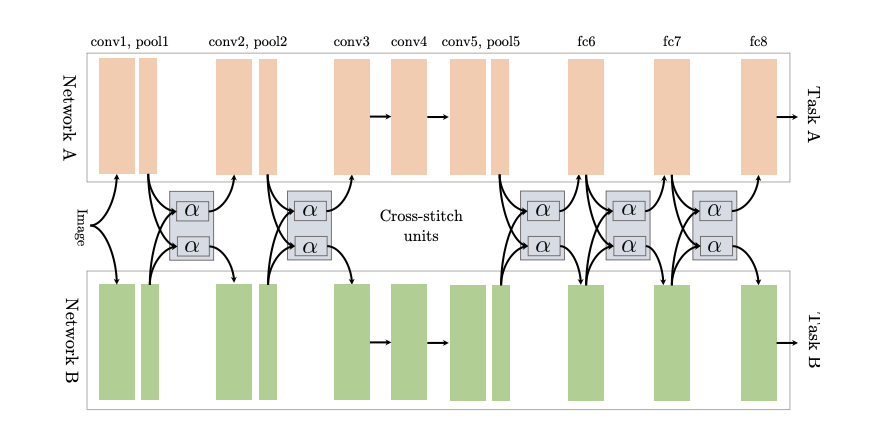
Cross-Stitch Networks for Multi-Task Learning[8]将两个独立的网络用参数的软共享方式连接起来, 用所谓的十字绣单元来决定怎么将这些任务相关的网络利用其他任务中学到的知识,并与前面层的输出进行线性组合。
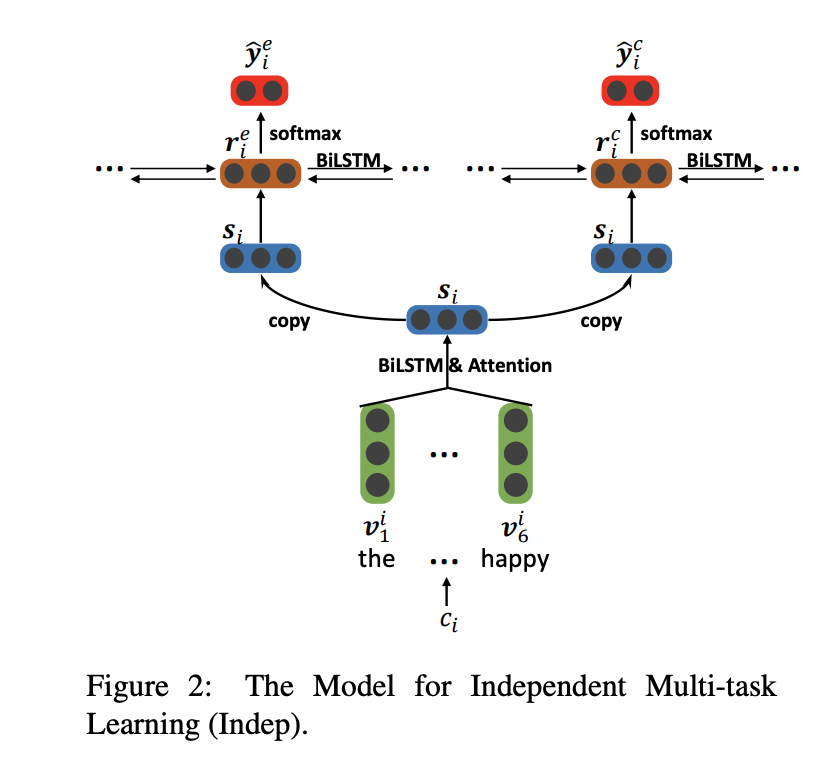
串行的联合多任务模型(A Joint Many-Task Model)
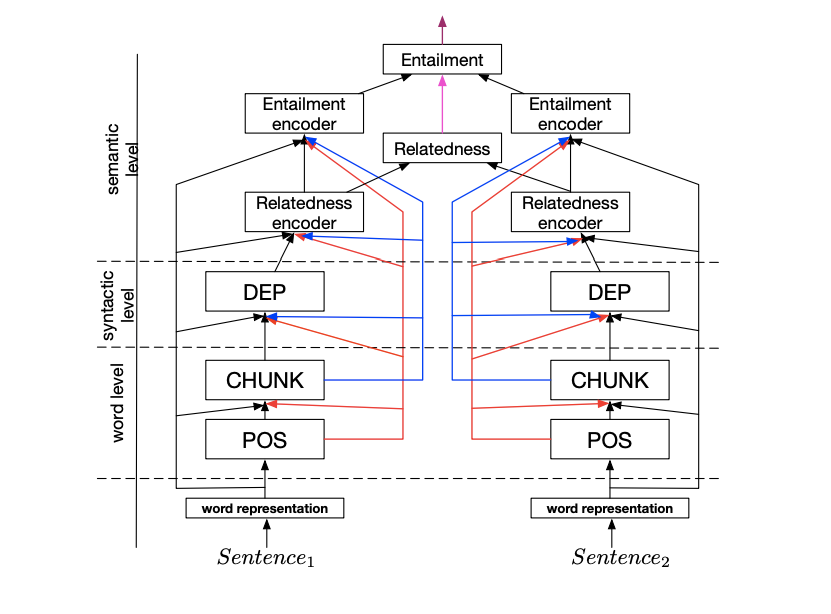
NLP 领域中,各个任务间经常是有层级关系,A Joint Many-Task Model: Growing a Neural Network for Multiple NLP Tasks[9]中在多任务并行的同时,加了串行结构,例如具体任务:词性分析 POS->语块分析 CHUNK->依存句法分析 DEP->文本语义相关 Relatedness->文本蕴涵 Entailment,每个子任务都偶有自己的loss, 然后又会作为其他任务的输入
5. 用loss调整任务之间的关系
Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics[10] 用同方差不确定性对损失进行加权(Weighting losses with Uncertainty),作者认为最佳权值与不同任务的衡量规模和噪声相关,而噪声中除了认知不确定性,异方差不确定性,这些取决于数据的不确定性外,作者把同方差不确定性作为噪声来对多任务学习中的权重进行优化,作者根据噪声调整每个任务在代价函数中的相对权重,噪声大则降低权重,反之。
GradNorm: Gradient Normalization for Adaptive Loss Balancing in Deep Multitask Networks[11] 基于不同任务loss的降低速度来动态调整权值, 作者定义了另外一个专门针对权值的优化函数
