

一文知道高性能接口的设计准则
接口/总线/驱动
描述
高并发经常会发生在有大活跃用户量,用户高聚集的业务场景中,如:秒杀活动,定时领取红包等。
为了让业务可以流畅的运行并且给用户一个好的交互体验,我们需要根据业务场景预估达到的并发量等因素,来设计适合自己业务场景的高并发处理方案。
在工作这些年里,我有幸遇到了高并发各种坑,对如何设计高性能接口有一些经验,其实无外乎满足以下几个特点:
灵敏性
伸缩性
容错性
事件驱动/消息驱动
高性能接口设计准则
在引言里我也说了高性能设计的四个准则,现在具体对这四个准则做一些描述;
1. 灵敏性
应用程序应该尽可能快的对请求做出响应。
如果可以在顺序获取数据和并行获取数据之间进行选择的话,为了尽快向用户返回响应,始终应该优先选择并行获取数据,可以同时请求互相没有关联的数据。当我们需要请求多个互相无关,没有依赖的数据的时候,应该考虑是否能够同时请求这些数据。
如果可能出现错误,应该立即返回,将问题通知用户,不要让用户等待直到超时。
1.1 如何设计灵敏性
缓存前置
对于一些改变不频繁的数据,应该放在分布式缓存中,例如redis,如果是一些元数据(例如,一些计数器的配置信息,变量的配置信息等)则应该启用本地缓存,简单流程如下:
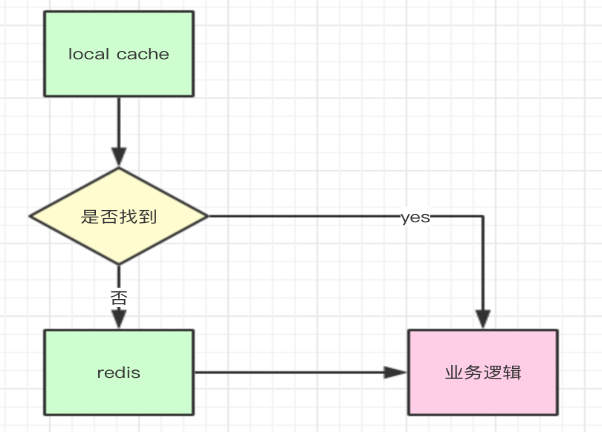
如果一些热点数据不大的话,建议服务启动的时候就应该提前加载到缓存中,这样可以提高服务的性能。
读写拆分部署
如果你的服务既涉及到读操作,也涉及到写操作, 应该将读写隔离部署,这样读服务的压力不会影响到写服务,写服务的压力不会影响到读服务。流程如下:
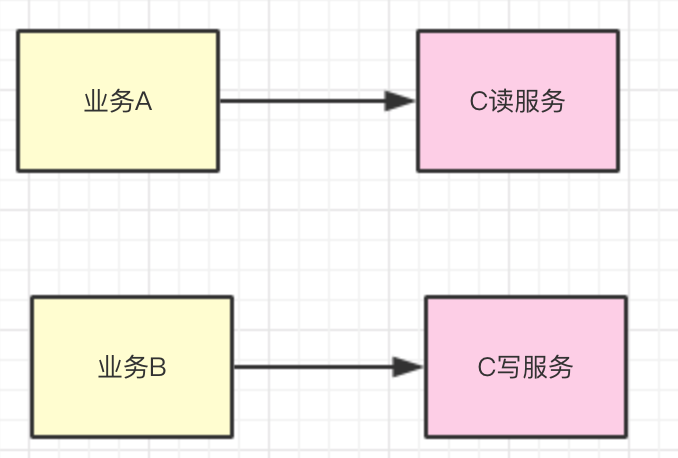
当然除了按照读写进行拆分部署外,还可以按照业务进行隔离部署。
对等设计、无状态
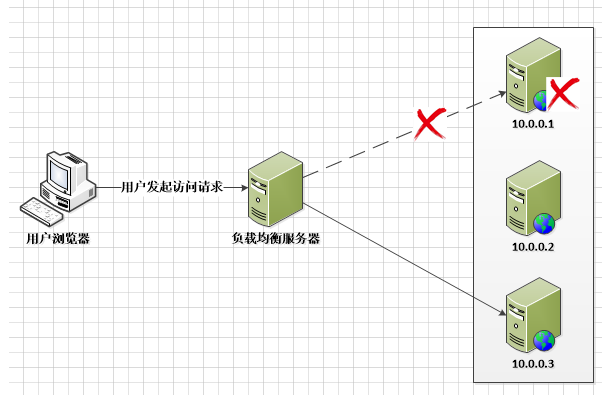
所谓无状态是指应用服务器不保存业务的上下文信息,而仅根据每次请求提交的数据进行相应的业务逻辑处理,多个服务实例(服务器)之间完全对等,请求提交到任意服务器,处理结果是完全一样的。
不保存状态的应用给高可用的架构设计带来了巨大便利,既然服务器不保存请求的状态,那么所有的服务器完全对等,当任意一台或多台服务器宕机,请求提交给集群中的其他任意一台可用机器处理,这样对终端用户而言,请求总是能够成功的,整个系统依然可用。对于应用服务器集群,实现这种服务器可用状态实时检测、自动转移失败任务的机制就是负载均衡。
