

BP神经网络图像压缩算法乘累加单元的FPGA设计
FPGA/ASIC技术
描述
BP神经网络图像压缩算法乘累加单元的FPGA设计
0 引 言
神经网络(Neural Networks)是人工神经网络(Ar-tificial Neural Networks)的简称,是当前的研究热点之一。人脑在接受视觉感官传来的大量图像信息后,能迅速做出反应,并能在脑海中重现这些图像信息,这不仅与人脑的海量信息存储能力有关,还与人脑的信息处理能力,包括数据压缩能力有关。在各种神经网络中,多层前馈神经网络具有很强的信息处理能力,由于其采用BP算法,因此也称为BP神经网络。采用BP神经网络模型能完成图像数据的压缩处理。在图像压缩中,神经网络的处理优势在于:巨量并行性;信息处理和存储单元结合在一起;自组织自学习功能。
与传统的数字信号处理器DSP(Digital Signal Processor)相比,现场可编程门阵列(Field Programma-ble Gate Array,FPGA)在神经网络的实现上更具优势。DSP处理器在处理时采用指令顺序执行的方式,而且其数据位宽是固定的,因而资源的利用率不高,限制了处理器的数据吞吐量,还需要较大的存储空间。FPGA处理数据的方式是基于硬件的并行处理方式,即一个时钟周期内可并行完成多次运算,特别适合于神经网络的并行特点,而且它还可以根据设计要求配置硬件结构,例如根据实际需要,可灵活设计数据的位宽等。随着数字集成电路技术的飞速发展,FPGA芯片的处理能力得到了极大的提升,已经完全可以承担神经网络数据压缩处理的运算量和数据吞吐量。图像压缩是信息传输和存储系统的关键技术,然而如何进行FPGA设计,以实现给定的功能已经成为神经网络应用的关键。
基于以上原因,选择FPGA作为三层BP神经网络图像压缩算法的实现方式,提出了具体的一种实现方案,并对其中的重点单元进行了FPGA设计与仿真验证。
1 BP神经网络图像压缩算法
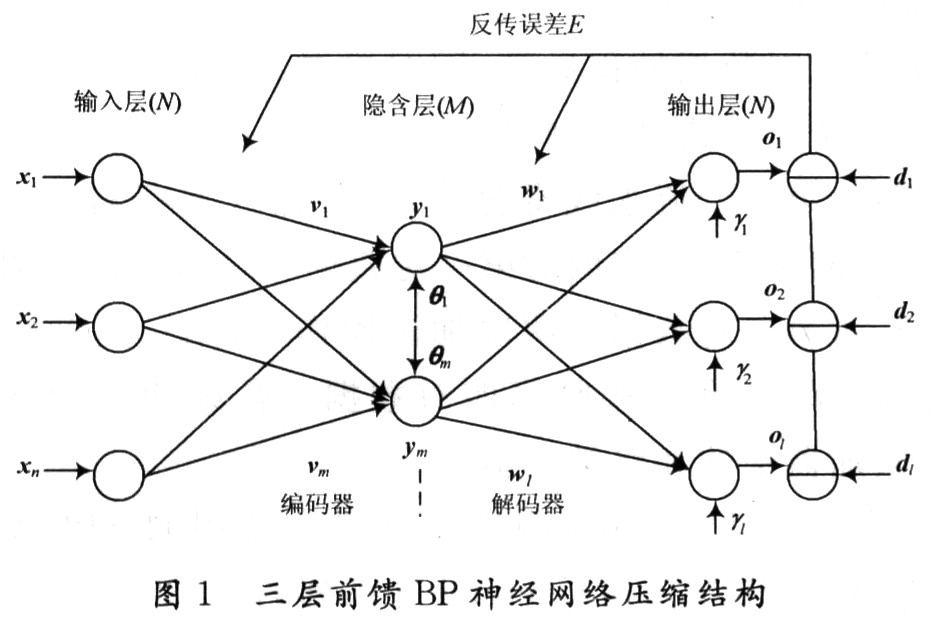
一般习惯将单隐层前馈网称为三层前馈网,它包括输入层、隐含层和输出层。三层BP神经网络结构如图1所示,原始数据节点和重建数据节点构成节点数较大的外层(输入层和输出层),而中间的具有较小节点数的细腰层即构成压缩结果。其基本思想是强迫原始数据通过细腰型网络瓶颈,并期望在网络的瓶颈处能获得较为紧凑的数据表示,以达到压缩的目的。在网络的学习过程中,通过BP训练算法,调整网络的权重,使重建图像在均方误差意义上尽可能近似于训练图像。经过训练的网络即可用来执行数据压缩任务,网络输入层与隐含层之间的加权值相当于一个编码器,隐含层与输出层之间的加权相当于一个解码器。从输入端输入的原始图像数据经过神经网络的处理,在隐含层得到的输出数据就是原始图像的压缩编码,而输出层矢量即为解压后重建的图像数据。
BP神经网络用于图像编码的压缩比与输入层和隐含层的节点数有关:
压缩比一输入层节点数(n)/隐含层节点数(m)
因此一般来说采用不同数目的隐含层神经元就可实现同一图像的不同压缩比。
三层BP前馈网中输入向量X=x(x1,x2,…,xi,…,xn)T,隐含层输出向量Y=y(y1,y2,…,yi,…,ym)T,输出层输出向量O=O(O1,O2,…,Ok,…,Ol)T,期望输出向量d=d(d1,d2,…,dk,…,dl)T,输入层到隐含层的权值向量V=v(v1,v2,…,vj,…,vm)T,其中vj为隐含层第j个神经元对应的权值向量;隐含层到输出层的权值向量W=W(w1,w2,…,wk,…wl)T,其中wk为输出层第k个神经元对应的权值向量;隐含层的阈值向量θ=(θ1,θ2,…,θi,…,θm)T;输出层的阈值向量γ=(γ1,γ2,…,γk,…,γl)T。
(1)用小的随机数对每一层的权值和偏差初始化,以保证网络不被大的加权输入饱和,并进行以下参数的设定或初始化:期望误差最小值;最大循环次数;修正权值的学习速率;
(2)将原始图像分为4×4或8×8大小的块,选取其中一块的像素值作为训练样本接入到输入层,计算各层输出:

