

一种端到端的单阶段多视图融合3D检测方法MVAF-Net
描述
该方法将激光雷达投影的BEV和前向视角、与摄像头视角图像作为检测输入,在特征融合中,提出attentive pointwise fusion (APF) 模块。设计attentive pointwise weighting (APW) 模块学习,附加另外两个任务foreground分类和中心回归。

如图是架构图:整个MVAF-Net包括三个部分
1)单视图特征提取(SVFE),
2)多视图特征融合(MVFF)
3)融合特征检测(FFD)。
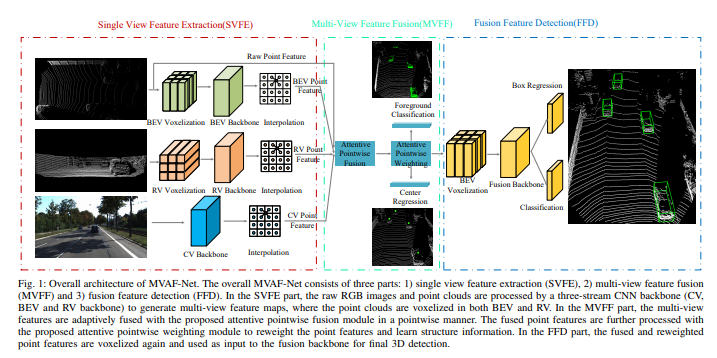
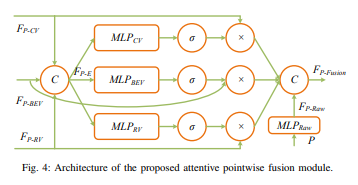
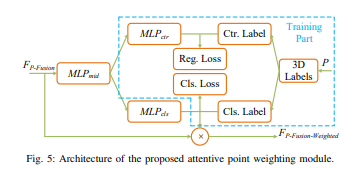
在SVFE部分,原始的RGB图像和点云由3-stream CNN主干(CV,BEV和RV)处理,生成多视图特征图,在BEV和RV做点云体素化。在MVFF部分,多视图特征与attentive pointwise fusion模块逐点自适应融合。融合的点特征通过attentive pointwise weighting模块进一步处理,对点特征进行加权并学习结构信息。在FFD部分,对融合和重加权的点特征再次体素化,并作融合主干输入给最终的3D检测。
RV投影表示为柱面坐标系统:
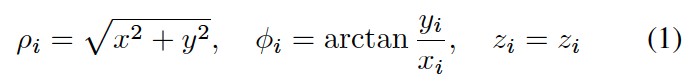
attentive pointwise fusion模块架构如下:
而attentive pointwise weighting模块架构如下:
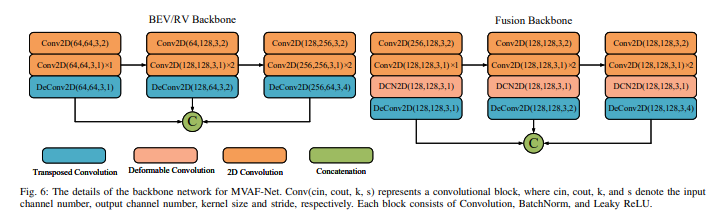
MVAF-Net的主干网络细节如下图:
检测头包括:分类(focal loss)、框回归(SmoothL1 loss)和方向分类(softMax loss)。其总loss函数为
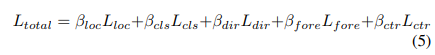
最后两个是前景分类项(focal loss)和中心回归项(SmoothL1 loss)。
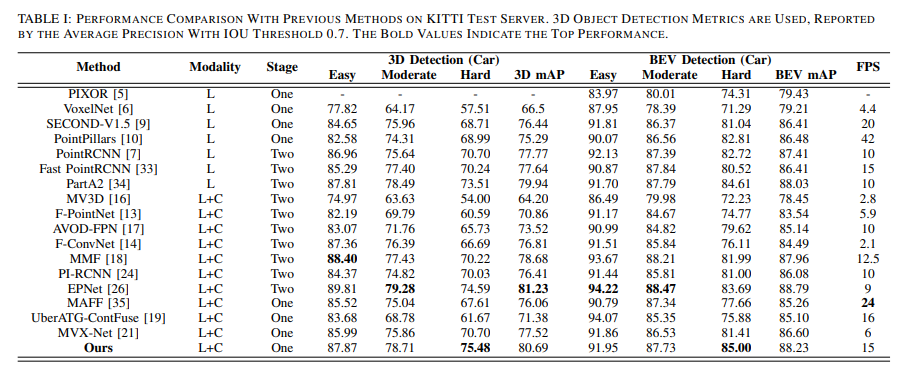
结果如下:
结论
我们提出了一种端到端的单阶段多视图融合3D检测方法MVAF-Net,它由三部分组成:单视图特征提取(SVFE),多视图特征融合(MVFF)和融合特征检测(FFD)。在SVFE部分,三流CNN主干(CV,BEV和RV主干)使用LiDAR点云和RGB图像来生成多视图特征图。在MVFF部分,使用我们提出的注意点向融合(APF)模块实现了多视图特征的自适应融合,该模块可以使用注意力机制自适应地确定从多视图输入中引入了多少信息。此外,我们通过提出的注意点加权(APW)模块进一步改善了网络的性能,该模块可以对点特征进行加权并通过两个额外的任务来学习结构信息:前景分类和中心回归。大量实验验证了所提出的APF和APW模块的有效性。此外,所提出的MVAF-Net产生了竞争性结果,并且在所有单阶段融合方法中均达到了最佳性能。此外,我们的MVAF-Net胜过大多数两阶段融合方法,在KITTI基准上实现了速度和精度之间的最佳平衡。
责任编辑:lq
-
介绍一种使用2D材料进行3D集成的新方法2024-01-13 2436
-
如何实现高精度的3D感知2023-10-17 2410
-
一种端到端的立体深度感知系统的设计2023-05-26 1678
-
一种二阶段端到端的自适应去雾生成网络2021-04-21 877
-
华为发布“5G+8K”3D VR端到端解决方案2021-04-13 3190
-
3D制图软件如何进行多CAD混合设计?2021-02-24 4099
-
一种基于端到端基于语音的对话代理2020-09-09 2466
-
一种先分割后分类的两阶段同步端到端缺陷检测方法2020-07-24 3421
-
两种建立元件3D图形的方法介2019-07-12 1789
-
一种不同步双端数据修正波速的单端行波定位方法2018-04-26 1124
-
一种多尺度多视点特性视图生成方法的研究和应用_谢冰2017-03-15 841
-
为什么同一种封装的器件的3D视图不一样?2011-12-04 3965
-
一种新的判别变压器绕组同名端的检测方法2009-08-24 1136
全部0条评论

快来发表一下你的评论吧 !
