

DRAM的架构/标准/特点/未来展望
存储技术
描述
这些年来,记忆体领域出现了各种动态随机存取记忆体(DRAM)标准,这些标准也都各自进一步发展出不同世代的版本。本文将回顾不同DRAM架构的特色,点出这些架构的共同趋势与瓶颈,并会提出IMEC为了将DRAM性能推至极限而采取的相关发展途径。
动态随机存取记忆体(dynamic random access memory;DRAM)主要被用来当作电脑的主要记忆体,中央处理器(CPU)便是从该记忆体读取指令。这些年来也出现了不同的DRAM标准,以满足不同需求与应用。为了回应对频宽越来越高的要求,这些标准都各自进一步发展出不同世代的版本。
IMEC系统记忆体架构师Timon Evenblij与计画主持人Gouri Sankar Kar将于本文回顾不同DRAM架构的特色,并点出这些架构共同面对的趋势与瓶颈。他们也会提出IMEC采取的相关发展途径,以将DRAM性能推升至最终极限。
DRAM的基本概念
位元格(bit cell)
在开始探讨不同的DRAM架构之前,我们先来了解DRAM的基本概念吧!以下说明以卡内基.梅隆大学Onur Mutlu教授的课程为基础。
所有的记忆体都以位元格(bit cell)构成,它是恰好储存1位元的半导体架构,因而得其名。对DRAM来说,其位元格包含了一个电容(capacitor)和一个晶体管(transistor);电容被用来储存电荷,而晶体管则用以存取电容,不论是去读取已储存的电荷量,或是去储存新的电荷。
字元线(wordline)一直与晶体管的闸极相连,以控制往电容的通道;位元线则与晶体管的源极相连,以读取位元格内储存的电荷,或是在写入新的数值时提供位元格所需的电压。这个基本架构很简单且体积小,所以制造商可以在单一芯片上非常大量制造DRAM的位元格。
但其缺点是,单一晶体管不容易在其狭小的电容中保存电荷,电流会泄漏至电容或从电容中流出,导致晶体管渐渐失去定义完善的电荷状态。但是这个问题可以透过定期更新(periodically refresh)DRAM记忆体来避免,也就是读取DRAM记忆体的内容后再重新写入。
有在专心阅读的读者可能已经发现问题了,当电荷自电容中读取出来时,电荷就消失了。但是在读取DRAM位元格的数值后,该数值应该要再重新写入,这也是为何DRAM取名含有「动态」一词。
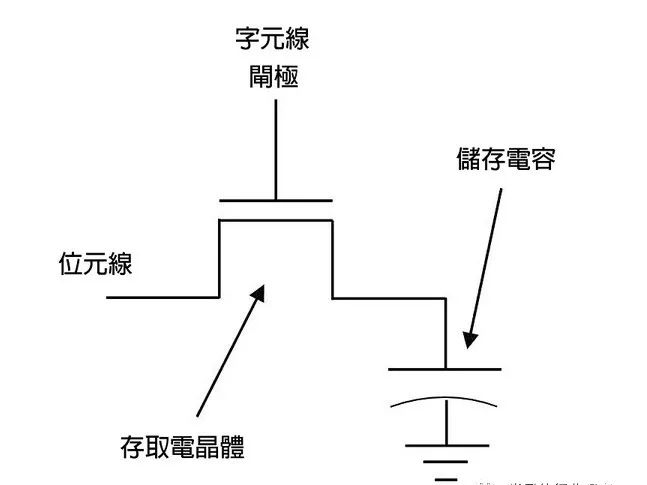
图一: DRAM位元格的示意图
进入位元格阵列
多个位元格可以整合成如矩阵般的大型架构。多条字元线和位元线相互交叉,而每个交叉点都有一个位元格在处理资料。而对某字元线施加电压就能选出所有相应的位元格,这些位元格则会将电流传至各自的位元线。这些电流将微幅改变每条位元线的电压,这个小改变会由感测放大器(sense amplifier)侦测出来。
