

研发全新多模态感知AI框架 AI能同时模拟人眼和手预测物体运动
电子说
描述
据外媒VentureBeat报道,来自三星、麦吉尔大学和约克大学的研究人员,近日研发出一个全新的生成式多模态感知AI框架,能够根据物体初始状态的视觉和触觉数据,来预测出物体的运动趋势。
据悉,这是第一个利用视觉和触觉感知来学习多模态动力学模型的研究。
运动预测是自动化领域的一大关键技术,通过预判物体和环境的交互方式,自动化系统得以作出更加智能的决策。该团队的这项研究,似乎又将这一技术的应用向前推进了一步。
这篇论文名为《基于多模态的生成模型指导的直观物理研究(Learning Intuitive Physics with Multimodal Generative Models)》,已发表于arXiv平台。
论文链接:
https://arxiv.org/pdf/2101.04454.pdf
一、运动预测有挑战:摩擦力、压力难确定
假如你要接住一个掉落的物体,你会迅速判断它的运动走向,然后准确接住它。
但对于一个机器人来说,要准确预测出物体还未发生的运动趋势,可不是一件容易的事。
近期,不少运动预测方面的AI研究,都指出了触觉和视觉之间的协同作用。
其中,触觉数据可以反映物体和环境间的作用力、由此产生的物体运动和环境接触等关键信息,提供一种展现物体与环境交互过程的整体视角;视觉数据则可以直观反映了立体形状、位置等物体属性。
在本文研究人员看来,视觉、触觉信号的组合,或有助于推测出物体运动后的最终稳定状态。
研究人员在论文写道:“先前的研究表明,由于摩擦力、几何特性、压力分布存在不确定性,预测运动对象的轨迹具有挑战性。”
比如推一个瓶子,如何准确预测这个动作的结果,接下来这个瓶子是会向前移动,还是会翻倒?
▲《基于多模态的生成模型指导的直观物理研究(Learning Intuitive Physics with Multimodal Generative Models)》论文插图
为了减少这种不确定性,研究团队设计并实现了一个由软硬件组成的高质量AI感知系统,经训练后,该系统能捕获到运动轨迹中最关键、最稳定的元素,从而准确测量和预测物体落在表面上的最终静止状态。
二、开发新型视觉触觉传感器,打造多模态感知系统
动态预测常被表述为一个高分辨率的时间问题,但在此项研究中,研究人员关注的是物体运动后的最终结果,而不是预测细粒度的物体运动轨迹。
研究人员认为,关注未来关键时间的结果,有助于大大提高模型预测的准确度和可靠性。
