

基于FPGA的改进型分组交织器的设计与实现
FPGA/ASIC技术
描述
基于FPGA的改进型分组交织器的设计与实现
Turbo码是由法国人Berrou于1993年提出的一种性能优越的信道编码方案[1],其应用已逐步推广到卫星通信、移动通信和计算机通信等领域。交织器作为Turbo码编码器中的重要组成部分,在Turbo码的性能中起着至关重要的作用,因此交织器的设计成了Turbo码设计中的一个重要方面,交织器的好坏将直接关系到整个Turbo码系统的优劣。
本文分析了交织器在Turbo码中的作用,以及分组交织器[2]存在的缺陷,提出一种改进型的分组交织器,即交织深度和宽度可控的分组交织器的设计方法。该交织器可根据数字通信中信道的实际特性,做到交织矩阵深度和宽度可控,能够更好的满足不同帧长度数据传输的要求,从而达到最佳的抗突发连续错误的目的。
交织器设计采用Altera公司生产的Cyclone系列FPGA芯片,利用其内部嵌入式存储资源,用双端口存储器实现。
1 传统分组交织器的作用、原理及缺陷
1.1 交织器的作用
在传统信道编码中,交织器的作用是将信源序列打乱,将它们分散到不同的数据序列中,以消除相邻码元之间的相关性。这样,当信号经历衰落或突发干扰时,邻近码元被噪声淹没的可能性会大大降低,从而增强了抵御长时间突发噪声的能力,同时也有利于接收端的译码接收。
另外,交织器作为Turbo码编码器中的重要组成部分,对提高Turbo码的性能起着至关重要的作用。文献[3]指出,Turbo码作为线性码,其纠错译码性能主要由码字的重量分布决定,而交织器实际上正是决定了Turbo码的重量分布。所以,Turbo码的性能很大程度上由交织器所决定。
1.2 分组交织器的原理
分组交织是一种简单的交织方式,其原理是在发送端将待交织的输入数据均匀分成m个码组,每个码组由n段数据组成,这样便构成一个n×m的交织矩阵,其中,m为交织深度,n为交织约束长度或宽度。待交织数据以公式的顺序进入交织矩阵,再以公式的顺序从交织矩阵中送出,这样就完成了对输入数据的分组交织。
1.3 分组交织器存在的缺陷
分组交织器虽然具有原理简单,易于硬件实现的特点。但其存在的主要缺点是由于交织矩阵的深度和宽度固定,不能够根据信道(特别是变参信道)中突发误码长度、纠错码的约束长度、纠错能力做出调整,这样,信息序列中出现的突发错误就不能够尽量随机分布在数据帧内。交织后,输入至编码器中的消息序列仍有很大的相关性。这就导致了Turbo码译码器在相继译码中不能正确的译码,会产生较高的译码错误。
基于以上原因,希望设计出交织矩阵深度和宽度可控的分组交织器,以适应不同数据帧长度的需要。从而更好的适应通信系统的特性要求,提高系统克服突发差错的能力。
2 改进分组交织器的FPGA设计与实现
2.1 FPGA选取及总体实现
交织器的设计采用Altera公司生产的Cyclone系列FPGA实现。根据系统的总体要求选用了一片EP1C3T100C8芯片,该系列芯片具有成本低、设计灵活、系统便于集成等优点[4],因而在数字通信系统设计中得到了广泛的应用。此外,Cyclone系列芯片内部具有嵌入式RAM存储空间,可以实现较为复杂的逻辑功能,当用作片内存储器时,其存储数据的宽度和深度可由设计人员设定。因而利用存储器可以方便的设计出交织器,从而能够大大减小电路的体积和复杂度。
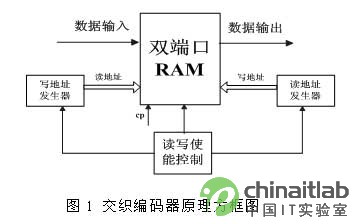
FPGA实现交织器的原理框图如图1所示,从图中可以看出交织器主要由读、写地址序列发生器,双端口RAM以及读写使能控制几部分组成。其中读写使能控制主要用来产生双端口RAM的读写控制信号,并决定读、写地址序列发生器何时启动工作。
FPGA实现交织器的原理框图
2.2 读地址序列产生算法及设计
2.2.1 交织器读地址产生算法
交织器设计的关键部分在于“读/写地址”的产生。设交织器的交织矩阵为n m矩阵,根据分组交织原理,输入数据以0,1,2…,mn-1的顺序地址方式写入存储器,交织后输出为:0,n,2n,…, (m-1)n,1,n+1,2n+1, …,(m-1)n+1,2,…,mn-1.