感测放大器这种结构会将小幅增加的电压放大成高电压(代表逻辑1),并把微幅降低的电压放大成零电压(代表逻辑0)。它也会将各个逻辑数值储存至一个多闩(latches)结构,也就是所谓的列缓冲区(row buffer)。列缓冲区的功能就像是快取记忆体,因为位元格内的数值在读取时会消失,所以在读取某条字元线上的数个位元格时,列缓冲区就会保存读取而来的数值。
感测这个步骤本身就是缓慢的过程,而电容越小、位元线越长时,感测时间就会延长。这段感测时间也决定了DRAM的存取时间,而在过去几十年间,DRAM的感测时间一直维持不变。每一代DRAM的可用频宽增长,皆是透过在DRAM芯片上运用更多平行处理能力来实现,而不是由缩短存取时间达成。
但在深入探讨这个议题前,我们先来看看如何运用这些位元格来建构记忆体系统。这里谈到的架构通常用于采用记忆体模组(memory module)的桌机系统。至于其他DRAM架构,它们并未采用模组的概念,但大多都能以相同的术语来描述其运作模式。
DRAM架构
在处理器上,有部份的逻辑电路是专门设计给记忆体控制器(memory controller)来使用,这些电路负责管理所有从CPU到主要记忆体的通道。
处理器可能有多个记忆体控制器,而记忆体控制器具备一个或多个记忆体通道(memory channel),每个通道包含一个指令或位址汇流排,以及一个资料汇流排(预设状态下宽度为64位元)。
在该通道上,我们可以连接一个或多个记忆体模组,而每个记忆体模组包含一个或两个秩(rank)。一个秩包含几个DRAM芯片,这些芯片整合在一起就能在每个周期提供足够的位元来填充资料汇流排。
在一般情况下,也就是资料汇流排为64位元宽且每芯片提供8位元的储存空间(所谓的x8芯片),一个秩包含8个芯片。如果模组配有超过一个秩,这些秩会多工传输至同一个汇流排,所以不同秩不能同时向该汇流排传输资料。
每秩上的各芯片以相同速度同步运行,也就是说它们会一直执行完全相同的指令,且不能分开定址。这对接下来要说明的概念来说很重要:每个芯片包含数个记忆体库(memory bank)—记忆体库就是数个位元格所组成的大型矩阵,而位元格,如上所述,具备字元线、位元线、一个感测放大器以及列缓冲区。由于同一秩内的芯片会同步运行,所以记忆体库一词也可以指同一秩内的8个芯片上的8个记忆体库。
在第一个案例,我们会使用「实体记忆库」一词,而在第二个案例,则偏好使用「逻辑记忆库」一词,但其实文献资料并不总是清楚界定这些术语。
