

决策树的一般流程及应用
人工智能
描述
一、什么是决策树

图表示决策树
所有的机器学习算法中,决策树应该是最友好的了。它呢,在整个运行机制上可以很容易地被翻译成人们能看懂的语言,也因此被归为“白盒模型”。
为了更直观地理解决策树,我们现在来构建一个简单的邮件分类系统,如图:
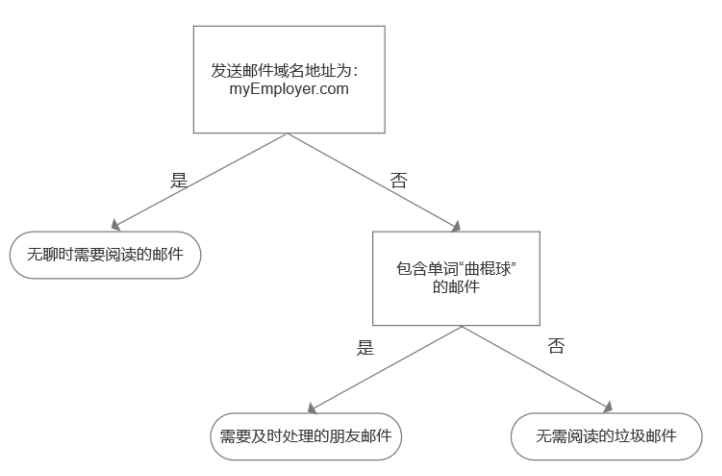
首先检测发送邮件域名地址;
如果地址为com,则放置于“无聊时需要阅读的邮件”分类;
如果不是这个地址,那么再次检测;
检查邮件是否有单词“曲棍球”;
包含单词“曲棍球”,则放置于“需要及时处理的朋友邮件”分类;
不包含单词“曲棍球”,则放置于“无需阅读的垃圾邮件”分类。
现在,我们来总结一下决策树的构成:
根节点。第一个需要判断的条件,往往也是最具有特征的那个条件,我们称为根节点。
中间节点。那个矩形总是要往下分,并不是最终的结果,它叫做中间节点(或内部节点)。
边。那些带有文字的线段(一般使用有箭头的有向线段),线的一端连的是中间节点、另一端连的是另一个中间节点或叶节点,然后线段上还有文字,它叫做边。
叶节点。那个圆角矩形,它就已经是最后的结果了,不再往下了,这一类东西呢,在决策树里叫做叶节点。
二、决策树的一般流程
收集数据:可以使用任何方法。
准备数据:树构造算法只适用于标称型数据,因此数值型数据必须离散化。
分析数据:可以使用任何方法,构造树完成后,我们应该检查图形是否符合预期。
训练算法:构造树的数据结构。
测试算法:使用经验树计算错误率。
使用算法:此步骤可以适用于任何机器学习算法,而使用决策树可以更好地理解数据的内在含义。
上面这种朴素的算法很容易想到,但是太容易得到的它往往不够美好。如果自变量很多的时候,我们该选哪个作为根节点呢?
选定了根节点后,树再往下生长接下来的内部节点该怎么选呢?针对这些问题,衍生了很多决策树算法,他们处理的根本问题是上面流程的第四步——训练算法,实际上也就是划分数据集方法。
我们来看看代表之一 —— ID3算法。
在划分数据集之前之后信息发生的变化称为信息增益,知道如何计算信息增益,我们就可以计算每个特征值划分数据集获得的信息增益,获得信息增益最高的特征就是最好的选择。
这里又引入了另一个概念——熵。这里先不展开说了,我们记住他的概念:一个事情它的随机性越大就越难预测。
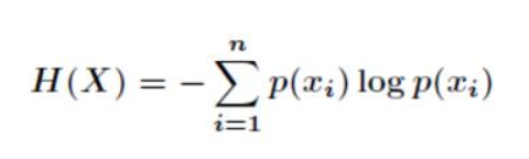
具体来说这个概率p越小,最后熵就越大(也就是信息量越大),如果极端情况一件事情概率为1,它的熵就变成0了。
比如,你如果能预测一个彩票的中奖号码就发达了。但是,如果你能预测明天太阳从东边升起来则毫无价值。这样衡量一个信息价值的事,就可以由熵来表示。
聪明的你或许已经发现了,决策树算法其实就是为了找到能够迅速使熵变小,直至熵为0的那条路径,这就是信息增益的那条路。我们将对每个特征划分数据集的结果计算一次信息熵,然后判断按照哪个特征划分数据集是最好的划分方式。
举个容易理解的例子:
解决问题:预设4个自变量:天气、温度、湿度、风速,预测学校会不会举办运动会?
步骤一:假设我们记录了某个学校14届校运会按时举行或取消的记录,举行或者取消的概率分别为:9/14、5/14,那么它的信息熵,这里也叫先验熵,为:
步骤二:我们同时记录了当天的天气情况,发现天气好坏和校运会举行还是取消有关。14天中,5次晴天(2次举行、3次取消)、5次雨天(3次举行、2次取消)、4次阴天(4次举行)。相对应的晴天、阴天、雨天的后验熵。

