

光纤接口转为以太网接口数据传输系统的实现方法
描述
作者:姜 浩,李和平 ,马翠梅,文章来源: 射频百花潭微信公众号
为满足合成孔径雷达实时成像、数据回放等高速可靠数据传输需求,解决传统数据传输系统由于接口要求高、体积与功耗大以及网络配置不灵活等原因不适合用于外场试验的问题,基于 ZYNQ 芯片设计一种光纤接口到以太网接口的数据传输系统。主要介绍数据传输流程的实现方法,并提出一种三级乒乓和指令并行的优化策略保证数据正确,提高传输速度;通过移植嵌入式 Linux 系统实现灵活修改网络配置。与传统方案相比,该系统在体积、功耗和灵活性上具有明显优势。经实验验证,数据传输速度可达 770 Mb/s。
飞行试验获取合成孔径雷达( SAR )数据需要消耗大量资源,一般使用计算机实现与雷达系统的高速数据传输。雷达系统普遍使用光纤接口,而绝大部分计算机没有光纤接口,需要一种将光纤接口转为计算机通用接口的高速数据传输系统 。
千兆以太网速率较高、抗干扰能力强且使用方便,更适用于小体积、低功耗的高速数据传输系统。实现千兆以太网数据传输的方案有高级精简指令集处理器( ARM ) + 现场可编程门阵列( FPGA )架构方案 、数字信号处理( DSP ) +FPGA 架构方案和 FPGA 脱机方案。前 2 种方案设计臃肿、集成度不高,难以控制体积和功耗;FPGA 脱机方案开发周期长、程序修改困难且难以修改网络配置,使用不灵活。本文基于 Xilinx ZYNQ7000 系列芯片,设计一种将光纤接口高速串行数据转发为千兆以太网接口传输控制协议( TCP )数据的高速数据传输系统。
1 系统设计
1.1 系统简介
数据传输系统使用 ZYNQ 单主控芯片实现, 有 2路光纤与 1 路千兆以太网接口,系统架构如图 1 所示。
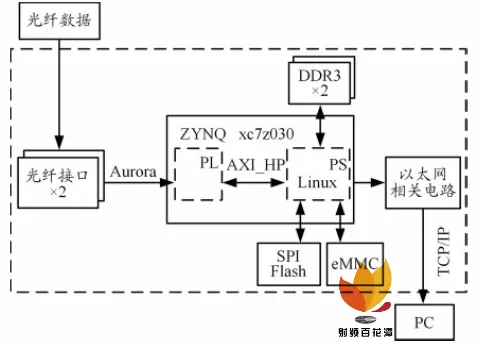
图 1 光纤 - 以太网系统架构图
Xilinx ZYNQ 7000 系列( ZYNQ xc7z030 )是集成ARM+FPGA 的异构芯片, 其中处理系统 ( PS ) 代表ARM 部分,可编程逻辑( PL )代表 FPGA 部分。PL 部分使用 Aurora IP 实现光纤高速串行数据接收, 通过 PS与 PL 间 的 AXI_HP 接 口 将 数 据 写 入 PS 挂 载 的DDR3 。PS 部分移植 Linux 系统,存储于串行外围接口( SPI ) Flash , 在 Linux 系统下使用 C 语言编程实现轮询数据可读标识、读取 DDR3 数据并通过 TCP/IP 实现数据发送,兴趣数据可存储于 eMMC 芯片中,通过安全文件传送协议( SFTP )将文件读出。
1.2 数据传输流程设计
1.2.1 光纤接口
Aurora 协议是 Xilinx 公司提供的一种高效率、简单易用的高性能点对点串行链路协议。光纤接口使用Aurora 协议,使用吉比特收发器( GTX )通道,允许设备间组合多个 GTX 通道进行通信, 以实现 480 Mb/s~84.48 Gb/s 的数据传输。Aurora IP 核将高速串行收发器 Rocket I/O 的控制信号进行封装, 只保留很少的用户接口信号。Aurora IP 用户接口如图 2 所示。
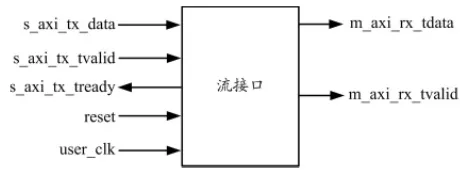
图 2 Aurora IP 用户接口