该研究团队开发了一款名为“透视肌肤(STS,See-Through-Your-Skin)”的新型视觉-触觉多模态传感器,可以同时捕捉物体的视觉和触觉特征数据,并重建在1640×1232的高分辨率图像中。
由于光学触觉传感器通常使用不透明和反光的涂料涂层,研究人员开发了一种具有可控透明度的薄膜,使得传感器能同时采集关于物理交互的触觉信息和传感器外部世界的视觉信息。
具体而言,研究人员通过改变STS传感器的内部照明条件,来控制传感器的触觉和视觉测量的占空比,从而设置了反光涂料层的透明度。
如上图左上角所示,利用内部照明可将传感器表面变成透明,从而使得传感器内置摄像头能直接采集传感器外部世界的图像;上图的左下角显示,传感器也可以保持内外一致的亮度,通过感知膜形变来采集物理交互触觉信息。
借助STS传感器和PyBullet模拟器,研究人员在动态场景中快速生成大量物体交互的视觉触觉数据集,用于验证其感知系统的性能。
受多模态变分自编码器(MVAE)启发,研究团队设计了一个生成式多模态感知系统,在一个统一的MVAE框架内集成了视觉、触觉和3D Pose反馈。
MVAE可以解读STS传感器采集的视觉、触觉数据,将所有模态的物体关键信息映射到一个共享的嵌入空间,用于推断物体在运动后最终的稳定状态。
实验结果表明,MVAE架构可以被训练用于预测多模态运动轨迹中最稳定和信息最丰富的元素。
三、不惧单一模态信息缺失,准确预测物体未来状态
该研究团队生成的视觉触觉数据库主要包含三种动态模拟场景,分别是物体在平面上自由落体、物体在斜面上下滑、物体在静止状态下收到外力扰动。
下图显示了模拟三种动态场景的示例集,顶部一行显示3D Pose视图,中间一行、底部一行分别显示STS传感器采集的视觉和触觉结果。
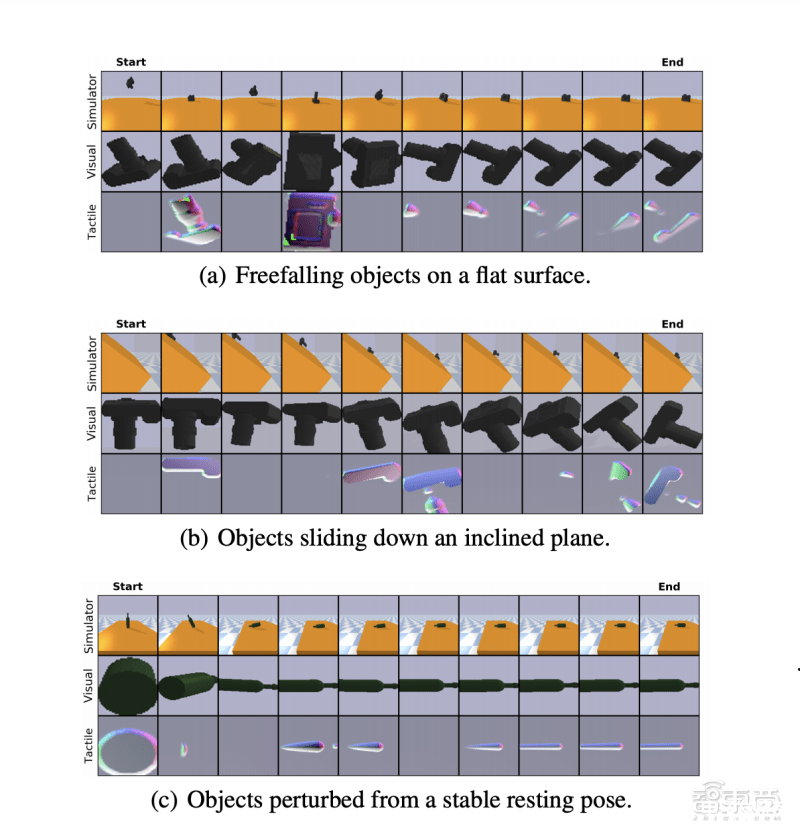
研究人员在三种模拟动态场景和使用STS传感器的真实实验场景中,分别验证了其动力学模型的预测能力。
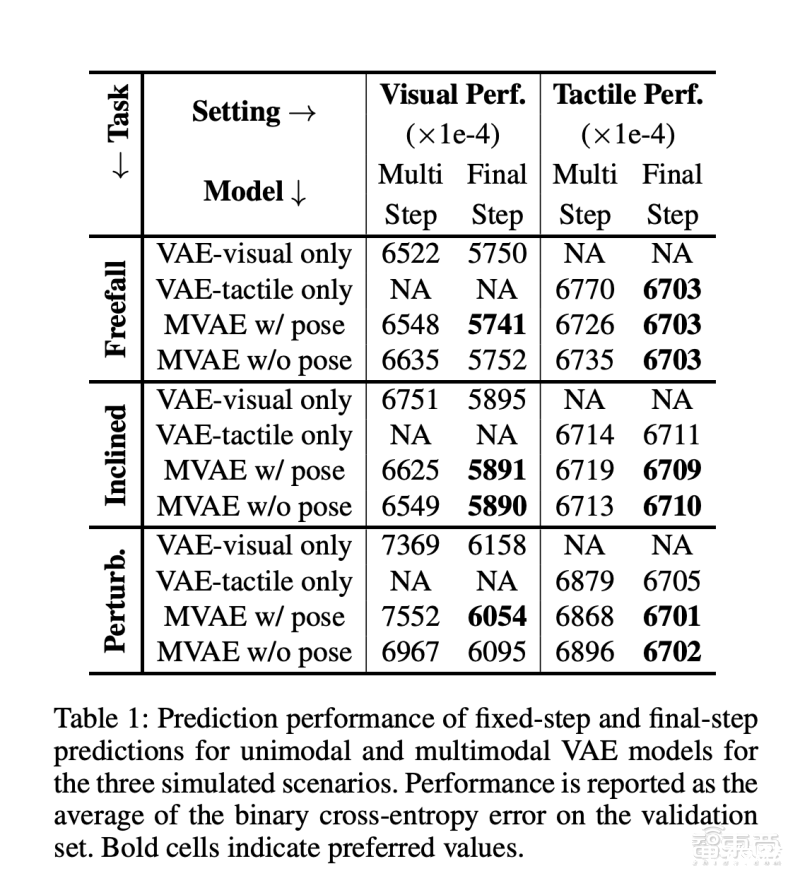
如下方图表显示,在三种模拟场景中的固定步和最终步预测中,相比仅依赖视觉(VAE-visual only)或仅依赖触觉(VAE-tactile only)的单模态感知模型,多模态感知模型(MVAE)在验证集中的二进制交叉熵误差(BCE)均值更小,即预测结果的准确性更高。
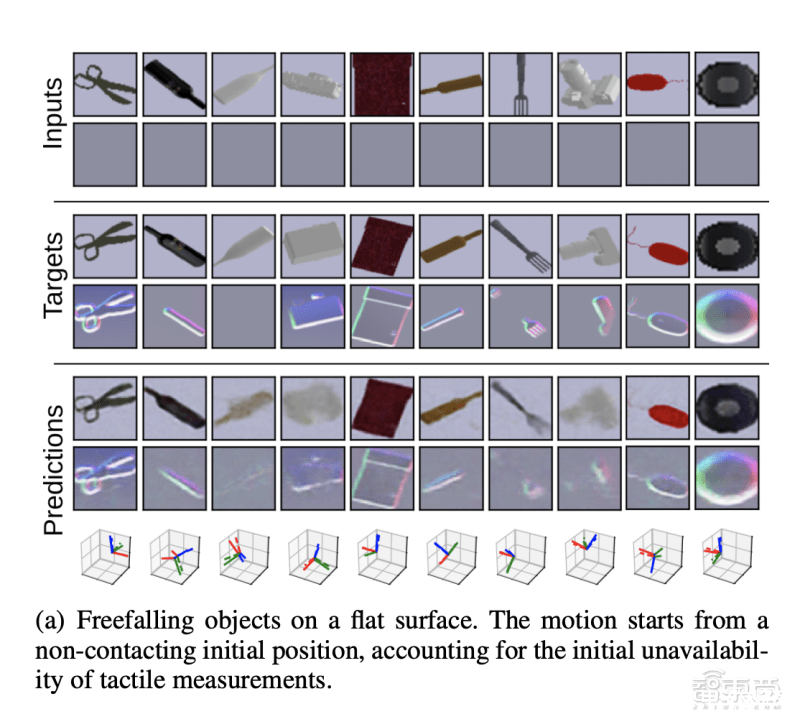
研究人员还用基于高时间分辨率的模型进行对比实验,发现这一模型在预测物体最终静止状态时,准确性要高于动态模型。这是由于不确定性和错误会随着时间前向传播,导致模糊和不精确的预测。