地址产生算法采用双重循环的方式(算法流程如图2所示),算法流程说明如下:
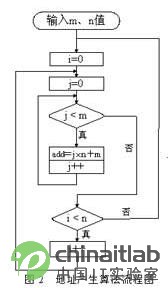
算法流程图
①首先根据信道实际情况及数据帧长,选定合适的交织
将计数变量i,j清零;
②对计数变量j进行判断:如果j<m,则j++;
如果j=m,则跳到第3步;
③对计数变量i进行判断:如果i<n,则i++并将j清零之后跳回第2步;如果i=n,则跳回第1步,开始新一轮循环。
在整个循环过程中,读地址变量add不断输出“乱序”的交织地址add=j n+i,以达到设计的要求。
通过上述分析可以看出,算法中运用了加法、乘法、比较、计数等算术逻辑运算,则地址生成的FPGA设计过程中,需要运用加法器,乘法器,比较器,计数器等器件以实现相应功能。在设计过程中,这些器件采用由QuartusⅡ软件为设计人员提供的参数化宏单元模块LPM(library of parameterized modules),使用它不仅可以简化电路复杂度,而且大大提高了设计速度。
2.2.2 读地址序列产生器设计
读地址是整个交织器设计部分的关键,采用“乱序读出”的方式。电路设计主要由加法、乘法器,计数器和比较器模块构成,其地址序列产生流程在算法分析中已作过详细说明,这里只作简单介绍:计数器Ⅰ相当于变量j,首先在时间脉冲cp的驱动下从初始状态“00000000”开始递增计数,当等于设定交织深度m时,产生一个时钟脉冲信号来驱动计数器Ⅱ,此时计数器Ⅱ的计数加一,同时与另一设定数据n进行比较,当相等时计数器Ⅰ、Ⅱ同时清0,重新开始计数。
读地址序列产生器
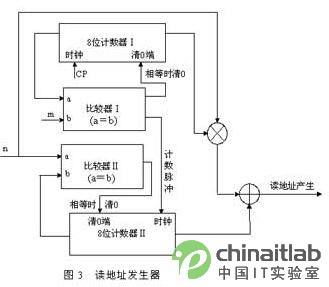
读地址产生结果由数据n与计数器Ⅰ每次的输出数据相乘,再与计数器Ⅱ的计数数据相加而得到。产生的序列依次为:0,n,2n,…,(m-1)n,1,n+1,2n+1,…,(m-1)n+1,2,…,mn-1.
2.3 写地址序列产生器设计
交织器采用“顺序写入”的写地址方式,即产生“0,1,2 …,mn-1”的顺序地址序列。因此写地址序列产生器的实现可由乘法器,比较器和计数器等宏单元模块构成(如图4所示),写地址具体产生说明如下:
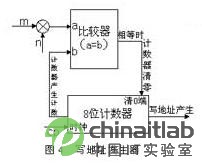
写地址序列产生器
首先8位计数器在时钟脉冲cp的驱动下由初始状态“00000000”开始递增计数,产生的计数数据分成两路:一路送到双端口RAM的写地址端,作为交织器的写地址产生信号;另一路则送到比较器的一个输入端,同乘法器输出的结果进行比较:当计数器累计计数值小于乘法器计算结果时,计数器继续累加计数;而当计数值等于乘法器的计算结果时,比较器产生中断控制信号使得计数器清0,并重新开始计数。
2.4 读写使能控制设计
考虑到双端口RAM对其内部同一单元地址不能同时进行读写操作,因此,整个交织器设计需用读写使能控制电路用来对双端口RAM的地址读写进行控制,并同时决定读写发生器何时开始工作。由于双端口RAM的读、写实现都是从零地址开始的,因而RAM内的每个存储单元的读操作都应在写操作之后,从而保证每个读出数据的有效性。
读写使能控制电路如图5所示,读写控制电路采用类似于分频器原理[4]的工作方式,电路主要由计数器、比较器和D触发器来实现:计数器与n m比较的结果作为D触发器的时钟脉冲信号,当计数器的计数值等于n m时,触发器的输出状态进行一次反转,即相当于构成了一个n m的分频器电路。触发器的输出结果分成两路:一路送到双端口RAM的写地址使能端;另一路经过反相后送给读地址使能端。这样便可以使存储器RAM在“n m”的地址空间范围内交替进行“读/写”数据的操作。