图 2 中, tx_tready 在输出信号被接收并且数据准备发送时断言, tx_tvalid 在输出流信号或源信号有效时断言,这样将数据从应用程序移动到 tx_data 总线并执行流控制,实现发送。当 tx_tvalid 取消断言时,字间会创建并保留间隙。数据到达接收侧时, rx_tvalid 被断言, 从用户接口 rx_tdata 总线将数据移动到应用程序并执行流控制,实现数据接收。数据必须立即读取,否则将丢失。 接口使用先进先出( FIFO )方式保存数据,将 rx_tvalid 用作 FIFO 写使能。
系统使用 2 路 Aurora IP 用户接口, 数据位宽为32 bit ,每路速率为 2.5 Gb/s ,参考时钟为 125 MHz ,用户时钟为 PS 提供的 150 MHz 时钟。Aurora IP 核在物理层进行 8B/10B 编码, 2 路 Aurora 协议可提供 4 Gb/s的数据速率,可保证数据稳定正确传输并超过系统后级千兆以太网的速率。
1.2.2 AXI_HP 接口
2 路使用 Aurora 协议的光纤接口速率( 4 Gb/s )与千兆以太网速率(不到 1 Gb/s )之间存在差异,需要将数据暂存后等待以太网发送完毕。ZYNQ 系列 PL 逻辑资源较少, xc7z030ffg676 的 Block RAM 仅有 9.3 Mb 。系统采用 DDR3 实现高速数据缓存。DDR3 控制器位于 PS 部分, 光纤接口输入的数据需通过 AXI 互联矩阵写入 DDR3 。位于 PS 与 PL 间的 ARM AMBA 3.0 互联矩阵实现主、从设备间的地址、数据和响应事件的点对点通信,有加速一致性( AXI_ACP )、高性能( AX-I_HP )和通用( AXI_GP ) 3 种接口。AXI_HP 接口基于AXI 3.0 协议, 为 PL 部分提供到 DDR 和片上存储器( OCM ) 内存的高带宽数据通路, 在使用 64 bit 位宽、150 MHz 时钟时可提供 1200 MB/s 带宽, 接近 DDR3读写带宽并远高于后级以太网 1 Gb/s 带宽。通过使用AXI Interconnect IP 将 AXI_HP 接口转为 AXI4 协议。AXI4 采用 READY/VALID 握手通信机制进行数据传输, READY 和 VALID为高时,数据在每个时钟的上升沿进行有效传输。
AXI4 总线含有读地址通道、写地址通道、读数据通道、写数据通道、写应答通道和系统信号(总线时钟ACLK 、 总 线 复 位 ARESETN ), 其 中 多 个 通 道 有READY/VALID 握手机制,控制信号多,使用复杂。将AXI4 协议进行封装,只引出少数信号给用户,这样可以大幅缩短后期开发和维护周期。PL 为 AXI_HP 的主设备,模块命名为 AXI master 。AXI master 由有限状态机实现,状态转移图如图 3 所示。
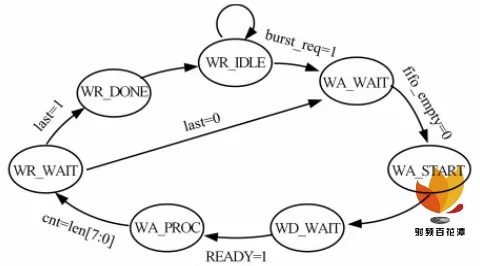
图 3 AXI master 状态转移图
AXI master 初始化后进入 WR_IDLE 状态, 复位所有控制信号和数据信号,在接收到数据传输请求信号 burst_req 后进入 WA_WAIT 状态,更新外部输入的数据、数据长度 len 和起始地址。如果 FIFO 不为空,进入 WA_START 状态,在此状态下与 AXI_HP 接口进行握手并给 last 信号赋值,由于最大突发长度为 256,在传输结束时需要根据 last 信号判断是否需要进行再一次传输,若数据长度 len 大于 256 , last 信号置 0 ,否则置 1 。在 WA_PROC 状态输出 AXI 可写信号 burst_data_req ,对计数器 cnt 进行累加。WR_DONE 状态输出传输完成信号 burst_finish 。