结果表明,在对中间状态不感兴趣的动态场景中,该AI框架能以更高的准确度来预测最终结果,而无需明确推理中间步骤。
此外,由于该研究方法破译了触觉、视觉、物体姿态之间的映射关系,因此即便某一模态信息缺失,比如缺乏触觉信息时,该框架仍然可以从视觉信息推测出视觉信息,从而预测物体运动后的最终落点。
结语:制造业自动化将是运动预测的一大应用场景
该研究团队的这项新成果能够基于触觉、视觉的双模态数据对物体的运动轨迹进行预判,并推测出物体的最终静止状态。
相较于以往的运动预测技术,该研究团队实现了触觉和视觉数据的双向推测,为制造业的自动化场景提供了更多的可能性。
比如,拣货机器人能够更准确地判断货物的运动状态,从而提高拾取精度;货架机器人能够提前预判货物的运动轨迹,从而防止货物跌落破损,减少损失。
不过,这项成果能够预测的运动状态还相对有限,我们期待研究团队对复杂的运动模式、多样的物体形态进行更多的模拟和技术攻关。
责任编辑:PSY
-
【书籍评测活动NO.64】AI芯片,从过去走向未来:《AI芯片:科技探索与AGI愿景》2025-07-28 56787
-
【「AI芯片:科技探索与AGI愿景」阅读体验】+AI的科学应用2025-09-17 3230
-
【「AI芯片:科技探索与AGI愿景」阅读体验】+AI芯片到AGI芯片2025-09-18 6073
-
阿里云智能视频 AI 重装来袭2018-01-23 4096
-
「AI大学·未来课栈@成都栈」报名开启,AI 带你大开眼界!2018-06-09 3685
-
Firefly支持AI引擎Tengine,性能提升,轻松搭建AI计算框架2018-08-13 4619
-
『深思考』打造人工智能机器大脑,让AI更懂你!2018-09-13 5157
-
AI全新应用场景 技术趋势多模态学习2020-07-18 2486
-
洲明科技发布AI+多显示终端技术,推动LED行业数字化、智能化升级2024-02-03 1960
-
阿里巴巴推出自主多模态AI代理MobileAgent2024-02-04 1957
-
MWC2024:高通推出全新AI Hub及前沿多模态大模型2024-02-26 2083
-
李未可科技正式推出WAKE-AI多模态AI大模型2024-04-18 1222
-
谷歌发布多模态AI新品,加剧AI巨头竞争2024-05-16 1038
-
智谱AI发布全新多模态开源模型GLM-4-9B2024-06-07 1771
-
XMOS为普及AI应用推出基于软件定义SoC的多模态AI传感器融合接口2025-05-12 683
全部0条评论

快来发表一下你的评论吧 !