在介绍这些术语后,我们现在就可以来谈谈不同的DRAM架构和世代,以及它们如何奠基在彼此的架构上进行改良。我们一样会先从个人电脑(PC)的常规DRAM模组谈起。
DRAM标准
常规DDR
DRAM记忆体已经存在许久,但我们不会在此上一堂完整的历史课。我们只会在开始讨论双倍数据传输率(double data rate;DDR)世代之前,先快速带过单倍数据传输率(single date rate;SDR)记忆体。我们要了解SDR的重点,是其介面与资料汇流排的I/O时脉(IO clock)与记忆体的内存时脉(internal clock)频率相同。这种记忆体受限于其内部记忆体的存取速度。
第一代DDR的目标是在每I/O时脉周期传输两个资料字组(data word),一组在时脉升缘时传输,另一组则在降缘时传输。此传输模式的设计者采用了预取(prefetching)这个概念来实现将传输速率翻倍。一个被称为「预取缓冲区(prefetch buffer)」的结构被插置在DRAM记忆体库和输出电路之间,这个小型缓冲区在每时脉周期、同一条汇流排上能够储存的位元数量,是原本SDR设计的两倍。
就x8芯片而言,其预取缓冲区为16位元。我们将此称作「2n」预取缓冲区。以读取一整列DRAM的内存读取周期来说,例如读取一列包含2000行的数据,就会有很多资料能来填充该预取缓冲区。该缓冲区内也会有足够的资料来填充汇流排,在时脉的升降两缘分别传递一组字组。
这个预取概念也适用于DDR2架构,只是其预取缓冲区变成「4n」。如此,设计者就能将I/O时脉提升至内存时脉的两倍,且在每周期内都能将资料汇流排填满资料。以此类推,DDR3同样将预取缓冲区的位元数翻倍(亦即「8n」),而其I/O时脉现在增至内存时脉的四倍。
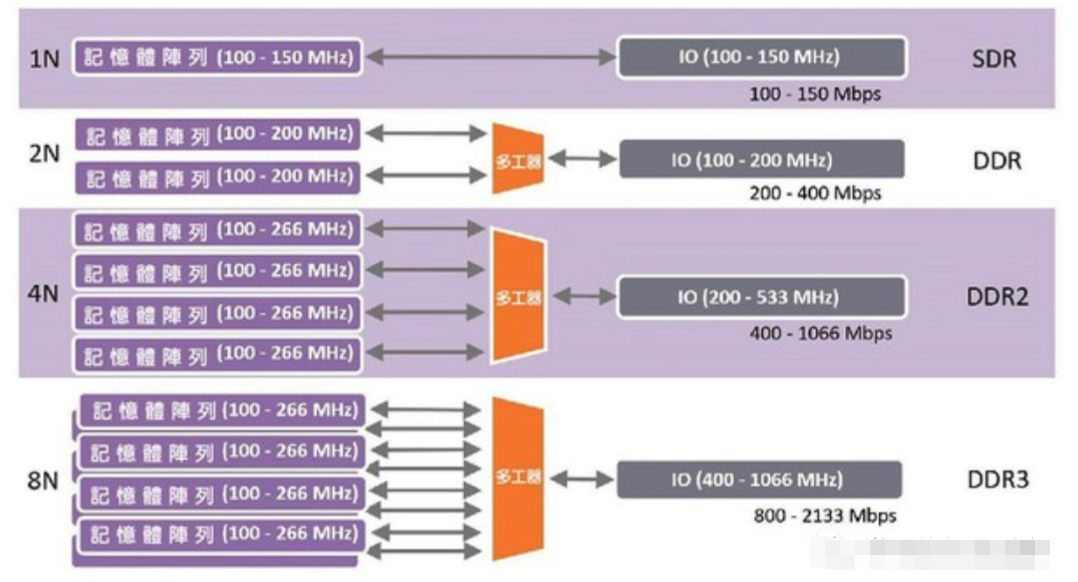
图二: DDR的预取机制(source:synopsys)
但是,如此类推还是有个极限。将预取缓冲区的传输位元数再度翻倍以达到「16n」,意味着每个读取指令中会有64个位元被传递至处理器16次,此资料量是一般快取行( cache line)的两倍(快取行是处理器快取资料的基本单位)。如果只有一条快取行包含有用资料,那么再去传递第二条快取行就会浪费很多时间和能耗。
因此,DDR4并未将预取的位元数翻倍,而采用了另一项技术,叫做记忆体分组(bank grouping)。该技术引进多组记忆体库,每组都有各自的8n预取缓冲区,另有一个多工器负责从适切的分组里选取输出资料。如果控制器的记忆体请求能以交错的方式发出,以连续请求来存取不同分组的资料的话,I/O速度一样能成长一倍,变成内存时脉的八倍。
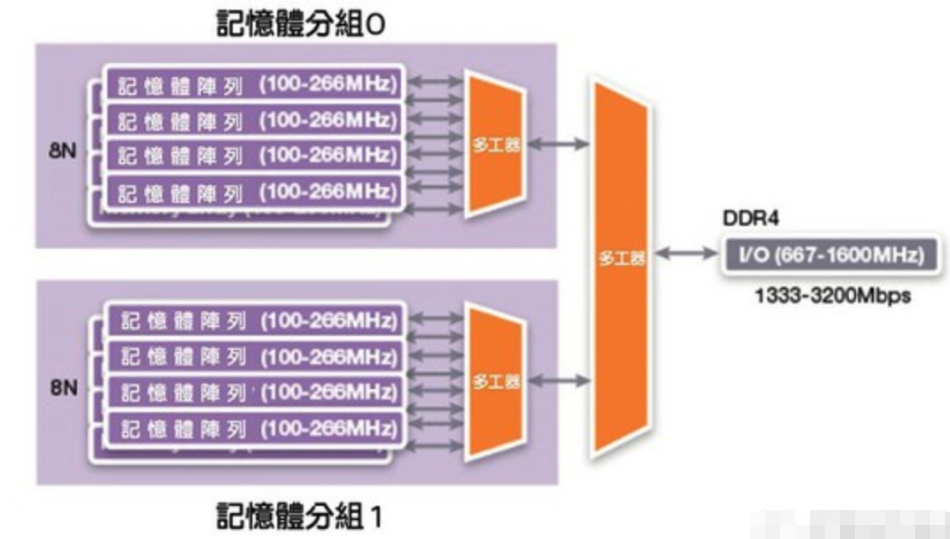