使用 AXI master 进行数据传输时,将 burst_req 置1 请求 AXI master 传输, 写入数据长度 len 和起始地址 addr ,判断 AXI master 输出 AXI 可写信号 burst_da-ta_req 为高时将光纤接口输入的数据拼接为 64 bit 写入数据总线,判断 AXI master 输出信号 burst_finish 为高后可进行下一次写请求。经封装后的 AXI4 协议对用户的接口只有写请求、数据可写、写完成、数据总线、 地址总 线和数据长 度, 极大简化 了 AXI4 的READY/VALID 握手机制。
1.2.3 内存映射
为实现网络参数灵活配置, 在 PS 部分移植嵌入式 Linux 系统进行数据读取和以太网数据发送。Linux中 /dev/mem 是处理器地址空间的全映射,可以通过使用 C 标准库提供给用户的内存映射方法 mmap 访问内存物理地址。内存映射是指 Linux 通过将一个虚拟内存区域与一个对象映射以读写对象内容。mmap 将内存物理地址映射到进程的地址空间,实现物理地址和虚拟地址间一一对应的关系,进程可以使用指针读写内存物理地址,获取 PL 写入 DDR3 的数据。在 Linux读取完一段数据后, 需要清除 PL 写入的数据就绪标识。默认情况下,通过内存映射写入 DDR3 的数据会被写入内核 Cache 中,不能及时写入对象的物理输入 / 输出( I/O ),这样会导致 Linux 与 PL 间数据传输错误。为保证数据安全,在打开 /dev/mem 时添加 O_SYNC参数, 强制刷新内核 Cache 数据到对象 I/O 。Linux 成功读取数据后并通过 TCP/IP 协议将数据发送到 PC上位机。
1.3 数据传输流程优化
1.3.1 控制策略优化
光纤数据速率高于以太网数据速率,为了避免缓冲区写溢出,保证数据正确,一般需要等待接收数据完毕后再发送下一包指令,但是这样串行的指令流程会造成一个周期内各个模块都有较长的空闲时间。 串行策略流程图如图 4 所示。
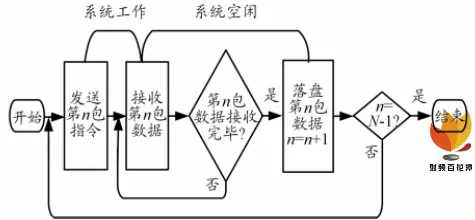
图 4 串行策略流程图
为提高速度,在 PL 写入 DDR3 、 Linux 读取 DDR3通过 TCP 发送和上位机接收数据写入磁盘三部分采用乒乓操作。DDR3 被分为高、低地址两部分,光纤数据被乒乓写入 2 块空间。Linux 将 2 块空间数据乒乓发送,读到低地址标识后读取低地址数据,同时发送高地址数据。上位机先发送 2 次传输指令,使发送传输指令与判断接收完成这 2 个操作错位以实现并行处理的优化方案。在开始传输后,上位机预先发送传输一包数据的指令给记录器, 再按照发一包指令、收一包数据的流水线处理,并且建立 2 条流水线以实现数据接收和数据落盘的乒乓操作,到最后一包时不发送指令,只接收数据。此方案在上位机接收数据时数据传输系统可以准备好下一包的数据等待上位机接收,在处理连续数据时可大幅提升传输速度。优化策略流程图如图 5 所示。
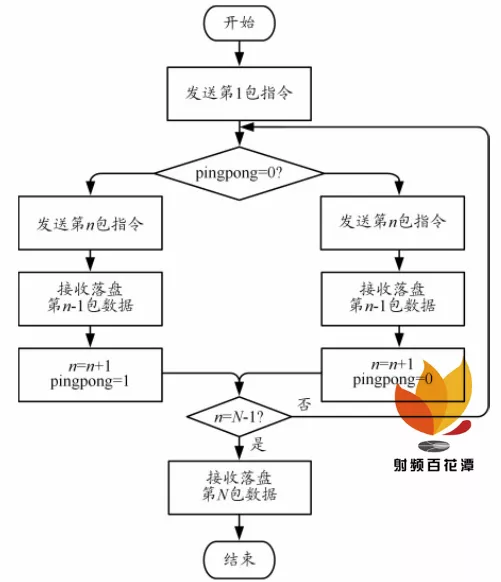
图 5 优化策略流程图
1.3.2 共享内存映射
使用 O_SYNC 进行内存映射时会严重浪费高速内核 Cache 的性能, 读写 mmap 映射的内存物理地址非常缓慢。本文在嵌入式 Linux 下分别测试用户空间、带 O_SYNC 参数 mmap 和不带 O_SYNC 参数 mmap 的内存拷贝速度,结果如表 1 所示。

