

在风格迁移中如何进行数据增强
描述
这是一篇关于风格迁移中如何进行数据增强的论文。在introduction部分,informal-->formal 的风格迁移问题,最大的障碍是训练数据的不足。为了解决此问题,本篇论文提出三种数据增强的方法来获得有用的语句对,分别为
back translation (BT)
我们使用原始语料库训练一个seq2seq模型。其中将formal语句作为模型的输入,让seq2seq模型有能力输出对应的informal句子。则 模型输入的formal语句和输出的informal语句就构成了一个新的语句对。
formality discrimination (F-Dis)
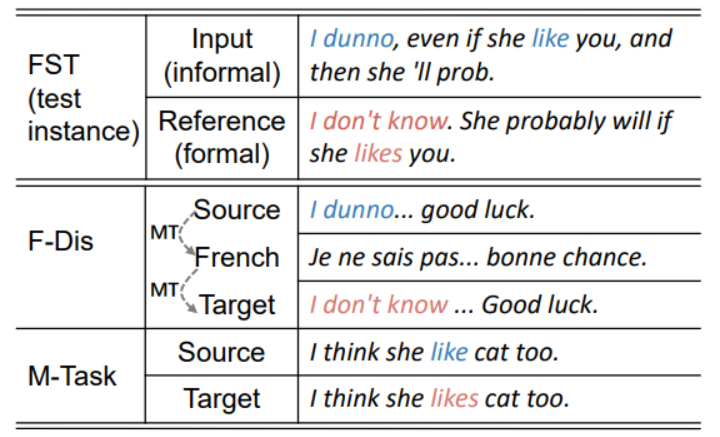
F-Dis方法使用机器翻译模型,将一个informal句子重写为formal句子。首先使用Google翻译API 将这些informal语句翻译成 其他语种(比如法语),然后又翻译回英语。如下图所示:

