

爬虫技术涉案大数据分析及法律解读
描述
爬虫技术涉案大数据分析及法律解读
爬虫技术作为一种前端获取网站信息数据的技术,在目前大数据应用的背景下,异常火热。但是由于使用者的不谨慎,也出现了很多涉案甚至涉罪情况。技术本身是无罪的,但是不代表使用技术的人也无罪。
许多律师在写一些关于目前爬虫技术的法律文章的时候,常常会将定点爬虫和搜索引擎爬虫给搞混淆,有的也给出了错误或者较为过时的定义与理解。作为不熟悉技术的法律人士,其实也在所难免。其实我们常常讲的爬虫技术,与搜索引擎的爬虫引擎是完全不同的,其根本目的,是通过对指定网站进行解析,自动并且批量获取前端展示的数据。简单来说,就是一种信息采集技术,“爬虫”的称呼,只是一种俗称,我更愿意科学地称其为“网站信息自动化采集技术”。本文以下所称的爬虫,皆为定向爬虫。
爬虫技术不是什么高深的技术,更不是什么“黑客技术”,甚至对于一些静态网站,一个大学编程初学者,都可以轻松掌握自动化采集信息的技术。目前主流的爬虫技术大致可以归类为两类:
1、 网站渲染后,通过正则表达式匹配前端代码,获取所需信息,以此往复。
2、 不通过网站渲染,或只经过少量渲染,直接通过网站的API接口进行动态调用。
技术含量高一点的爬虫技术,都是跳过网页静态内容的渲染,直接调用动态API接口,以达到最高效获取信息的目的。部分法律人士认为这是跳过了网站验证机制,我觉得得个案细分,毕竟绝大多数的网站(99%),API接口都是直接暴露的。
如果读者是法律从业人员,首先需要明确以下几点,可能才能更好的理解爬虫技术:
1、爬虫技术获取的信息全部都是网站公开信息(或面向爬取者公开)
2、爬虫技术不会获取任何被爬取网站的后台权限
如果违背了以上两个条件,那就不是爬虫技术了,就是入侵计算机系统技术了,俗称“黑客”技术。下面,通过爬虫技术获取对裁判文书进行检索,给大家简单展示一下,爬虫技术近年来刑事案件获罪的情况,部分图表通过Python语言实现。
(样本检索关键词:爬虫、数据抓取、数据爬取,时间点截止至2019-11-15,并对不相干的文书进行了删除,其中一篇文书将“侵犯公民个人信息罪”写成了“公民个人信息罪”,进行了修正。全部是一审、且二审未大幅度改判的文书数据。有效文书共计22篇。)
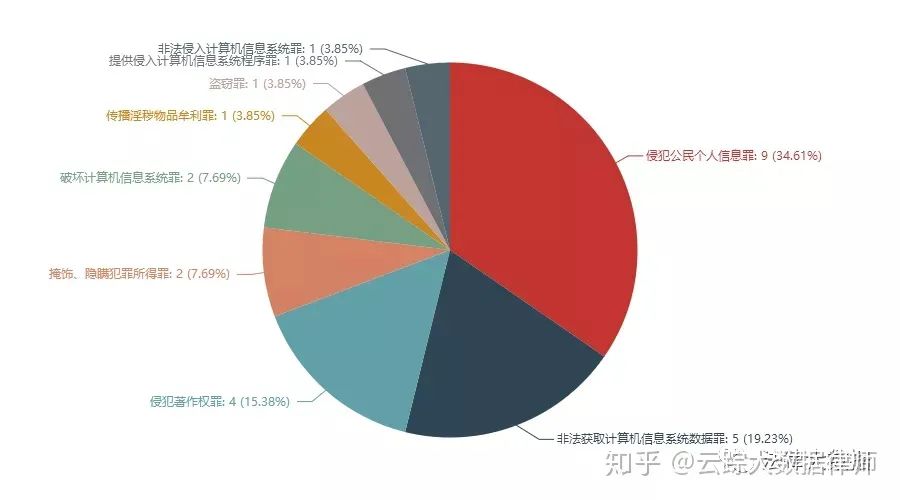
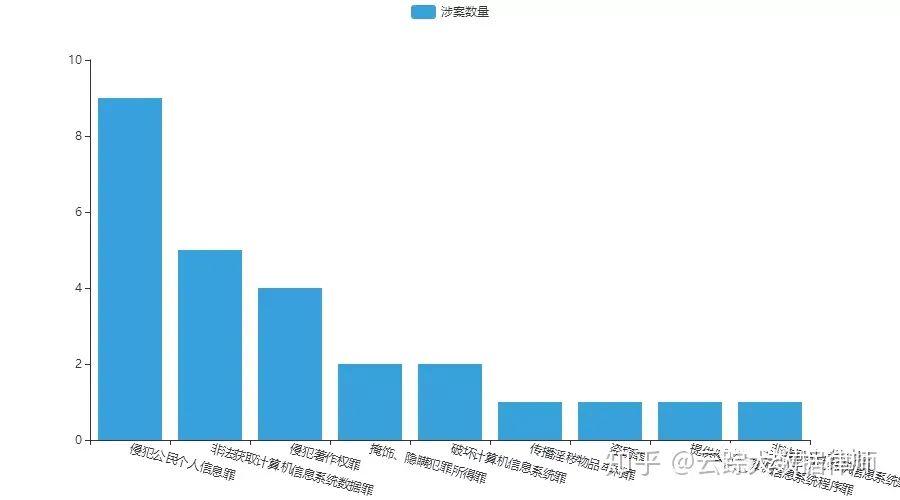
涉案罪名数量及比例(饼图)
(涉案文书地域分布情况)
总结:
以上文书案例,最早的裁判时间为2014-07-07(郑×等侵犯著作权罪一审刑事判决书),最晚的裁判时间为2019-10-28(北京瑞智华胜科技股份有限公司、周嘉林、黄健等违法运用资金罪一审刑事判决书)。从数据中可以看到侵犯公民个人信息罪是重灾区,非法获取计算机信息系统数据罪则是样本中刑期最重的罪名。
样本中较为受人关注的案件有“上海晟品网络科技有限公司、侯明强等非法获取计算机信息系统数据罪一审刑事判决书”,俗称“今日头条爬虫案”。感兴趣的读者可以搜索笔者的另一篇文章《爬虫获取数据获刑案件解析及无罪论点探讨》