表 1 内存拷贝速度对比
嵌入式 Linux 在检测到 PL 写入 DDR3 的数据可读标识后使用读描述符进行内存映射,将数据拷贝至TCP 发送缓冲区。拷贝完成后使用写描述符进行内存映射,清除标识,通知 PL 准备下一包数据。共享内存映射比单内存映射提升 36.5% 的拷贝速度。
2 系统实现
2.1 嵌入式 Linux 移植
PS 需要从非易失性存储器中启动嵌入式 Linux系统和应用程序 ( APP )。ZYNQ 系列有 JTAG 、 SD 卡、QSPI Flash 和 NAND Flash 4 种启动方式。因为 SD 卡接插件难以满足可靠性要求, 且 ZYNQ 不支持 eMMC作为主启动设备,所以本系统采用 QSPI Flash 启动挂载 eMMC 作为外部存储的方案。
Xilinx 提供了 Linux 移植工具 petalinux ,可以很方便实现 Linux 的配置、裁剪。移植过程如下:
① 生成 bit 流文件。使用硬件描述语言完成 PL 部分逻辑功能, 并根据硬件平台管脚使用情况对 ZYNQIP 核进行配置,编译整个工程生成 bit 流文件。
② 导入 bit 流文件。在 Linux 虚拟机中依照 ZYNQLinux 模板生成工程,将 bit 流文件作为硬件描述信息导入工程, Linux 通过 bit 流文件实现部分自动设备树文件配置。
③Linux 裁剪与定制。使用 petalinux 完成内核定制、设备树文件配置。本系统使用 SPI Flash 加载系统,使用 U-boot 作为第二阶段引导文件( SSBL ),将 boot 、U-boot 和 kernel 的存储位置设置为 flash ;启用安全数字输入输出 ( SDIO ) 控制器和以太网控制器以使用eMMC 和以太网;在设备树文件中增加 eMMC 、以太网等硬件的物理地址;修改设备树文件,将 DDR3 的高256 MB 地址空间设置为保留以避免 Linux 系统破坏缓冲区数据;加入自启动脚本文件实现 Linux 系统启动后自动运行应用程序。
④ 打包 bin 文件。使用 petalinux 将 PL 部分配置文件 bit 流文件、 kernel 文件、第一阶段引导文件( FS-BL)和U-boot 打包生成 BOOT.bin 文件。
⑤ 固化 Flash 。将生成的 BOOT.bin 文件和 petal-inux 工具生成的 fsbl.elf 文件烧写进 Flash 中, 实现上电自启动嵌入式 Linux 操作系统。
嵌入式 Linux 系统启动时通过运行 BootROM 代码从外部存储器加载 FSBL 加载到内存,根据 FSBL 中bit 文 件 对 PS 、 PL 进 行 配 置 后 加 载 SSBL 到 内 存 ,petalinux 使用 U-boot 作为 SSBL 。U-boot 完成硬件配置初始化、内存空间映射后引导 Linux 内核到内存,通过设备树文件将硬件设备信息传递给内核后将控制权移交 Linux 内核, Linux 初始化硬件设备、 加载文件系统后完成启动。
2.2 PC 上位机
PC 上位机使用网线连接数据传输系统,异步 232串口连接信号源。上位机实现用户和界面交互,可设置串口号、传输数据包大小和文件大小。系统连接后,PC 上位机发送查询段地址指令建立 TCP 客户端连接数据传输系统,同时信号源会返回数据列表,然后选择兴趣数据段和文件存储路径后发送传输指令,最后接收数据传输系统的 TCP 数据并记录到本地磁盘。
