

深度学习:基于语境的文本分类弱监督学习
描述
高成本的人工标签使得弱监督学习备受关注。seed-driven 是弱监督学习中的一种常见模型。该模型要求用户提供少量的seed words,根据seed words对未标记的训练数据生成伪标签,增加训练样本。
但是由于一词多义现象的存在,同一个seed word会出现在不同的类别中,从而增加生成正确伪标签的难度;同时,单词w在语料库中的所有位置都使用一个的词向量,也会降低分类模型的准确性。
而本篇论文主要贡献有:
开发一种无监督的方法,可以根据词向量和seed words,解决语料库中单词的一词多义问题。
设计一种排序机制,消除seed words中一些无效的单词;并将有效的单词扩充进seed words中。
模型整体结构为:
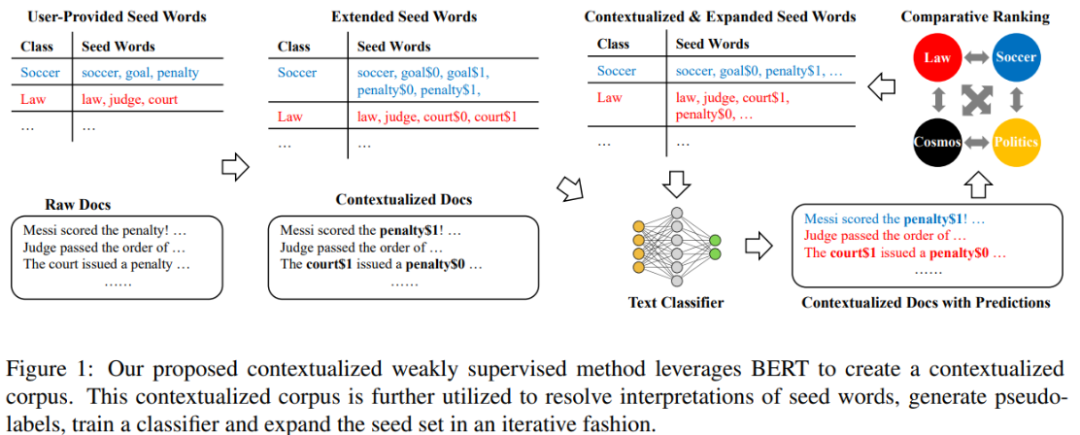
第一步:使用聚类算法解决语料库中单词的一词多义问题
对于每一个单词 w, 假设w出现在语料库的n个不同位置, 分别为 ,使用K-Means算法将分成K类,这里K可理解为单词w的K个不同解释。
用下列公式计算K的值:
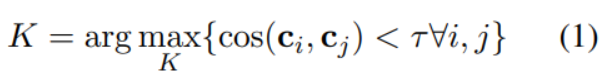
其中代表第i个聚类中心的向量。的计算方法如下:
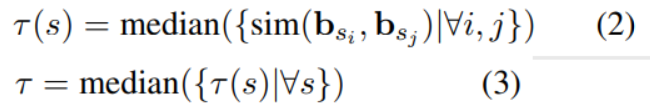
这里s表示一个seed word,且表示s在语料库第i次出现,对应的词向量为。
sim() 表示余弦函数,median( )表示取中位数。
则对于任意,有
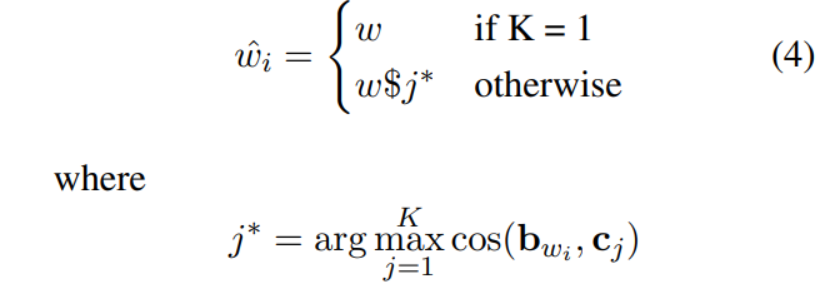
综上,一词多义问题解决算法如下:

使用上面算法,我们就可以将原始语料库转变为基于语境下的语料库:

