

SVE架构特性和指令基本用法介绍
描述
SVE(Scalable Vector Extension)是arm AArch64架构下的下一代SIMD指令集,旨在加速高性能计算,SVE引入了很多新的架构特点, 比如
• 可变矢量长度
• 每通道预测
• 聚集加载和分散存储
• 横向操作
本文将对SVE做个基本介绍。
1. SIMD指令发展史 intel vs arm
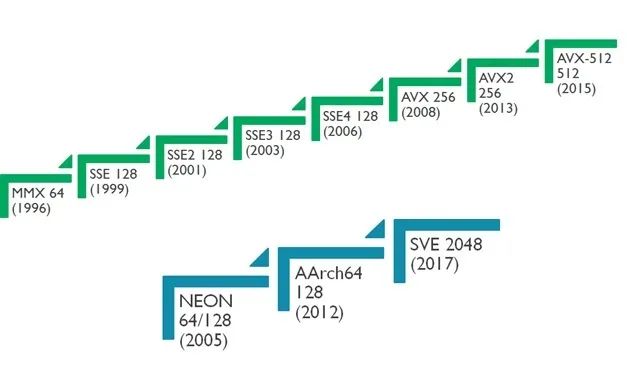
从上图我们可以看出,SIMD指令总体趋势是向着越来越长的方向发展的,到了arm SVE,最长可以支持2048位的矢量操作。
2. 背景
Armv7的高级SIMD (即arm NEON 或“MPE” 多媒体处理引擎) 指令集自2005年发布,已经面世十几年了。Armv7 NEON的主要特性如下:
• 支持8/16/32位整数操作,支持非IEEE兼容单精度浮点操作,支持指令条件执行
• 32个64位矢量寄存器,也可视为16个128位矢量寄存器
• 旨在CPU端加速多媒体处理任务
在升级到armv8架构时,AArch64 NEON指令集做出了许多改进,比如:
• 支持IEEE兼容单精度和双精度浮点操作和64位整数矢量操作
• 32个128位矢量寄存器
• 这些改进使NEON指令集更适用于通用计算,而不仅仅是多媒体计算
但是到了现在,armv8的新市场需要更彻底的SIMD指令改进。我们需要能够并行处理非常规数据和复杂数据结构,也需要更长的矢量,SVE因此而生,SVE旨在加速高性能计算。
3. SVE特性
SVE是armv8 AArch64架构的下一代SIMD指令集,它不是NEON的替代,而是聚焦于高性能计算。主要特性如下:
• 可变矢量长度
• 128位的整数倍。 最高可支持2048位
• 不同的实现可以适应不同的应用场景,不用更改指令集
• 每通道预测
• 支持复杂嵌套循环和if/then/else条件跳转, 没有循环尾数。
• 聚集加载和分散存储支持复杂数据结构,如步长数据存取、数组索引,链表等。
• 横向操作
• 支持基本的reduction操作,降低循环依赖性
4. SVE寄存器
SVE寄存器有两种:矢量寄存器和预测寄存器。
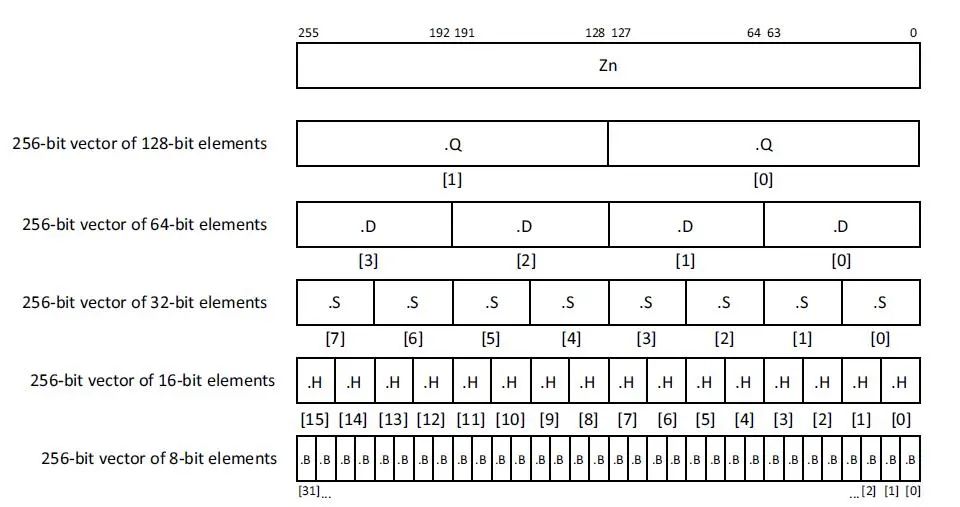
SVE共有32个可变长矢量寄存器Z0-Z31(128位的整数倍, 最高可达2048位) ,其中Z0-Z31的低128位[127:0],与AArch64 SIMD&FP寄存器V0-V31共享硬件资源。假设SVE的矢量长度为256,其矢量寄存器视图如下。SVE支持8/16/32/64位整数操作和单精度/双精度浮点操作。
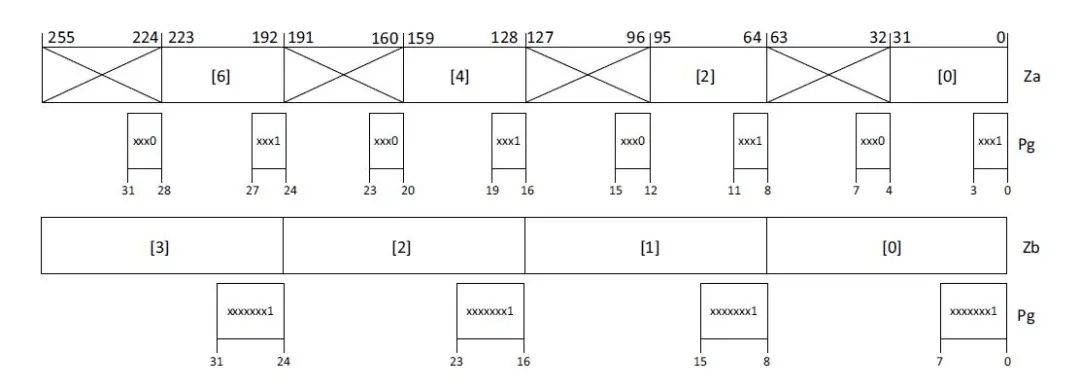
SVE预测寄存器用于控制每通道操作,有16个可变长预测寄存器P0-P15。每一个预测寄存器的位对应矢量寄存器的字节。假设SVE的矢量长度为256,预测寄存器在管理32位和64位操作时,其视图如下。在控制32位数据操作时,如果Pg寄存器的最低为1,则该通道操作为激活状态,该通道操作结果被正常存储到目的寄存器;如果Pg寄存器的最低为0,则该通道操作为未激活状态,该通道操作结果不会被存储到目的寄存器,目的寄存器的该通道数据有两种可能:
• 指令指定为Pg/z - 清零模式,该通道数据被清零。