其中,informal语句可以从网上论坛上收集得到。
表示收集到的第i条句子(informal), 是最后翻译回的句子(formal), 二者构成了一个新的语句对。
本方法同时使用CNN构建了一个“格式判别器”:用来给一个句子的“正规”程度 打分。就是上图中右边括号内的小数。最终选出的新数据集要求如下:
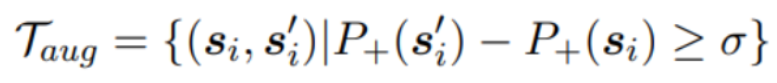
其中表示句子的“正规”程度, 是阈值
multi-task transfer (M-Task)
我们观察到,formal语句通常语法正确,而informal语句的语法经常出错。
前人研究表明,对FST的输出再使用一个语法错误纠正模型( grammatical error correction model,GEC)可以提高模型效果。受此启发,本论文直接使用GEC的训练数据作为增强的新数据集。如下图
模型训练
上面提到的seq2seq模型为Transformer (base)。
本论文首先使用增强的新数据用于 预训练,然后使用原始语料数据做微调,将这称为pre-training & finetuning (PT&FT)方法。下面结果证明了PT&FT的效果优于ST方法。ST是把增强数据和原数据一起训练。
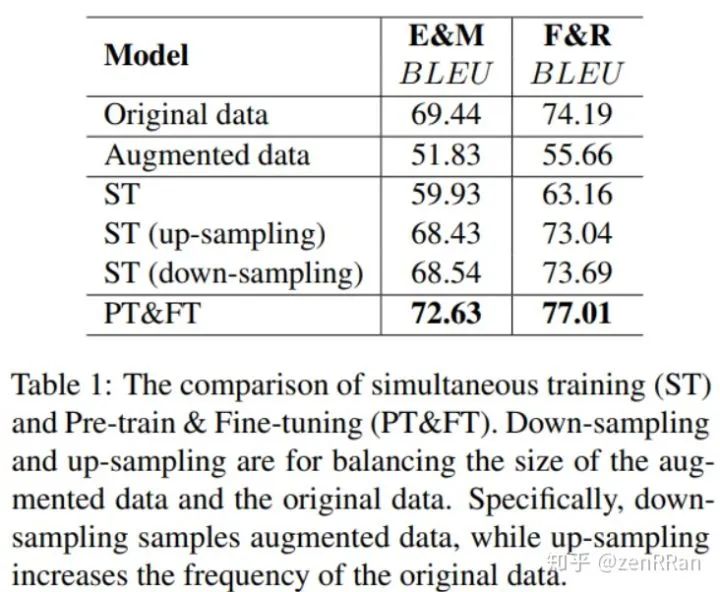
下图展现了三种数据增强方法的效果:
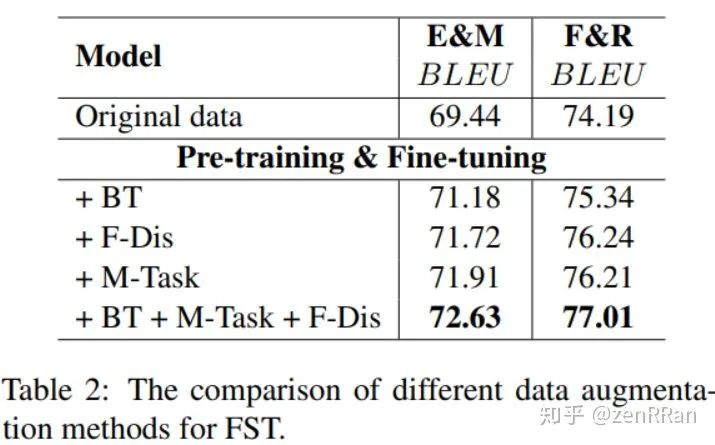
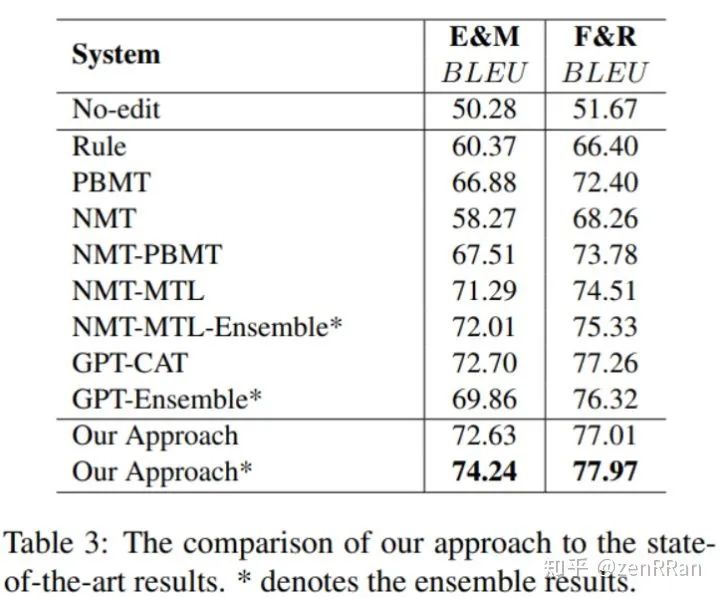
下图展现了我们的方法与前人模型的比较结果:
责任编辑:xj
原文标题:【ACL2020】关于正式风格迁移的数据增强方法
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
-
在labview中如何进行数据存储?2013-07-26 8005
-
请问问手机与电脑之间在没有网络的情况下如何进行数据传输!2015-05-31 6667
-
怎样使用XP迁移助手进行数据备份、还原2016-04-11 2795
-
HX711如何进行数据处理?2016-11-21 6305
-
NAS网络存储中如何进行在线阵列迁移2021-03-23 7766
-
【洞幺邦】基于深度学习的GAN应用风格迁移2021-07-01 8137
-
STM32 USART串口是如何进行数据处理的呢2021-11-25 1440
-
应用程序和驱动程序之间是如何进行数据交换的2021-12-23 2125
-
迁移学习2022-04-21 11454
-
什么是信号处理?如何进行数字信号处理呢?2010-03-06 3632
-
Python在音频(Audio)领域中,如何进行数据扩充呢?2018-04-15 11010
-
数据库教程之如何进行数据库设计2018-10-19 2135
-
数据库系统概论之如何进行数据库编程的资料概述2018-11-15 1417
-
HarmonyOS中如何进行跨端迁移2021-11-15 3593
-
基于OpenCV的DNN图像风格迁移2023-10-30 1658
全部0条评论

快来发表一下你的评论吧 !