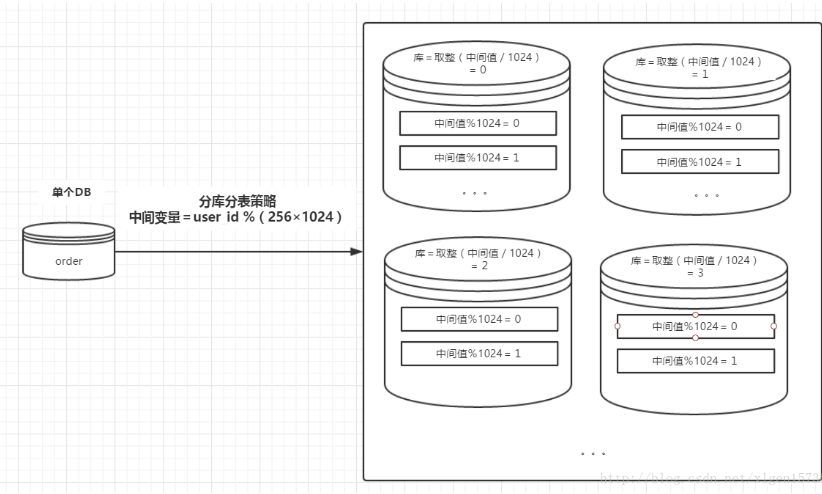
DB分库分表,读写分离
对于数据层来说,如果数据量不大,db可以采用读写分离部署,对于读多写少的场景可以解决一部分压力,从而提高我们接口的响应速度,如果写的数据量和读的数据量都很大,那么就必须要对db进行分库分表外加读写分离了。
2. 伸缩性
应用程序应该能够根据不同的工作负载进行伸缩扩展(尤其是通过增加计算资源来进行扩展)。为了提供伸缩性,系统应该努力消除瓶颈。
如果在虚拟机上运行内存数据库,那么添加另一个虚拟几点就可以将所有的查询请求分布到两台虚拟服务器上,将可能的吞吐量增加至原来的两倍。添加额外的节点应该能够几乎线性的提高系统的性能。
增加一个内存数据库的节点后,还可以将数据分为两半,并将其中的一半移至新的节点,这样就能够将内存容量提高至原来的两倍。添加节点应该能够几乎线性的提高内存容量。
所以一般好的接口设计是可以通过水平扩展机器来达到提升性能的,这就要求我们设计接口的时候提现无状态性。
3. 容错性
应用程序应该考虑到错误发生的情况,并且从容的对错误情况做出响应。如果系统的某个组件发生错误,对与该组件无关的请求不应该产生任务影响。错误是难以避免的,因此应该将错误造成的影响限制在发生错误的组件之内。如果可能的话,通过对重要组件及数据的备份和冗余,这些组件发生错误时不应该对其外部行为有任何影响。
假设你的系统既使用了redis,也使用了mysql对数据进行处理,当redis或着mysql挂了的时候,程序应该可以继续提供服务,而不是一味的报错。流程如下:
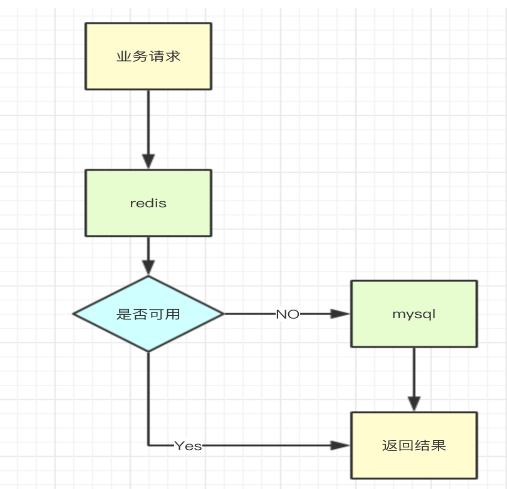
当一个组件不可用的时候,可以使用开关对某一个组件进行降级,常见的降级方式分为手动降级和自动降级,手动降级可以借助zookeeper进行,自动降级可以使用Hystrix。
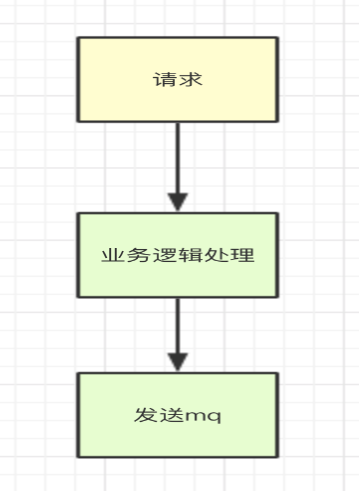
4. 事件驱动/消息驱动
使用消息而不直接进行方法调用提供了一种帮助我们满足另外3个高性能设计准则的方法。消息驱动的系统着重于控制何时、何地以及如何对请求做出响应,允许做出响应的组件进行路由以及负载均衡。