步骤三:我们计算知道天气情况后的条件熵。
步骤四:我们计算在有没有天气情况这个条件前后的信息增益就是。
步骤五:我们依次计算在有没有温度、湿度、风速条件前后的信息增益。
步骤六:根据设置的阈值,若信息增益的值大于设置的阈值,选取为我们的特征值,也就是我们上图中的矩形节点。
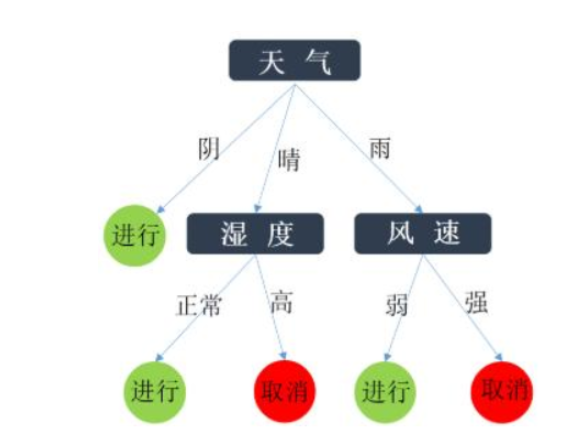
步骤七:生成决策树。选取信息增益最大的自变量作为根节点。其他的特征值依次选取为内部节点。
比如上面的例子是这样的过程:
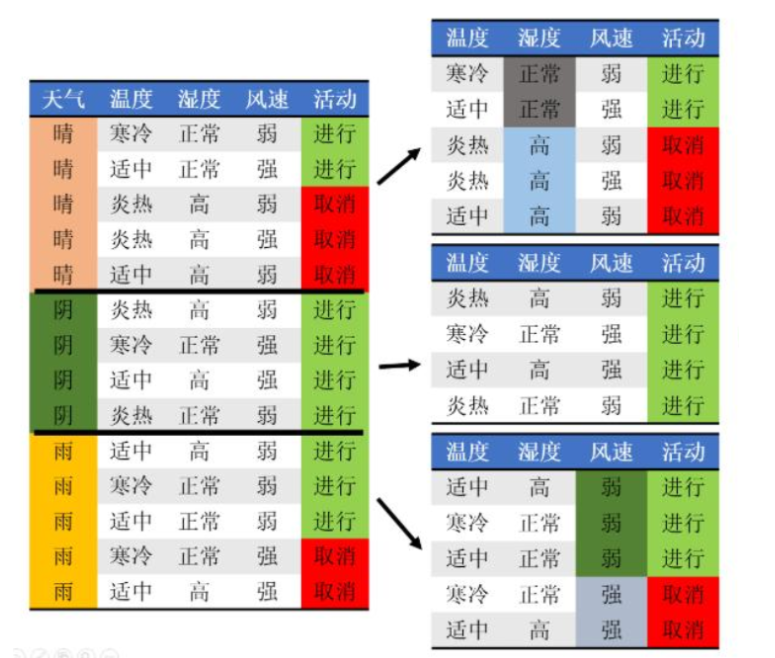
经过如上步骤,我们得到决策树。可以看到,最终们只选取了3个特征值作为内部节点。
三、决策树的应用
决策树也是一种分类方法。它的分类是二元的,一个值经过相应节点的测验,要么进入真分支,要么进入假分支。所以一组值经过决策树以后,就会形成从树跟到结果节点的一条唯一路径。所以它除了可以对输入进行分类之外,还能给出如此分类的解释。因此决策树常常被应用于专家系统,用于解释回答人类专家才能回答的问题。
责任编辑人:CC
-
关于决策树,这些知识点不可错过2018-05-23 5126
-
分类与回归方法之决策树2019-11-05 1235
-
机器学习的决策树介绍2020-04-02 1865
-
ML之决策树与随机森林2020-07-08 2176
-
决策树的生成资料2023-09-08 665
-
一个基于粗集的决策树规则提取算法2009-10-10 714
-
决策树的介绍2016-09-18 703
-
决策树的构建设计并用Graphviz实现决策树的可视化2017-11-15 15397
-
决策树的原理和决策树构建的准备工作,机器学习决策树的原理2018-10-08 7192
-
决策树和随机森林模型2019-04-19 9255
-
决策树的构成要素及算法2020-08-27 5015
-
决策树的基本概念/学习步骤/算法/优缺点2021-01-27 3386
-
什么是决策树模型,决策树模型的绘制方法2021-02-18 14262
-
决策树的结构/优缺点/生成2021-03-04 8994
-
大数据—决策树2022-10-20 2138
全部0条评论

快来发表一下你的评论吧 !