如果你是程序员读者或者大数据从业者,亦或者是爬虫工作室,如何区分罪与非罪的界限,提防职业风险呢?笔者在此不做过多阐述,仅提出以下几点意见供参考:
1、 不爬取目标网站的个人信息内容以及公民隐私;
2、 不交易爬取的目标公司的商业数据;
3、 对有版权的内容的爬取应审慎,未获授权商业使用则违法。
值得注意的是,在获得授权的情况下,利用爬虫技术获取信息,不违反法律。但是,超出授权内容,再次使用,则有可能触犯法律。举例来说,你获得用户的授权,利用爬虫技术调用该用户的个人信息,不触犯法律。但是未经该用户许可,再次使用该用户个人信息,甚至利用该信息牟利,则严重违反法律。
最后,笔者想要强调的是,不是公开的信息爬取就是不违法的。比如网站的用户信息,一样受到法律保护。但是在处罚爬虫从业者的同时,网站对个人信息的公开化处理,更应该受到行政处罚,不应将爬虫程序员送进牢房而得到豁免。比起不懂法的小作坊程序员,大公司对用户信息数据的滥用和疏于管理,更加令人不齿。对于公检法工作者以及律师工作者,在面对此类刑事案件中,不要听到爬虫技术,就将其妖魔化,关注的重点,还是应该放在获取方式的合法性上,对绝大多数情况下来说,对于公开信息的获取,是很难定义为“非法手段”上去的,因此一定要慎重。对于商业领域的内容竞争,在民事领域有法律适用的,不要轻易“以刑代民”。不仅会给行业的普通从业者带来恐慌,也会做出负面的引导。
原文标题:我写的代码合规吗?【HDZ研习社25期】
文章出处:【微信公众号:华为开发者社区】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
【NanoPi K2试用申请】微博爬虫数据分析以及家庭媒体中心2017-06-12 3135
-
Quick BI助力云上大数据分析---深圳云栖大会2018-04-03 3201
-
大数据分析逻辑2018-10-08 2510
-
工业大数据分析平台的应用价值探讨2018-11-12 3642
-
Python爬虫全国大学招生的生源数据分析2020-03-09 2136
-
0基础入门Python爬虫实战课2021-07-25 2476
-
Get职场新知识:做分析,用大数据分析工具2023-12-05 3455
-
大数据分析,半导体技术必不可少?2013-01-21 2032
-
什么是大数据分析?大数据分析的含义与目前形式2018-10-12 17467
-
大数据分析如何来增强2020-01-26 1817
-
大数据分析技术架构的通用模块2020-10-29 3703
-
还在为大数据分析工具发愁?以下是2021最值得推荐的大数据分析工具2021-03-05 3193
-
什么是大数据分析2023-05-19 3279
-
网络爬虫,Python和数据分析2024-07-13 702
-
raid 在大数据分析中的应用2024-11-12 1557
全部0条评论

快来发表一下你的评论吧 !