其中:f(·)为BP网络中各层的传输函数。
(3)计算网络输出与期望输出之间的误差,判断是否小于期望误差,是则训练结束,否则至下一步,其中反传误差的计算式为:

(4)计算各层误差反传信号;
(5)调整各层权值和阈值;
(6)检查是否对所有样本完成一次训练,是则返回步骤(2),否则至步骤(7);
(7)检查网络是否达到最大循环次数,是则训练结束,否则返回步骤(2)。
经过多次训练,最后找出最好的一组权值和阈值,组成三层前馈神经网络,用于该算法的FPGA设计。

其中,在数据预处理部分,首先将原始图像分成n×n的小块,以每一小块为单位进行归一化。归一化的目的,主要有以下两点:
(1)BP网络的神经元均采用Sigmoid转移函数,变换后可防止因净输入的绝对值过大而使神经元输出饱和,继而使权值调整进入误差曲面的平坦区;
(2)Sigmoid转移函数的输出在-1~+1之间,作为信号的输出数据如不进行变换处理,势必使数值大的输出分量绝对误差大,数值小的输出分量绝对误差小。网络训练时只针对输出的总误差调整权值,其结果是在总误差中占份额小的输出分量相对误差较大,对输出量进行尺度变化后这个问题可迎刃而解。
归一化后得到以每小块的灰度值为列向量组成的待压缩矩阵,将该矩阵存储在RAM里,然后以每一列为单位发送给先人先出寄存器FIFO(First Input FirstOutput);由FIFO将向量x1,x2,…,xn以流水(pipe-line)方式依次传人各乘累加器MAC(Multiply-Accu-mulate),相乘累加求和后,送入LUT(Lookup Table)得到隐层相应的节点值,这里LUT是实现Sigmoid函数及其导函数的映射。
在整个电路的设计中,采用IP(Intellectual Prop-erty)核及VHDL代码相结合的设计方法,可重载IP软核,具有通用性好,便于移植等优点,但很多是收费的,比如说一个高性能流水线设计的MAC软核,所以基于成本考虑,使用VHDL语言完成MAC模块的设计,而RAM和FIFO模块则采用免费的可重载IP软核,使整个系统的设计达到最佳性价比。在压缩算法的实现中,乘累加单元是共同部分,也是编码和译码器FPGA实现的关键。
2.2 乘累加器MAC的流水线设计及其仿真
流水线设计是指将组合逻辑延时路径系统地分割,并在各个部分(分级)之间插人寄存器暂存中间数据的方法。流水线缩短了在一个时钟周期内信号通过的组合逻辑电路延时路径长度,从而提高时钟频率。对于同步电路,其速度指同步电路时钟的频率。同步时钟愈快,电路处理数据的时间间隔越短,电路在单位时间内处理的数据量就愈大,即电路的吞吐量就越大。理论而言,采用流水线技术能够提高同步电路的运行速度。MAC电路是实现BP神经网络的重要组成部分,在许多数字信号处理领域也有着广泛应用,比如数字解调器、数字滤波器和均衡器,所以如何提高MAC的效率和运算速度具有极高的使用价值。本方案采用的MAC设计以四输入为例。
四输入的MAC电路必须执行四次乘法操作和两次加法操作,以及最后的两次累加操作。如果按照非流水线设计,完成一次对输入的处理,需要这三步延迟时间的总和,这会降低一个高性能系统的效率。而采用流水线设计,则可以避免这种延迟,将MAC的操作安排的像一条装配线一样,也就是说,通过这种设计它可以使系统执行的时钟周期减小到流水线中最慢步骤所需的操作时间,而不是各步骤延迟时间之和,如图3所示。