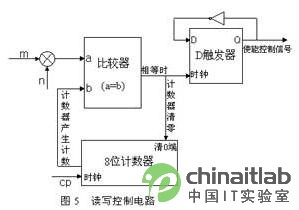
读写使能控制电路
2.5 设计中的遇到的问题及解决办法
交织器的设计中包含的运算有相乘和相加,相乘会造成字长的变化。这便会带来数据位数匹配的问题,下面我们以读地址电路(图4)为例给出解决办法:
进入乘法器的两路数据均为8位,经过乘法运算后,数据位数会增加到16位,同时需要与来自计数器Ⅱ的8位数据进行加法运算。通常情况下多采取舍入或截尾的方法,即将16位数据的高8位字节舍去,这种方法的不足是当m、n的乘积大于256(11111111H)时,数据的高8位不全为0,舍去会带来输出结果的错误,因而可能造成交织器输出码字的错误。因此,可采用“补位”的办法,将输入加法器的8位数据补成16位(在8位数据前补8位0),以增长位宽从而达到数位匹配的目的。
3 QuartusⅡ仿真结果及分析
交织器的仿真波形如图6所示(其中“clk”为驱动时钟,“rden”、“wren”为读、写使能,“data”、“result”为输入、输出双端口RAM的数据序列):

Quartus
从QuartusⅡ波形仿真结果看到当交织矩阵的m,n值为5和3时,双口RAM的输出数据为“0、5、10、1、6…”;当m,n调整为8和 6后,双口RAM的输出为“0、8、16、24…”。可以看出,在任意选取不同的m值和n值后,交织器能够根据分组交织的原理将输入RAM的数据字或比特位流进行交织,输出所需的数据序列,达到了交织矩阵深度和宽度可控的目的。
4 小结
本文介绍了可针对不同交织需要的改进型分组交织器FPGA设计,该交织器的主要特点是可根据信道中突发误码的长度、出现的频率以及纠错码的约束长度、纠错能力设定合适的交织深度和宽度(m,n),需要指出的是,m,n选得越大,信道编码的约束长度越大,从而对付信道中长突发差错的能力也就越强,但m,n选得越大,也就需要越大的存储空间,同时会引入更长的延时,所以应根据数字通信系统的实际情况选择合适的m值和n值。
本文作者创新点:对传统分组交织器进行了改进,实现了分组交织器的交织矩阵深度和宽度可控,能够很好的满足不同数据帧传输的要求,具有更好的抗信道突发错误的能力。
-
改进型05版内存测试仪使用说明2010-09-04 665
-
改进型仪表放大电路的工作原理分析2023-10-28 2439
-
为什么要进行交织处理?什么是分组交织?什么是卷积交织?2008-05-30 20208
-
protel 99 se 鼠标缩放功能改进型2014-03-19 2777
-
什么是改进型VSG二次调频控制器?有何作用?2021-07-06 3018
-
基于FPGA的改进型分组交织器的设计与实现2010-07-28 466
-
一种交织器和解交织器的FPGA电路实现2009-02-08 1997
-
改进型全桥移相ZVS-PWM DC/DC变换器2009-07-11 2160
-
改进型ZVT-BOOST电路2009-07-21 2596
-
改进型CMOS多谐振荡器2009-09-26 784
-
FPGA时分多址的改进型实现方法2011-01-15 491
-
CIC抽取滤波器的改进及其FPGA的实现2011-03-15 956
-
如何使用FPGA实现RS译码中改进型欧几里德算法2021-02-01 1147
-
基于ADMCF341DSP控制器的改进型单次电流传感方法及其实现2021-05-18 896
-
一种实现宽电压增益的改进型LLC-AHB变换器2024-12-16 806
全部0条评论

快来发表一下你的评论吧 !
