

AMD从小芯片CPU走向小芯片GPU
电子说
描述
在HPC应用上,对突破性能的追求是从未停歇的,尤其是在人工智能、机器学习和大数据分析等新兴应用提出更高的性能要求后。但制程突破的速度已经逐渐放缓,每个工艺节点带来的频率红利也在慢慢变小。而为了减少生产和开发成本,提高良率,不少CPU制造商都开始看向小芯片。 2020年的最后一天,AMD公布了自己在小芯片GPU上的专利,引起了不少热议。大家都在猜测,小芯片是否能成为后摩尔时代芯片设计创新的利器呢?
AMD:从小芯片CPU走向小芯片GPU
AMD从很早开始就在小芯片上发力了,不管是EPYC服务器CPU还是线程撕裂者桌面CPU,都大量运用了小芯片设计。在AMD看来,传统的单片处理器将一个或多个CPU核心放置在单个裸片上,以此加速时钟频率和缓存读取,虽然这种策略对于需要重度CPU使用的工作来说非常合理,但仍有其限制。而小芯片设计可以带来更快的架构创新,尤其是在数据中心等应用上。 在去年的ISSCC 2020上,AMD重点提到了小芯片在第二代EPYC服务器CPU上带来的优势。运用Zen 2架构的EPYC服务器CPU上,AMD在CPU核心上运用了台积电代工的7nm小芯片,IOD仍然采用Global Foundries的14nm制程。AMD提到这种设计实现了更高的核心数和更高的性能,而且显著降低了成本。 而AMD近期公布的小芯片GPU专利同样掀起了不小的浪花,该专利展示了一种使用高带宽交联的小芯片GPU设计方案。
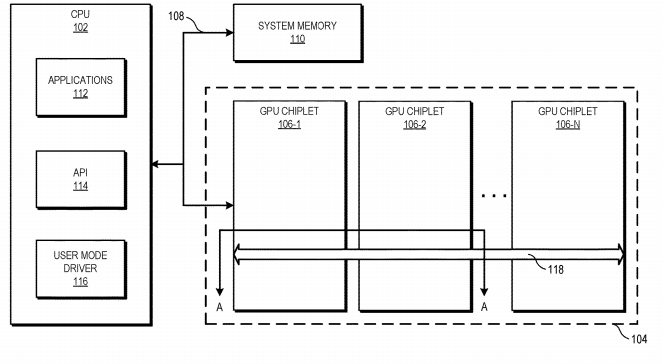
小芯片GPU / AMD 在该专利中,AMD提到,由于多数应用是以单个GPU为前提写就的,所以为了保留现有的应用编程模型,将小芯片设计实现在GPU上向来都是一大挑战。而该专利利用一根总线将第一个GPU小芯片与CPU相连,余下的GPU用被动交联连接。 如今许多架构至少拥有一级缓存连贯分布在整个GPU裸片上,比如L3或其他最后一级缓存(LLC)。而这种设计中,这些物理资源被放置在不同的裸片上,并提供通信连接以保证其缓存连贯性。在工作过程中,内存地址请求从CPU发往一个GPU小芯片,后者与高带宽被动交联沟通以定位所需数据,因此从CPU的角度来看,仍然是在一个单独的GPU上寻址。
Intel:以小芯片打造客户2.0的芯片
芯片方案演化 / Intel Intel在去年的架构日上给出了他们在IP/SOC上的策略改变,在过去整合的单片SOC中,开发周期长达3到4年,而且在投入使用后,制造商和用户会在芯片上发现上百个Bug。而演化至多裸片的基本小芯片结构后,将GPU、CPU和IO放置在不同的裸片上,开发周期缩减至2-3年,Bug数目缩减至十数个,不仅如此,小芯片设计还可以重复使用。最后则是Intel对未来小芯片结构的展望,将不同的IP放在最优制程的小芯片上,比如内存、I/O或图形等,从IP或小芯片层面上来做验证,因此Bug数目不足十个,开发周期仅需1年。