图三: 记忆体分组机制的示意图。(source:synopsys)
那么接下来的DDR5会如何发展?其目标也是要将I/O速度翻倍。DDR5呢,计画是引用一项已应用在LPDDR4的技术,我们称之为通道分裂(channel splitting)。
该技术将64位元的汇流排分成两个独立的32位元通道。因为现在每通道只提供32位元的资料空间,我们就能将预取增加至16n,这就能将存取粒度提升至64位元组,刚好等于一般快取行的资料大小。如此增加预取的资料量就能再次提升I/O时脉速度。
当然,提升I/O时脉速度并不只是在每周期内以充足的可用资料填充汇流排那样简单,还要面对多种与高频率讯号相关的挑战,像是讯号完整性、杂讯与功耗使用的问题。这些挑战可以运用几项技术解决,例如芯片内建终端架构(on-die termination)、差分时脉(differential clocking),以及将记忆体与处理器进行更密切的整合。这些技术大多源自其他DRAM架构,也就是LPDDR和GDDR,但我们将更聚焦在一个整合的概念上。
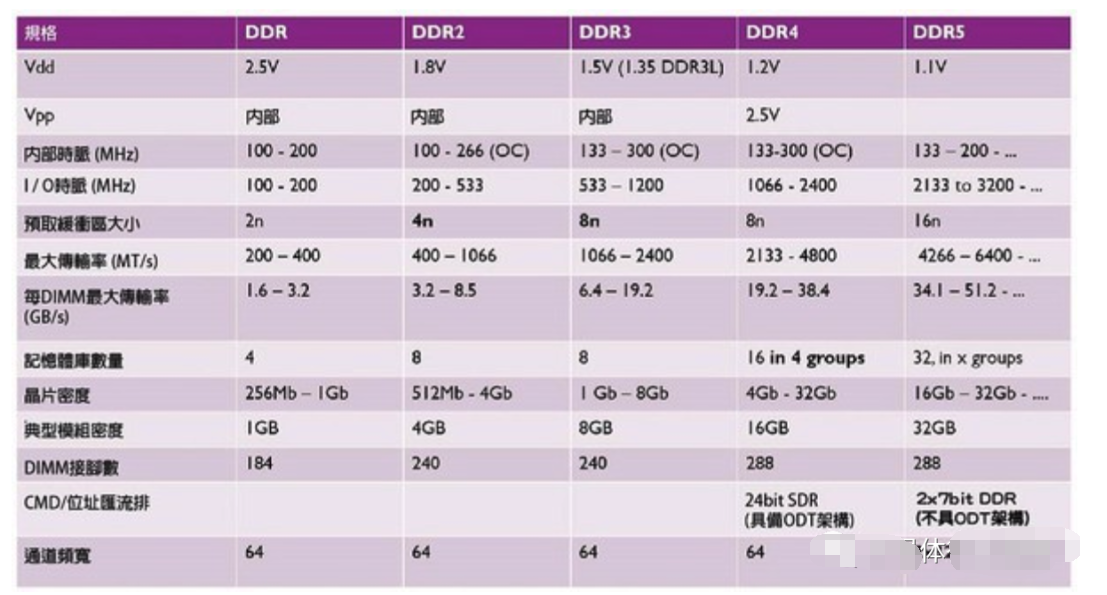
图四: 各代DDR记忆体的规格比较。
LPDDR
LPDDR指的是低功耗双倍数据传输率(low power DDR)。该标准的主要概念,一如其名,就是降低记忆体的功耗,而要实现这个目标有很多种方法。
LPDDR和普通记忆体的第一个差异,在于它和处理器的连接方式。LPDDR记忆体与处理器紧密整合,不论是被焊接在主机板上,与CPU紧邻,或是采用越来越普及的作法—以封装层叠技术(package-on-package;PoP)直接堆叠在处理器上方(通常是SoC)。更加紧密的整合能让连接记忆体和处理器间的导线电阻更小,进而降低功耗。
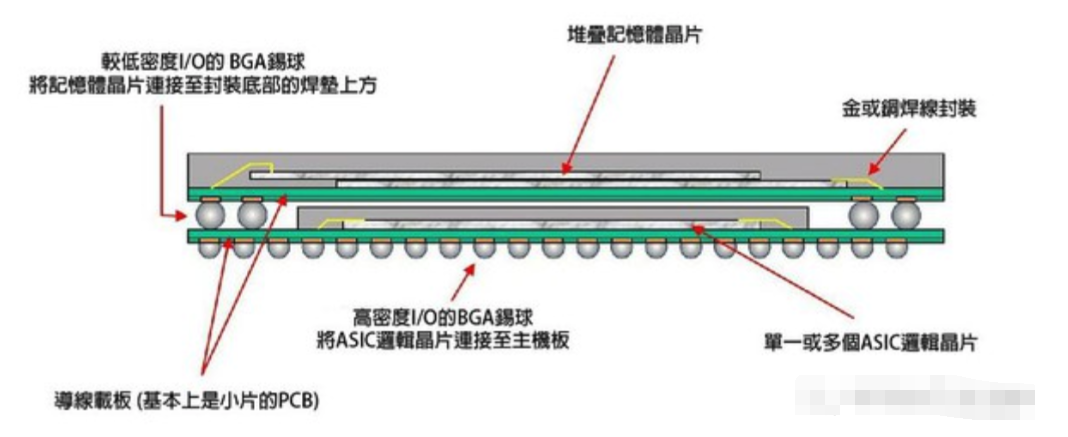
图五: 以封装层叠技术进行整合的示意图。(source:wikipedia)
第二个差异则是通道宽度。LPDDR记忆体没有固定的汇流排宽度,虽然一般来说最常见的是32位元。这个规格与普通记忆体相比算是较小,因而能节省能耗。
此外,LPDDR记忆体以较低的电压运作,这也会大大影响功耗。最后一点,LPDDR藉由多种办法优化记忆体更新这个步骤,像是依据温度调适更新、局部阵列自行更新(partial array self-refresh;PASR)、深度省电状态(deep power-down state)等,将LPDDR的备用功耗(standby power)大幅降低了。
我们现在不会深入探讨这些技术,但基本上它们都必须牺牲部份的反应时间,以换取更低的备用功耗,因为记忆体在能够回应请求前,需要一些时间从省电模式中「醒来」。