在第一个时钟边沿,第一对数据被存储在输入寄存器中。在第一个时钟周期,乘法器对第一对数据进行乘法运算,同时系统为下一对数据的输入作准备。在第二个时钟边沿,第一对数据的积存储在第一个流水线寄存器,且第二对数据已经进入输入寄存器。在第二个时钟周期,完成对第一对数据积的两次加法操作,而乘法器完成第二对数据的积运算,同时准备接收第三队数据。在第三个时钟边沿,这些数据分别存放在第二个流水线寄存器,第一个流水线寄存器,以及输入寄存器中。在第三个时钟周期,完成对第一对数据和之前数据的累加求和,对第二对数据的两次加法操作,对第一对数据的乘法运算,并准备接收第四对数据。在第四个始终边沿,累加器中的和将被更新。
在本设计方案中,测试仿真平台选用的FPGA芯片为ALTERA公司CycloneⅡ系列的EP2C8芯片,它采用90 nm的制造工艺,拥有8 256个逻辑单元,36个M4K随机只读存储器,2个数字锁相环,以及18个硬乘法器等丰富资源。仿真工具使用业界流行的MentorGraphics公司的仿真软件Modelsim 6.1f。对设计进行验证时,常见的方法是在模拟时施加输入激励信号,然后“读”该设计的输出信号,它的主要缺点是随着模拟器的不同而不同。为了克服此缺点,采用的测试方法是用VHDL编写一个测试模型发生器,称为Testbench,它的优点是通用性好,灵活性强,可以随时更改输入激励,已得到不同的仿真结果。在对该MAC模块进行测试的过程中,涉及输入数据的转化问题,如前所述,在本神经网络中,输入数据归一化后,集中在-1~+1之间,所以处理时必须进行转化,最后采用16位补码形式的定点二进制表示法,由于在求和中可能会产生溢出,还必须包含一个溢l出状态信号。输入数据转换16位补码的仿真波形如图4所示。
16位补码转换原输入实数的仿真波形如图5所示。
在完成了对输入、输出数据的转换之后,编写Testbench(测试台)程序,对基于流水线设计的四输入MAC进行行为级仿真,仿真波形如图6所示。
综上所述,在基于流水线的乘法设计中,虽然每一步操作后都加入了寄存器,消耗了更多的资源,但却可以将系统延时降低到最慢步骤所需要的时间,极大地提高了同步电路的运算速度。
3 结 语
介绍了基于三层前馈BP神经网络的图像压缩算法,提出了基于FPGA的实现验证方案,详细讨论了实现该压缩网络组成的重要模块MAC电路的流水线设计。在对BP神经网络的电路设计中,对传输函数及其导函数的线性逼近也是近来研究的热点之一,本文使用的压缩查找表虽然能够满足设计要求,但仍然消耗了大量资源。该研究结果对整个压缩解压缩算法的实现以及多层神经网络的相关研究工作提供了参考。
-
什么是BP神经网络的反向传播算法2025-02-12 2213
-
bp神经网络算法的基本流程包括哪些2024-07-04 2392
-
BP神经网络算法的基本流程包括2024-07-03 1988
-
基于三层前馈BP神经网络的图像压缩算法解析2021-05-06 1787
-
神经网络图像压缩算法的FPGA实现技术研究论文免费下载2021-03-22 1378
-
BP神经网络图像压缩算法乘累加单元的FPGA设计论文详细说明2021-01-25 925
-
如何设计BP神经网络图像压缩算法?2019-08-08 4018
-
【案例分享】基于BP算法的前馈神经网络2019-07-21 3425
-
16篇关于FPGA图像处理的论文详细资料免费下载2018-12-25 1744
-
BP神经网络概述2018-06-19 45611
-
神经网络图像压缩算法的FPGA实现技术研究2016-09-17 895
-
BP神经网络图像压缩算法乘累加单元的FPGA设计2010-03-29 980
-
基于BP神经网络的2DPCA人脸识别算法2010-01-18 779
-
基于BP人工神经网络的图像压缩技术过程及分析2009-07-07 689
全部0条评论

快来发表一下你的评论吧 !