第二步:对未标记的训练数据生成伪标签令表示文档d的伪标签;表示类别为的seed word 集合;表示单词w出现在文档d的词频
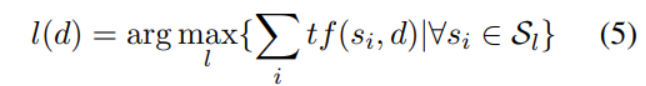
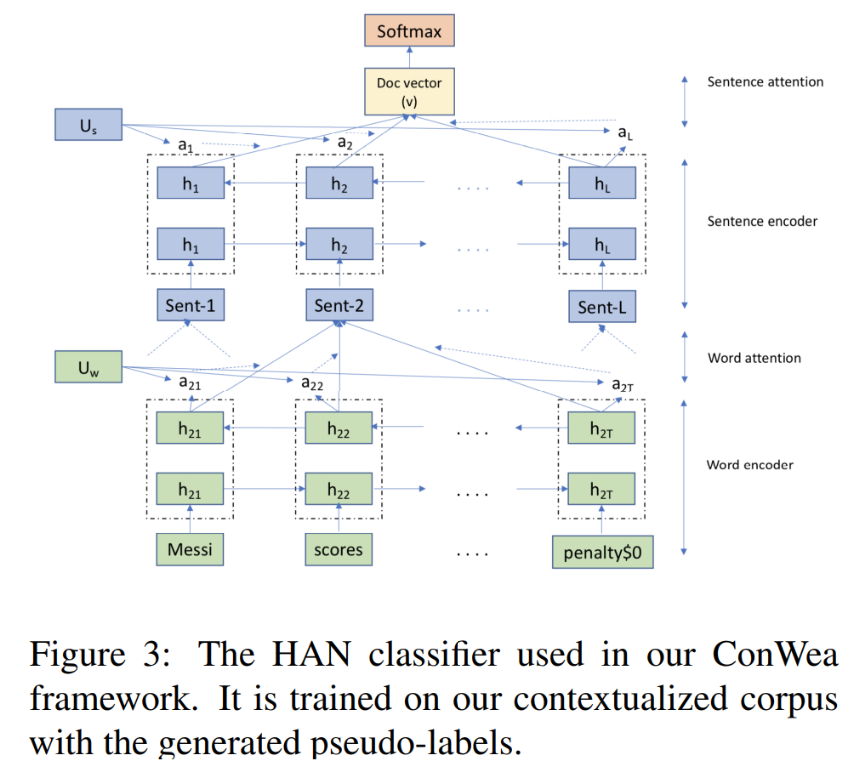
第三步:使用基于语境下的语料库进行文档分类
本篇论文使用Hierarchical Attention Networks (HAN) 进行文本分类。
第四步:设计排序函数,更新seed words我们设计出一个打分函数,用于表示单词w仅高频的出现在类别为的文档。分值越高,表示单词w对类别越重要。我们可以选择分值最高的前几个单词作为新的seed word。也可以剔除一些不重要的seed word。

其中:
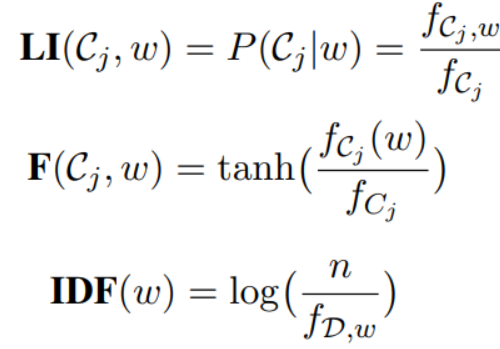
表示类别为的文档的数量。表示类别为且含有单词w的文档的数量。表示在类别为的文档中,单词w的词频。
n为语料库D的文档总数目表示语料库D中含有单词w的文档的数量。
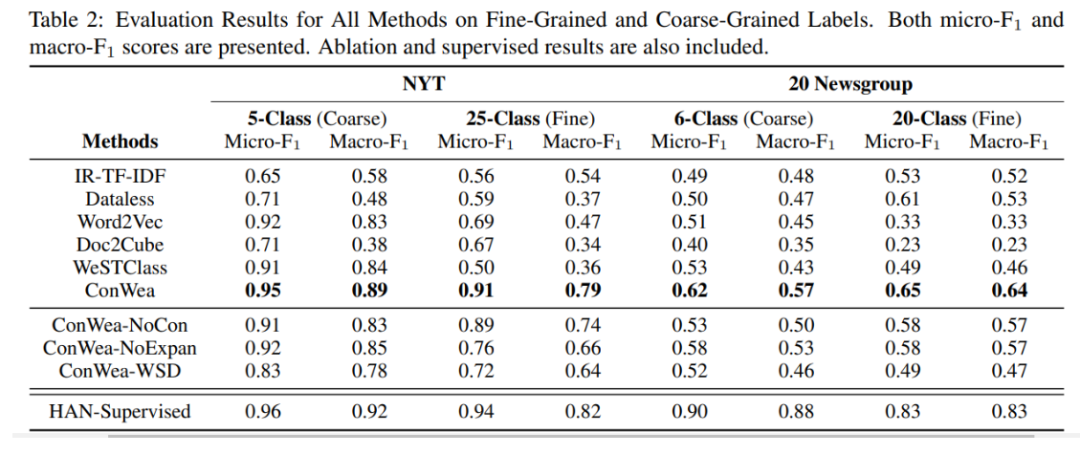
结果
我们的完整模型称为 ConWea,
而 ConWea-NoCon是 ConWea确实缺少第一步的变体。
ConWea-NoExpan是 ConWea确实缺少第四步的变体。
ConWea-WSD是将 ConWea第一步的方法换成Lesk算法。
责任编辑:xj
原文标题:【ACL2020】基于语境的文本分类弱监督学习
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
-
使用MATLAB进行无监督学习2025-05-16 1752
-
深度学习中的无监督学习方法综述2024-07-09 3280
-
弱监督学习解锁医学影像洞察力2022-09-30 2507
-
融合零样本学习和小样本学习的弱监督学习方法综述2022-02-09 3277
-
机器学习中的无监督学习应用在哪些领域2022-01-20 5654
-
如何用卷积神经网络方法去解决机器监督学习下面的分类问题?2021-06-16 3023
-
基于LSTM的表示学习-文本分类模型2021-06-15 1311
-
基于深度神经网络的文本分类分析2021-03-10 2360
-
半监督学习:比监督学习做的更好2020-12-08 2309
-
为什么半监督学习是机器学习的未来?2020-11-27 4799
-
最基础的半监督学习2020-11-02 3527
-
机器学习算法中有监督和无监督学习的区别2020-07-07 6830
-
深非监督学习-Hierarchical clustering 层次聚类python的实现2020-04-28 1707
-
你想要的机器学习课程笔记在这:主要讨论监督学习和无监督学习2018-12-03 1022
全部0条评论

快来发表一下你的评论吧 !