由于异步的消息驱动系统只在真正需要时才会消耗资源(比如线程),因此它对系统资源的利用更为高效。消息也可以被发送到远程机器(位置透明)。
通常不是万不得已,否则我们认为丢失一部分数据换取服务的高性能,这是值得的。如果能容忍数据的部分丢失(在可接受范围内),比如保存数据到db,异步计算耗时的任务,通过消息队列将是提升我们系统性能的比较好的方式。
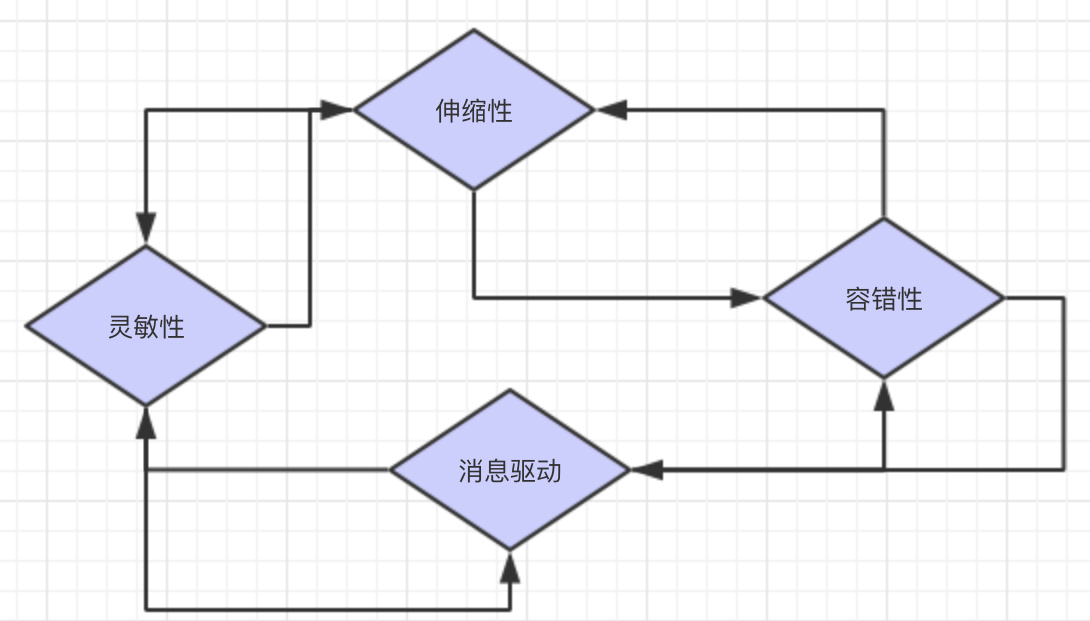
总结
4个设计准则之间并不是完全独立的。为了满足某个准则而采取的方法通常也对满足其他准备有所帮助。例如,如果发现某个服务响应速度较慢,我们可能会在短时间内停止再向该服务发送请求,等待其恢复正常,并立即向用户返回错误信息。这样做降低了响应慢的服务不堪重负直接崩溃的风险,因此也提高了系统的容错性。除此之外,我们立即告知了用户系统发生的问题,也就改善了系统的响应速度,如图所示:
责任编辑人:CC
-
#硬声创作季 家里的音箱坏了,便制作了一个高性能的移动音箱Mr_haohao 2022-10-20
-
FPGA_ASIC高性能数字系统设计2011-03-02 4761
-
LKT4300 32位高性能多接口加密芯片2014-02-11 2616
-
与高性能流水线ADC的接口2019-05-17 1478
-
请问如何设计存储器接口才能获得高性能?2021-04-14 1468
-
如何去实现一种高性能网络接口设计?2021-05-20 1475
-
基于CAN总线的智能接口卡的设计2009-06-18 886
-
一种基于LTCC的高性能超宽带带通滤波器_李博文2017-01-08 1091
-
识别和解决与高速数据收集相关的常见问题的准则详细概述2018-05-07 835
-
DSP 上的串行 RapidIO 接口及高性能应用2018-06-12 5171
-
3PEAK 高性能接口电路:RS-232、RS-485收发器2020-04-30 7731
-
高性能接口设计准则2020-08-03 4114
-
Xilinx 7系列FPGA高性能接口与2.5V/3.3V外设IO接口设计2023-05-15 6857
-
什么是type-c全功能接口 Type-C充电接口和type-c全功能接口有什么不同2023-08-03 58877
-
克服设计难题-实现高性能接口2024-08-28 446
全部0条评论

快来发表一下你的评论吧 !