• 指令指定为Pg/m – 合并模式,该通道数据保持原值
5. SVE指令实例
下面我们通过一些实例来介绍常用SVE指令的用法。
a. 矢量加法
大家也许都熟悉NEON的指令格式(如下),NEON指令通过对指令助记符添加“f”前缀来区分整数操作和浮点操作,如“add”和“fadd”;另外通过寄存器后缀“.2s”、“.4s”、“.2d”表示操作两个32位、四个32位数据、两个64位数据。
• add v0.4s, v0.4s, v1.4s
• fadd v0.2s, v0.2s, v1.2s
• fadd v0.2d, v0.2d, v1.2d
SVE指令也通过对指令助记符添加 “f” 前缀来区分整数操作和浮点操作。但是SVE是未知矢量长度编程,因此在指令中我们只需要指明操作数据类型就可以了。
• add z0.s, z0.s, z1.s
• fadd z0.s, z0.s, z1.s
• fadd z0.d, z0.d, z1.d
b. 矢量加载
对于加载指令,NEON指令通过助记符“ld1”、“ld2”表示加载一维数组、二维数组;通过寄存器后缀“.8h”、“.4s”表示加载八个16位、四个32位数据。
• ld1 {v0.8h}, [x1]
• ld1 {v0.4s}, [x1]
• ld2 {v0.4s, v1,4s}, [x1]
SVE加载指令添加指令助记符后缀 “h“、”w“表示读取存储元素宽度;寄存器后缀”.h“、”.s“表示元素在寄存器中的宽度。寄存器元素宽度必须大于等于读取存储宽度。对于加载指令,读取元素可以通过符号扩展或者零扩展填充到矢量寄存器;对于存储指令,每个矢量元素被截断后存储到内存中。
• ld1h {z0.h}, p0/z, [x1]
• ld1w {z0.s}, p0/z, [x1]
• ld2w {z0.s, z1.s}, p0/z, [x1]
6. 小结
本文简单介绍了SVE架构特性和指令基本用法,后续还会再写文章介绍如何在C程序中利用SVE。
原文标题:一文了解SIMD指令集SVE(可伸缩矢量扩展),加速高性能计算
文章出处:【微信公众号:安芯教育科技】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
移植和优化Arm SVE文档的HPC应用程序2023-08-24 773
-
SVE编程示例2023-08-22 1672
-
SVE优化指南2023-08-17 655
-
了解Armv9-A体系结构之SVE2简介2023-08-02 1405
-
SCL语言for指令的用法2023-06-19 4431
-
使用SVE对HACCmk进行矢量化的案例研究2022-11-08 3835
-
一文浅析SVE和SVE22022-11-02 4372
-
简述ARM SVE的发展以及和NEON的区别来探讨Vector在AI中的应用2022-09-19 3696
-
重新思考SVE编程的编译策略2022-09-08 2873
-
一文详解SIMD架构与SVE2的演进2022-08-12 5004
-
使用GCC10充分利用Arm架构的案例2022-08-03 2737
-
MSF及Unicorn的介绍及用法2017-09-07 1163
-
常用灯头规格及用法介绍2010-04-19 741
全部0条评论

快来发表一下你的评论吧 !