是每个任务的loss相对第一步loss的优化程度, 是每一步 对 task 任务的梯度,即如果某个任务的优化程度小,这个loss会超那么就调大这个任务的权值优化,达到个loss学习程度的平衡
应用|适用任务
辅助任务,相关性任务,对抗性任务....等[12]
责任编辑:xj
原文标题:Multi-Task 多任务学习, 那些你不知道的事
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
-
Multi Task Learning在工业界如何更胜一筹2018-04-24 2834
-
基于 stm32 的 FreeRTOS 的详细移植步骤及其多任务应用 精选资料分享2021-08-03 1290
-
keil下的FreeRtos多任务程序学习2022-02-21 1416
-
【晶心科技ADP-Corvette-T1开发板试用体验】corvette T1的多任务调度学习2022-07-10 4590
-
一种由数据驱动的多任务学习炼钢终点预测方法2017-12-05 1149
-
NLP多任务学习案例分享:一种层次增长的神经网络结构2018-01-05 6328
-
ABB机器人怎样多任务?ABB机器人多任务使用方法步骤详解2018-06-11 33570
-
迁移学习、多任务学习领域的进展2018-09-04 4666
-
AI实现多任务学习,究竟能做什么2020-05-13 1096
-
关于多任务学习如何提升模型性能与原则2021-03-21 3853
-
嵌入式程序设计学习(6)2021-12-27 527
-
一个大规模多任务学习框架µ2Net2022-07-21 2264
-
机器学习算法总结 机器学习算法是什么 机器学习算法优缺点2023-08-17 3239
-
NeurIPS 2023 | 扩散模型解决多任务强化学习问题2023-10-02 1992
-
揭秘LuatOS Task:多任务管理的“智能中枢”2025-08-28 907
全部0条评论

快来发表一下你的评论吧 !