如上所述,不同代的LPDDR记忆体也采用了预取技术来增进性能。然而,LPDDR4是第一个引进16n缓冲区与通道分裂技术的标准,而LPDDR5预计会是第一个推出记忆体分组功能的标准。
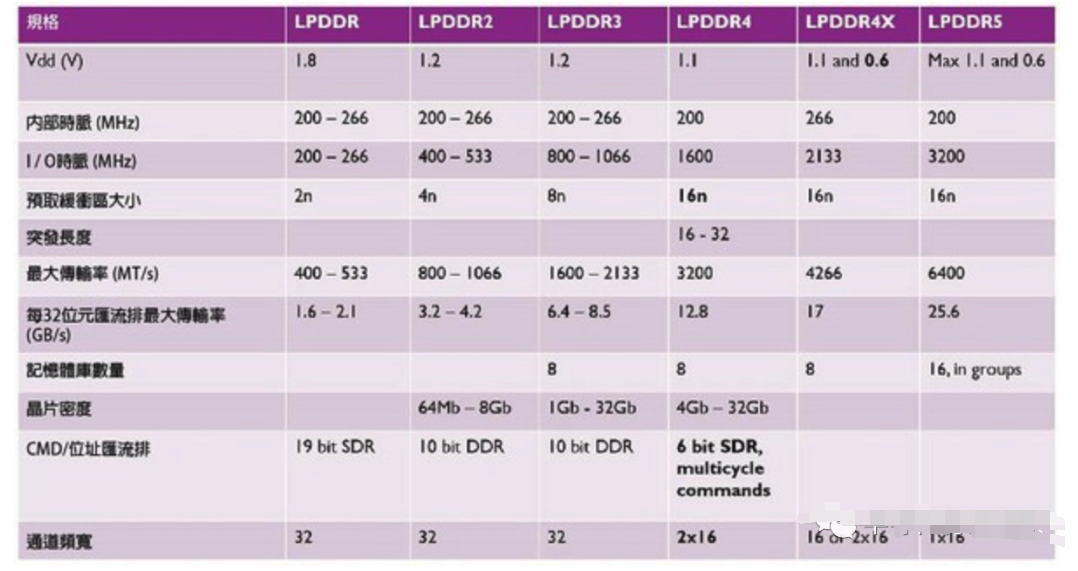
图六: 各代LPDDR记忆体的规格变化。
GDDR
GDDR亦即绘图用双倍数据传输率(graphics DDR),其命名暗指该标准适用于绘图芯片专用的记忆体。如今,这类记忆体在任何具备高频宽需求的应用上都相当备受瞩目,因为高频宽就是其焦点所在。
GDDR记忆体也与处理器—也就是图形处理器,密切地整合在一起,方法是将之焊接在PCB上。但GDDR记忆体并非直接放在GPU上方,因为这样很难达到预定的电容,且在此情况下会很难降温。
与传统DDR芯片(例如32位元)相比,GDDR芯片的频宽更宽,且每个芯片都直接连接至GPU,不须在一个固定64位元的汇流排上进行多工处理。也就是说,绘图芯片上会有更多GDDR芯片,也就会有更宽频的汇流排。
此外,由于这些芯片的接线不须进行多工处理,接线的频率也提高了,就能进一步提升GDDR记忆体的I/O时脉频率。透过使用更小的阵列与更大的周边电路,记忆体内部的读取速度变快了,I/O时脉速度因而提升,同时降低GDDR芯片的记忆体密度。
而更紧密结合记忆体与处理器也代表着,绘图芯片的最终电容更加受限,毕竟与大尺寸GPU紧密整合的GDDR芯片数量最多只有12个。
为了提升记忆体频宽,各代GDDR架构也采用与开发DDR时一样的技术。第一代GDDR标准是GDDR2,该标准基于DDR;而GDDR3基于DDR2;接下来是GDDR4,因为这代几乎不存在,所以略过不谈;GDDR5则以DDR3为基础,且一直到现在还是非常流行,GDDR5采用差分时脉,还能立即开启两个记忆体分页(memory page)。
GDDR5X则是增进GDDR5性能的过渡版本,采用了具备16n缓冲区的四倍数据传输率(quad data rate;QDR)模式,但缺点是存取粒度变大了,但这对GPU来说不是大问题;GDDR6则将通道分裂开来,就像LPDDR4,这样就能在同一汇流排上提供两个更小的独立通道,把存取粒度变小,实现具备16n缓冲区的QDR模式;没错,如此说来,GDDR6应该更适合叫做GQDR6。
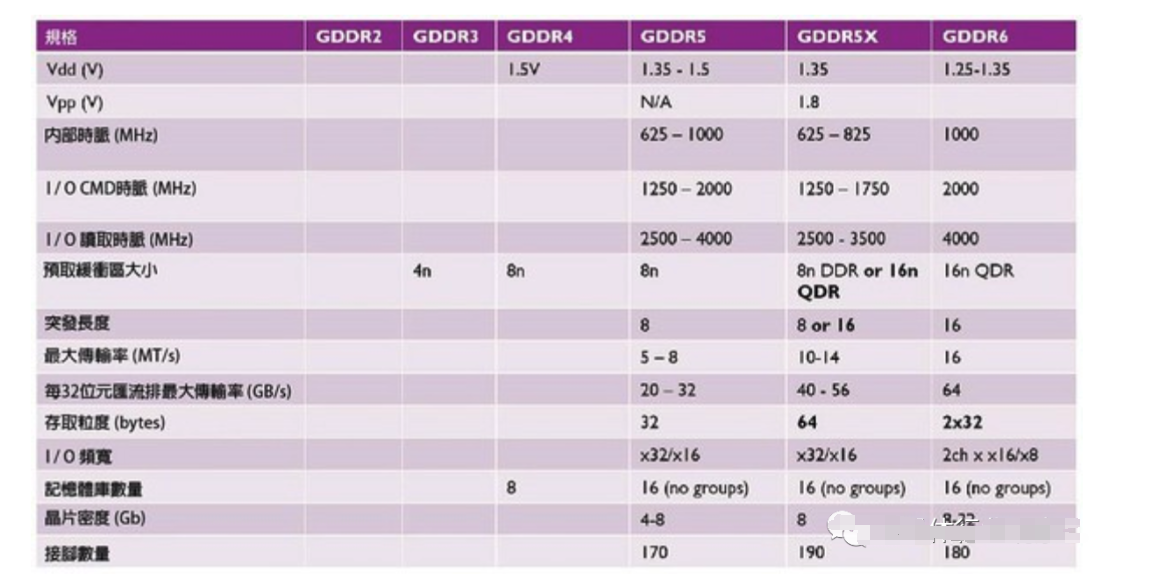
图七: 各代GDDR记忆体的规格比较。
3D革命
HBM
HBM和GDDR多有雷同,它也与GPU紧密整合,而且也不放在GPU上方,毕竟我们还需要大量电容并将芯片降温。那么HBM差在哪?
