

腾讯云虚拟化开源团队为内核引入全新虚拟文件系统
描述
Linux内存管理概述
我们知道linux系统内核的主要工作之一是管理系统中安装的物理内存,系统中内存是以page页为单位进行分配,每个page页的大小是4K,如果我们需要申请使用内存则内核的分配流程是这样的,首先内核会为元数据分配内存存储空间,然后才分配实际的物理内存页,再分配对应的虚拟地址空间和更新页表。
好奇的同学肯定想问,元数据是什么,为什么我申请内存还要分配元数据,元数据有什么用呢?
其实为了管理内存页的使用情况,内核设计者采用了page structure(页面结构)的数据结构,也就是我们所说的元数据来跟踪内存,该数据结构以数组的形式保存在内存中,并且以physical frame number(物理页框号)为索引来做快速访问 (见图1) 。
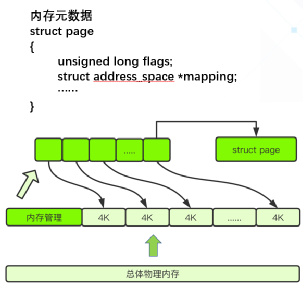
(图1)
元数据存储着各种内存信息,比如使用大页复合页的信息,slub分配器的信息等等,以便告诉内核该如何使用每个页面,以及跟踪页面在各个映射列表上的位置,或将其连接到后端的存储等等。所以在内核的内存管理中页面元数据的重要性不言而喻,目前在64位系统上这个数据结构占用64个字节,而由于通常的页面大小为4KB,比如一台安装了4GB内存的普通电脑上就有1048576个普通页,这意味着差不多需要64MB大小的内存来存储内存元数据来用于管理内存普通页。
似乎看起来并没有占用很多内存,但是在某些应用场景下面可就不同了哦,现今的云服务中普遍安装了海量内存来支持各种业务的运行,尤其是AI和机器学习等场景下面,比如图2中,如果服务器主机有768g的内存,则其中能真正被业务使用的只有753g,有大约10多个g的物理内存就被内存元数据所占用了,假如我们可以精简这部分内存,再将其回收利用起来,则云服务提供商就可以提供更多的云主机给自己的客户,从而增加每台服务器能带来的收入,降低了总体拥有成本,也就是我们常说的TCO,有那么多好处肯定是要付诸实施咯,但是我们要如何正确并且巧妙地处理这个问题而不影响系统的稳定性呢?
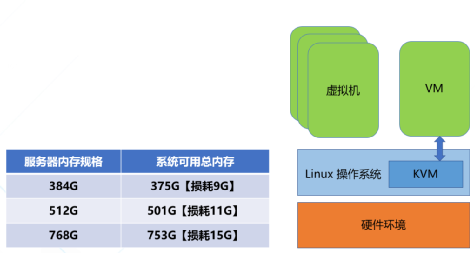
(图2)
Direct Memory Management File System (直接内存管理文件系统)
有的小伙伴会说好像现有的内核接口就可以解决类似问题呀,比如我可以mmap系统中的/dev/mem,将线性地址描述的物理内存直接映射到进程的地址空间内,不但可以直接访问这部分内存也绕过了内核繁复的内存管理机制,岂不是很方便。但其实这里有很大的局限性,首先对于/dev/mem的访问需要root权限的加持,这就增加了内核被攻击的风险,其次mmap映射出来的是一整块连续的内存,在使用的过程中如何进行碎片化的管理和回收,都会相应需要用户态程序增加大量的代码复杂度和额外的开销。 为了既能更好地提高内存利用率,又不影响已有的用户态业务代码逻辑,腾讯云虚拟化开源团队独辟蹊径,为内核引入了全新的虚拟文件系统 - Direct Memory Management File System(直接内存管理文件系统)(见图3),该文件系统可以支持页面离散化映射用来避免内存碎片,同时全新设计了高效的remap (重映射)机制用来处理内存硬件故障(MCE)的情况,并且对KVM、VFIO和内存子系统交互所用到的接口都进行了优化,用来加速虚拟机机EPT页表和IOMMU页表的建立,在避免了内存元数据的额外开销的情况下还增加了虚拟机的性能提升的空间。
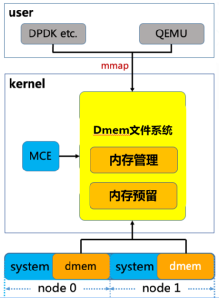
(图3)
从内存管理上来看,dmemfs在服务器系统启动引导的时候就将指定数量的内存预先保留在系统中的各个NUMA节点上,这部分内存没有被系统内存管理机制接管,也就不需要消耗额外的内存来存储元数据。 我们知道内核的内存信息全部来自e820表, 这部分e820信息只提供了内存的区间描述和类型,无法提供NUMA节点信息, 所以必须在memblock初始化之后, 内核buddy伙伴系统初始化之前做好内存预留 (见图4), 而这时memblock可能已经有分配出去的空间, 以及BIOS会预留等等原因, 导致同一个节点存在不连续的内存块,因此dmemfs引入了全新的kernel parameter “dmem=”,并将其指定为early param。 内核在解析完参数之后会将得到的信息全部存放在全局结构体dmem_param,其中包含着我们需要预留的memory的大小和起始地址等,随后在内核初始化到在ACPI处理和paging_ini()之间,我们插入dmem的预留处理函数memblock_reserve(),将dmem内存从memblock中扣除,形成dmem内存池。而存留在memblock中的系统内存则会被paging_init()构建对应的内存元数据并纳入buddy子系统。(见图4)