客户2.0方案 / Intel 这样的设计也让Intel对芯片定位有了更多的自由,比如游戏玩家需要更多的图形性能,而开发者则更渴求高算力的和强大的AI性能等。这也就是Intel设想的客户2.0愿景,通过智能感知带给消费者无缝的高性能体验。 尽管GPU一直是Intel的弱项之一,但这并不代表Intel没有在显示领域上发力。自从Intel从AMD的图形部门挖走首席架构师Raja Koduri以来,Intel就开始在独立显卡上发力。Intel于2019年末公布了超算级别的GPU,代号名为Ponte Vecchio,该GPU基于7nm工艺和小芯片技术,将于2021年年内安装在Aurora超级计算机上作为图形加速器使用。
小芯片的后盾:新的互联与封装技术
如果没有创新的互联与封装技术,小芯片设计同样是无法立足的。在小芯片的封装上,Intel已经规划好了详细的封装路线图。

处理器封装路线图 / Intel 在Kaby Lake G处理器和Agilex FPGA上,Intel已经实现了EMIB这种2.5D的封装方式。而Intel在Lakefield系列处理器上使用的Foveros 3D封装技术则是对EMIB的进一步补充,该技术可将凸起高度进一步降低至50-25um,并实现接近1000 IO/mm2的密度。
Infinity架构 / AMD 但要想分解后的小芯片也能保持联通,这就是互联技术派上用场的地方,比如AMD在Zen架构CPU中引入的Infinity Fabric。AMD将Infinity Fabric视为连接各大产品线的基石,通过第三代Infinity框架,AMD得以为CPU与GPU之间提供大带宽和低延迟的连接、统一的内存访问,提升AMD产品的结合性能并简化编程。
小结
去年的全球硬科技创新大会上,芯动科技、紫光存储等成立了中国Chiplet产业联盟,推动国内的小芯片发展。芯动科技在2020年推出了国产自主Chiplet标准INNOLINK,让庞大的数据在小芯片之间低延迟传输。
INNOLINK解决方案 / 芯动科技 至于AMD的小芯片GPU,其实如此架构可能更有可能用于未来的CDNA数据中心GPU,而不是下一代RDNA消费级GPU。因为对于消费级GPU来说,很大一部分场景是对延迟极度敏感的游戏应用,这正是小芯片GPU必须要先突破的限制,如果小芯片GPU有着SLI和CrossFire一样大的延迟的话,无疑也会淡出人们的视野。
原文标题:在小芯片CPU尝到甜头,AMD向Chiplet GPU进发!
文章出处:【微信公众号:电子发烧友网】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
X-Silicon发布RISC-V新架构 实现CPU/GPU一体化2024-04-08 1526
-
RISC-V芯片新突破:CPU与GPU一体化核心设计2024-04-07 1877
-
Nvidia与AMD新芯片,突破PCIe瓶颈2024-03-08 1758
-
AMD谈模块化芯片的未来2022-06-16 2895
-
ai芯片和gpu的区别2021-07-27 2869
-
芯片里的CPU、GPU、NPU是什么,它们是如何工作的2020-03-25 17974
-
AMD Infinity Fabric升级后可支持CPU-GPU之间的连接2020-03-09 3539
-
芯片开发商ARM宣布对CPU与GPU的一系列改进,性能大幅提升2018-06-04 4580
-
什么是ASIC芯片?与CPU、GPU、FPGA相比如何?2018-05-04 256083
-
GPU暗战CPU十年 APU主导未来芯片市场?2012-08-29 1871
-
谁才是CPU和GPU融合的领先者?2011-10-14 3411
-
AMD明年推CPU与GPU融合产品 或先用于笔记本2009-12-03 882
-
芯片业主战场从CPU转向GPU2009-11-18 648
-
cpu是amd芯片组的电脑如何安装matlab软件2009-09-22 4560
全部0条评论

快来发表一下你的评论吧 !