首先,HBM在PCB板的位置并不在GPU旁边,而是在连接GPU与芯片的中介层(interposer)上。目前,通常使用的是被动式硅中介层,亦即一大片不含任何主动元件的硅芯片,只有内连导线。
这种中介层的优点是能在上面布建更多平行导线,而不会耗费大量功率。因此,一个极宽的汇流排诞生了,以往这在PCB上是不可能实现的。然而,虽然这种中介层相当容易制造,但毕竟还是一大块硅芯片,因此成本也较高。
再者,记忆体芯片可以相互堆叠,使得芯片在垂直面上能实现小面积仍具备高电容。这些芯片具有大量的硅穿孔,连结记忆体堆内的各个芯片,以及其底部的逻辑芯片。而该逻辑芯片也会连结到中介层上的宽汇流排,使得记忆体芯片和GPU之间具备高频宽。事实上,该汇流排宽度充足,所以记忆体芯片的I/O时脉可以降至低频。而降频加上连接至GPU的导线长度极短,这两个特点就能在使用HBM时将每位元的能耗大幅降低(大约三倍)。
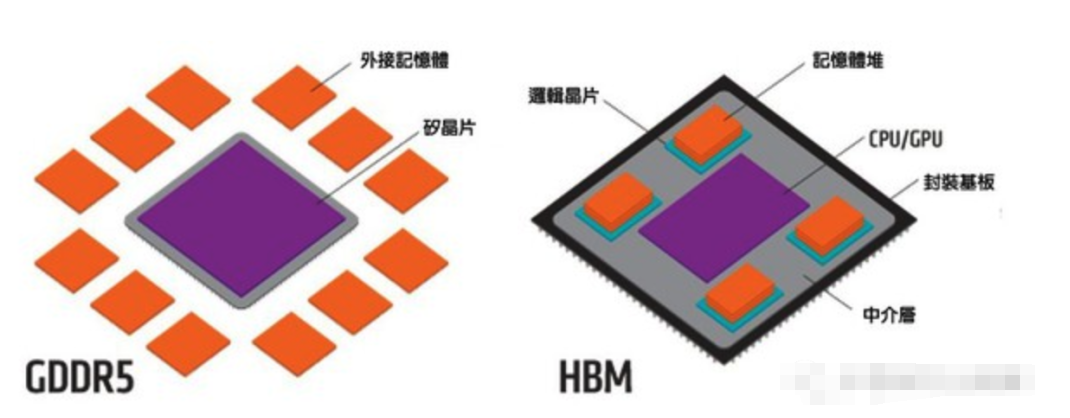
图一: GDDR5和HBM的比较。(source:graphicscardhub.com)
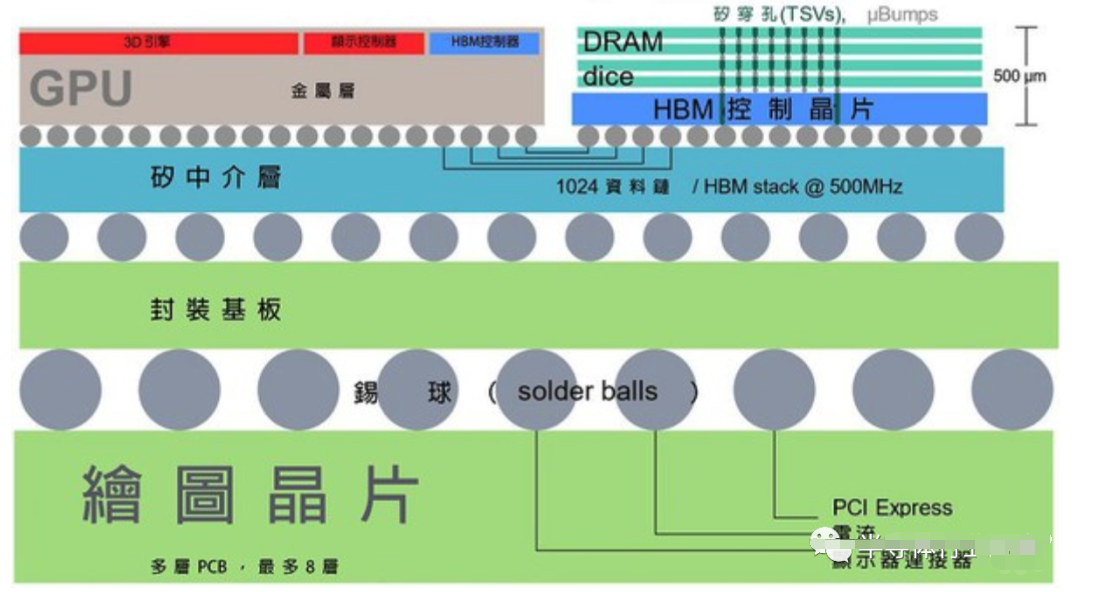
图二: HBM的芯片垂直面示意图(source:widipedia.org)
下表显示了不同代HBM的重点规格。目前来说,HBM2仍在供应中。有趣的是,三星去(2019)年发布了新款HBM2e记忆体,该产品跳脱常见规格,单位芯片具备更高电容(16Gb),并进一步提高资料传输率至每堆叠410GB/s。
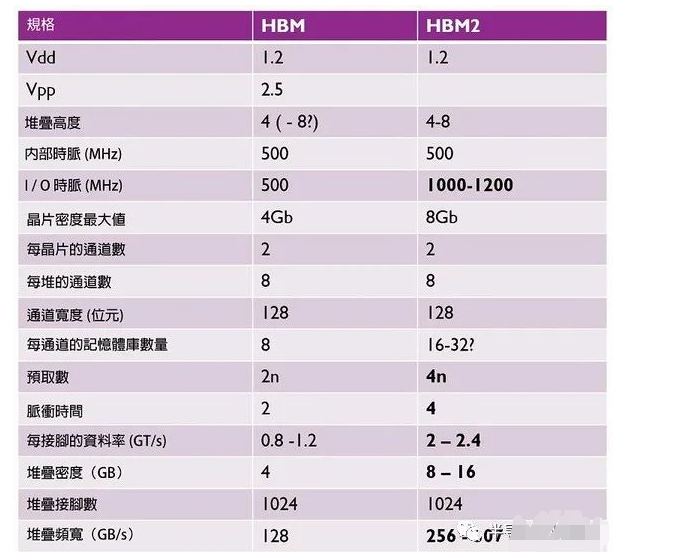
图三: 各代HBM的规格比较表。
HMC
尽管美光不再努力开发HMC标准,我们还是想要稍微介绍一下。HMC是常规DDR记忆体的3D版,特别锁定用在未来的伺服器上,虽然这个看法以往在业界并不总是很明确。HBM聚焦在频宽上,因此需要进行高度整合,牺牲电容和芯片扩展性。这就是所谓的「近记忆体(near memory)」。
HMC的重点则在电容,以及将更多记忆体堆轻松整合至伺服器内,就像运用闲置插槽来将更多DDR记忆体安装至主机板一样。这种方式能提供松弛整合,满足整体系统记忆体要实现高电容的需求。而这通常被称作「远记忆体(far memory)」。
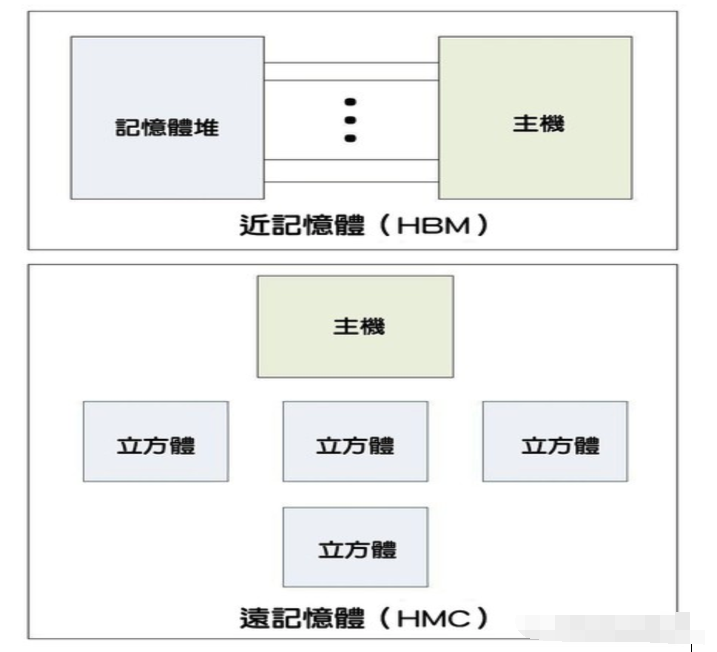
图四: 近记忆体与远记忆体的比较。(source:eejournal.com)
除了这点雷同之外,HMC是与DDR最不相同的记忆体标准,差异比其他任何在本文提到的标准都还大。HMC不使用DDR的汇流排传输方式,而是使用记忆体封包,这些封包以高速SerDes链接在处理器与记忆体立方体之间传递。如此就可能形成菊链立方体,以有限的内连导线达到更高电容。
此外,记忆体控制器完全整合在每个立方体的底座芯片,而不像DDR把控制器放在CPU芯片上,也不像HBM那样分置在GPU和记忆体堆上。
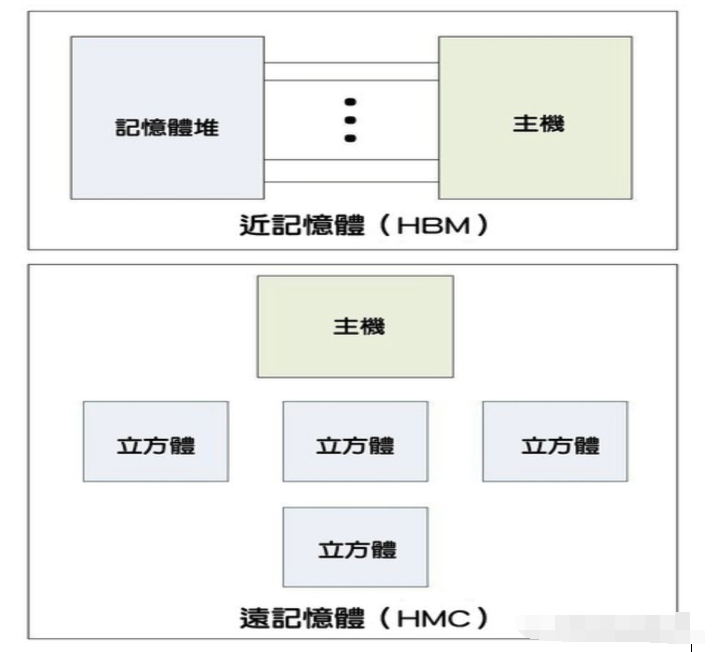
图五: 比较HMC与HBM结构的示意图(source:eejournal.com)
Wide I/O