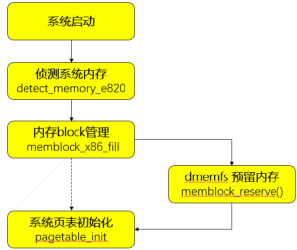
(图4)
预留下来的内存由称为dmem_pool的内存池结构体来管理,第一层拓扑为dmem numa node,用来描述dmem在各个numa 节点上的分布情况以实现了numa亲和性,第二层拓扑是在dmem numa node的基础上再实现一个dmem region链表,以描述当前节点下每段连续的dmem内存区间(见图5)。每个region中以page作为分配的最小颗粒度,都关联到一个local bitmap来维护和管理每个dmem 页面的状态,在挂载dmemfs文件系统时为每个 region申请并关联 bitmap, 并且指定页面大小的粒度, 比如4K, 2M或1G,从而方便在服务器集群中部署使用
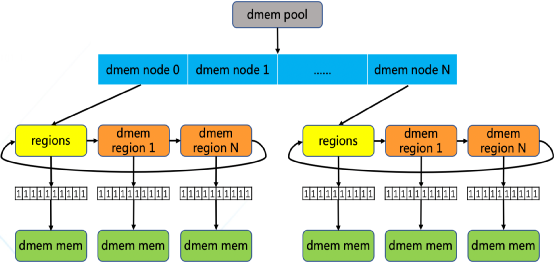
(图5)
简单的来说在挂载了dmemfs文件系统之后,就可以使用如下的qemu参数将dmemfs所管理的物理内存传递给虚拟机直接使用。
而在虚拟机启动之后,对内存的读写会发生缺页异常,而内核的缺页处理机制会将请求发送给dmemfs,dmemfs就会将预留内存按照所需页面的大小补充到EPT表中从而帮助虚拟机建立好GVA->HPA的映射关系。 为了满足实际生产环境,dmemfs还必须支持对MCE的处理。MCE, 即Machine Check ERROR, 是一种用来报告系统错误的硬件方式。当触发了MCE时, 在Linux内核流程中会检查这个物理页面是否属于dmem管理, 我们在基于每个连续内存块的dmem region内引入了一个error_bitmap, 这是以物理页面为单位的, 来记录当前系统中发生过mce的页。同时通过多个手段, 保证分配内存使用的bitmap和这个mce error_bitmap保持同步, 从而后续的分配请求会跳过这些错误页面(见图6)。 然后在内存管理部分引入一个 mce通知链, 通过注册相应的处理函数, 在触发mce时可以通知使用者进行相应的处理。 而在dmem文件系统层面, 我们则通过inode链表来追踪文件系统的inode,当文件系统收到通知以后, 会遍历这个链表来判断并得到错误页面所属的inode,再遍历inode关联的vma红黑树, 最终得到使用这些错误页的相关进程进行相应的处理。
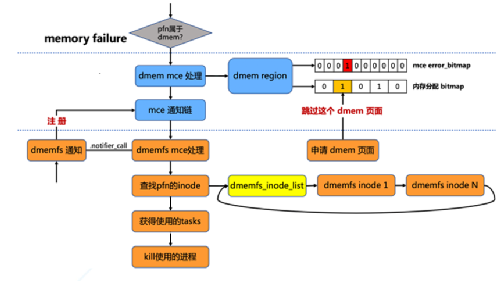
(图6)
在使用了dmemfs之后,由于消除了冗余的内存元数据结构,内存的额外消耗有了显著地下降,从图7的实验数据中可以看到,内存规格384GB的服务器中, 内存消耗从9GB降到2GB, 消耗降低了77.8%,而内存规格越大, 使用内存全售卖方案对内存资源的消耗占比越小, 从而可以将更多内存回收再利用起来, 降低了服务器平台成本。
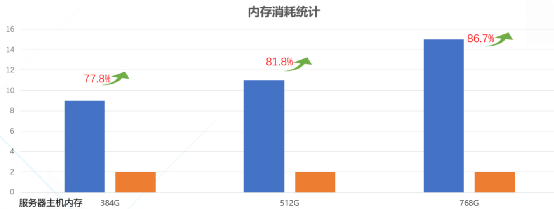
(图 7)
原文标题:内存管理的另辟蹊径 - 腾讯云虚拟化开源团队为内核引入全新虚拟文件系统(dmemfs)
文章出处:【微信公众号:Linuxer】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
Jtti:Linux中虚拟文件系统和容器化的关系2024-11-27 1140
-
鸿蒙轻内核源码分析:虚拟文件系统 VFS2024-02-18 2894
-
Linux虚拟文件系统的基础知识2023-08-25 978
-
Linux平台/proc虚拟文件系统详解2023-06-08 2458
-
RT-Thread文档_虚拟文件系统2023-02-22 572
-
LiteOS-A内核中的procfs文件系统分析2022-12-02 2013
-
深入剖析Linux内核虚拟文件系统2022-05-14 4210
-
VFS虚拟文件系统描述2021-12-22 1646
-
STM32F429 sdio虚拟文件系统的相关资料推荐2021-12-13 997
-
linux 虚拟文件可以系统实现2019-05-04 883
-
Linux 内核/sys 文件系统介绍2019-04-25 5080
-
简单介绍Linux虚拟文件系统–VFS2019-04-24 2247
-
Xilinx Zynq制作修改根文件系统的方法2018-07-13 4336
-
玩转Linux,先把文件系统搞懂2017-08-16 2330
全部0条评论

快来发表一下你的评论吧 !