3 系统测试
数据传输系统使用 5 V 电压供电。本文通过在嵌入式 Linux 下移植 iperf3 带宽测试软件进行测试,最终测得此以太网链路速率为 850 Mb/s 。测试使用信号源为雷达原始数据记录器,该记录器理论传输速度为3200 Mb/s ,高于千兆以太网的最大速率,不会影响测试结果。数据传输系统通过 2 路光纤线缆连接记录器,六类网线连接 PC 上位机。在 PC 上位机进行数据传输测试,测试电路实物图如图 6 所示,右侧为数据传输系统。
图 6 测试电路实物图
本文监测 Windows 网卡资源使用情况,发现数据传输过程中速率平稳,证明使用的三级乒乓和预发送指令错位判断策略可以有效减少流程中各模块的空闲时间。 经过多次测试,连续数据的传输速度保持在770 Mb/s 以上, 达到该链路物理带宽的 90.6% , 除去TCP 协议开销有效数据传输速度超过 86 MB/s 。测试传输 500 GB 数据,经软件校验数据无丢包无错误。
本设计与传统数据传输方式性能对比如表 2 所示。与 PCIe 、 USB3.0 相比, ZYNQ 在功耗、传输距离和灵活度上具有明显优势, 更适用于外场试验环境,同时传输速率较高,接近磁盘写入速度,满足应用要求。
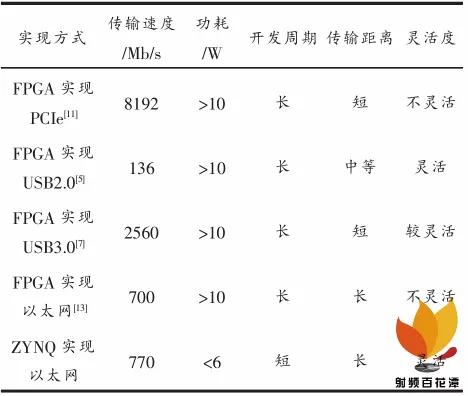
表 2 系统性能对比
4 结束语
本文设计了一种光纤接口转为以太网接口数据传输系统的实现方法, 并提出了一种三级乒乓和预发送指令错位判断接收的策略,有效保证了数据正确传输,提高了传输速率,连续数据传输速度超过 770 Mb/s 。实现的系统 PCB 尺寸仅为 91 mm×63 mm , 使用 5 V 电压供电,工作电流为 1.1 A ,解决了传统传输系统体积与功耗大、不适用于外场试验的问题。通过在异构芯片 ZYNQ 的 PS 部分挂载嵌入式 Linux 操作系统,实现在不同网络环境下灵活配置系统的网段、 IP 和传输协议,扩展了使用场景,降低了后期维护难度。(参考文献略)
审核编辑:何安
-
MSP430实现以太网高速数据传输2013-11-07 3302
-
FPGA以太网数据传输2016-09-25 5725
-
以太网接口的设计及其数据传输的实现过程介绍2019-06-05 3977
-
光纤通道应用的高数据传输接口设计问题怎么解决?2019-08-22 2295
-
一种光纤接口转为以太网接口数据传输系统的实现方法2021-01-26 2807
-
基于ZigBee网与以太网间数据传输系统该怎样去设计?2021-05-19 1778
-
基于千兆以太网的高速数据传输系统设计2012-03-09 1103
-
基于W5300的以太网数据传输系统的设计2012-05-28 2184
-
基于FPGA和W5300的以太网数据传输系统的设计与实现2012-05-29 2890
-
盘点几种以太网接口的设计与实现2017-10-16 1956
-
以太网数据传输系统的设计与应用介绍2017-11-16 1297
-
基于FPGA的千兆以太网CMOS图像数据传输系统设计2018-04-03 1424
-
基于ZYNQ的光纤-以太网高速传输系统设计2021-02-03 1904
-
基于W5300的以太网数据传输系统的设计与实现2023-10-24 655
-
以太网接口的数据传输原理详解2024-05-29 4675
全部0条评论

快来发表一下你的评论吧 !