Wide I/O是LPDDR记忆体的3D对应版本,优先采用极端的整合方式来实现可能的最低功耗。这类记忆体应该要直接整合在SoC上方,透过硅穿孔直接连至CPU芯片。如此就能将内连导线变得极短,其所需功耗是所有标准中最低的。
此外,Wide I/O还可能具备极宽的汇流排,端视硅穿孔的密度与尺寸而定。然而,这种极端的整合也要求在SoC内导入硅穿孔,这就会占去大片宝贵的逻辑芯片面积,因此成本极为高昂。这大概也是为什么我们还未见过任何采用该技术的商用产品。或许有趣的是,第一代Wide I/O标准采用了软体定义无线电(SDR)介面,但第二代标准改用DDR介面。
总结各类DRAM的特点
我们已经呈现了不同DRAM类型在设计本质上曾做出或将来会做出的一些必要取舍。每种标准最终都采用相同的概念来改善每一代版本的频宽,相关技术例如包含更大的预取缓冲区、记忆体分组、通道分裂、差分时脉、指令汇流排优化,以及更新优化( refresh optimization)。
不同标准不过是拥有各自的发展重点,不论是聚焦电容和弹性整合(DDR和HMC),或最低功耗(LPDDR和Wide I/O),还是最高频宽(GDDR和HBM)。看到3D技术带给这几个目标市场的优势,其实颇富趣味。
将记忆体进行紧密的3D整合,是能提升频宽的有效方式,但基本上还是会限制电容。首先,放在靠近运算单元的记忆体堆是有数量限制的,再者,每一堆叠能容纳的记忆体芯片数量也有限。
未来我们也将会明白,单一DRAM芯片的储存格数已经逼近极限了。随着各式应用对资料量的需求增长,在面对记忆体与处理器之间出现频宽落差的「记忆体墙(memory wall)」问题时,记忆体密度也成为一个更重要的考量点。
DRAM的未来展望:IMEC观点
为了将DRAM技术推升至其最终极限,并解决记忆体墙的技术问题,IMEC探索了两条可能的发展道路。这两条发展途径采用了完全迥异的技术,将需要全新的架构标准来促使下一代DRAM记忆体的诞生。
第一条发展途径是提升DRAM位元格的动态性(dynamic nature)。如本文开头所述,储存在DRAM位元格电容内的电荷会缓慢流失。因此,DRAM需要被更新。每列通常64毫秒更新一次。这会增加性能与功耗的常态性负担(overhead)。
采用铁电材料的电容设计(ferro capacitor)就是一个颇富潜力的办法,它能让DRAM位元格储存电荷的时间延长,这也有助于减缓选择晶体管(select transistor)对关闭电流的严苛要求。此外,铁电电容能改善DRAM的资料保存时间(retention time),这也带来诸多益处,例如可忽略更新的负担、快速开启或关闭低功耗模式、实现更低的备用功耗,以及进一步推动DRAM的规模化。
在IMEC的铁电研究计划中,他们正在开发以铁电材料为基础的金属—绝缘体—金属(metal-insulator-metal;MIM)电容器,以探索提升DRAM动态性的途径。为了有效发挥这项技术以达到最低功耗,就需要一套聚焦在这些非挥发特性的全新DRAM架构标准。
然而,要延续DRAM的规模化蓝图以开发出更多代的版本,上述的发展途径可能并不是最佳选项。因为规模化的问题,芯片密度已开始在约8~16GB的范围达到饱和,要将DRAM芯片的电容扩充至32GB以上变得相当困难。如果我们想要继续迈向规模化,将需要更具破坏性的创新技术。
其中一个办法是以低漏电流沉积的薄膜晶体管(thin-film transistor;TFT),像是氧化铟镓锌(indium-gallium-zinc-oxide;IGZO),来取代DRAM位元格内的硅基晶体管。这种材料的宽能隙能确保DRAM具备低关闭电流—这是DRAM储存单元晶体管的必要特性。由于我们不再需要材料硅来制造储存单元晶体管,现在就可以将DRAM储存单元的周边电路移至DRAM阵列下方。如此,储存单元的面积就能大幅降低。
下一步我们会考虑堆叠DRAM储存单元。储存电荷所需的电容已经达到规模化的极限,但要是我们能用极小的电容来储存电荷呢?甚至完全不用电容,又会怎样呢?
IGZO晶体管具备的超低漏电流就有可能开启一条全新道路,能够建立不须电容的DRAM储存单元。由于电容不再,加上IGZO晶体管所用之材料能与后段制程相容,甚至有机会采用可规模化的制程,将不同储存单元垂直堆叠。这带来许多好处,但也带给不同抽象层各式挑战,例如制程、技术、位元格设计、记忆电路设计与系统架构。
为了解决这些挑战,IMEC正在思考可能的跨层解决方案,用于未来的高性能DRAM标准,可能提供方法将DRAM记忆体进一步规模化,远远超过目前所预期的极限。
责任编辑人:CC
-
 2020Hank
2023-01-29
0 回复 举报但是,如此类推还是有个极限。将预取缓冲区的传输位元数再度翻倍以达到「16n」,意味着每个读取指令中会有64个位元被传递至处理器16次,16 * 8 = 128 bit 为什么是64 bit * 16呢 ? 收起回复
2020Hank
2023-01-29
0 回复 举报但是,如此类推还是有个极限。将预取缓冲区的传输位元数再度翻倍以达到「16n」,意味着每个读取指令中会有64个位元被传递至处理器16次,16 * 8 = 128 bit 为什么是64 bit * 16呢 ? 收起回复
-
DRAM的分类、特点及技术指标2024-08-20 9963
-
EMC滤波器的原理、分类、应用及未来展望2024-04-07 2732
-
EMC电磁兼容技术:原理、应用与未来展望2024-04-01 2759
-
三种近场通信技术的特点和未来展望2023-05-25 756
-
展望成像系统的未来2022-12-29 1656
-
DRAM原理 - 1.存储单元阵列#DRAMEE_Voky 2022-06-28
-
【资料】国嵌之精通嵌入式-第20课-展望未来(课件+视频)2021-08-23 2539
-
中国电动汽车标准的现状与展望2021-04-20 2556
-
DRAM存储原理和特点2020-12-10 5388
-
ATCA网络拓扑结构的原理和特点与应用及未来发展展望的详细说明2019-07-31 1576
-
宽频轻质吸波涂料有哪些研究?未来有哪些应用展望?2019-07-30 2099
-
未来语音接口的展望2019-07-16 1834
-
钰创科技开发全新的DRAM架构2019-02-11 5212
-
展望2013:DRAM产业五大重点趋势预测2013-01-10 1604
全部0条评论

快来发表一下你的评论吧 !
