

ucos的TSLF内存分配算法
存储技术
描述
从需求反推设计方案,假如让你设计嵌入式系统的内存管理,你怎么设计?
最简单的,用一个双链表控制,所有已分配和未分配的内存用两个双链表标志:
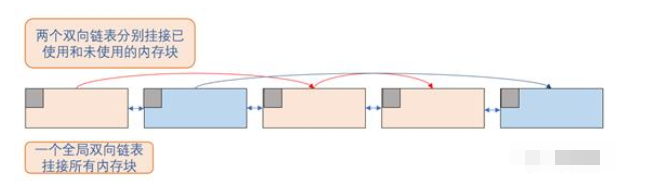
单链表查询时间复杂度不稳定,当空闲块个数为n时,搜索复杂度在O(n)级别。而对内存块大小进行分类,采用分级空闲块链表可以优化空闲块检索的复杂度查询复杂度大概降到O(log(n))级别。
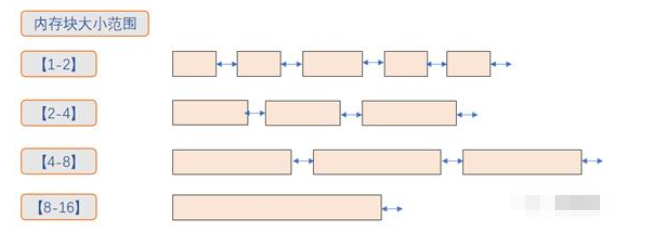
以2的等次幂划分大小可以使用位运算方便计算区间。另外可以根据系统的具体使用场景,如小内存分配比较多,可以在小内存大小上进行细粒度划分,而大内存粗粒度。
分块方式有了,那么如何按照内存大小进行分级呢,这就得用到位图bitmap了。
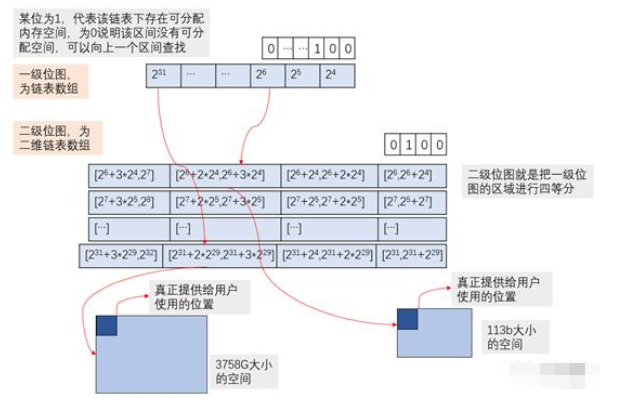
ucos系统的TLSF分配算法采用两级位图来管理空闲空间,第一级位图表示粗粒度范围,假定内存最低从2^4(16字节)大小分配,那么第一个位可以管理16~32字节区间。如果不使用超过64k大小空间,一般到2^15就够了。
第二级位图是个二维链表数组,将一级位图的每个区间等分成四个区间(也可细化为8、16个区间)。
第三部分才是真正的可分配内存。注意,每块可分配内存首部都有个固定的头部,用于记录该块的具体信息,实际返回给用户的指针是加上了头部偏移的。
分配流程
在位图中搜索合适的空闲块大小范围,找到freelist头指针;基于头指针检索list分配空闲块并交给用户。
具体点,比如我需要分配113字节大小内存,怎么知道对应的一二级索引值呢?
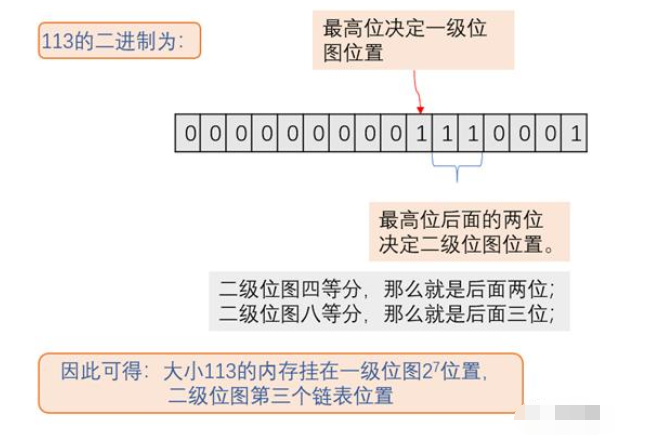
根据二进制最高位找到一级位图位置,根据后面两位找到二级位图位置。
这是最基础的思路,因为仍然需要查找二级位图上挂载的链表,时间复杂度仍然为Ologn。一种优化方法是通过允许少量碎片换取O1的时间复杂度。仍以113大小为例,不是搜索【64,128】这个区间,而是向上大一个区间,从【128,256】这个区间内搜索,好处是该区间每一块内存块都满足需求,直接找到最小的即可。
释放流程
将需要释放的内存块标记为空闲内存,然后查找与前后相邻的空闲块合并,将合并后的空闲内存挂在位图数组里。这里可以看到释放时需要确认前后内存块是否空闲,这个信息保存在首部,具体内存块设计方法如下图:
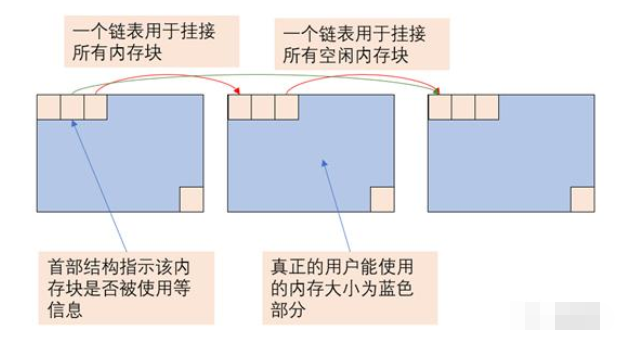
结合前面任务调度的分析,可以看到位图和链表数组就能够实现基本的嵌入式操作系统功能了。
嵌入式系统中使用位图的优势比较显著:
节省存储空间:用1bit来表示某个区间范围大小的空闲块是否存在;
位操作速度快:部分体系结构有加速特殊位操作的汇编指令如CLZ指令,编译器对位操作优化比较深。
Java技术栈的同学对链表数组的优势比较了解,hashmap就是链表数组+红黑树的构造。
另外需要注意,所有起始地址都需要四字节对齐。
这里所说的内存分配都是用户态的,那么内存初始化时起始地址和内存大小如何确定呢?起始地址就是HEAP_ADDR_START,内存大小就是heap大小。这个就涉及到程序对于嵌入式系统空间与地址分配了。详情参考前文:代码是如何编译成程序的??可以先学习简单的连接脚本,感兴趣的参考《程序员的自我修养—链接、装载与库》第4.6节链接过程控制。不考虑可执行文件从flash到RAM的搬运,大致空间分配如下图:
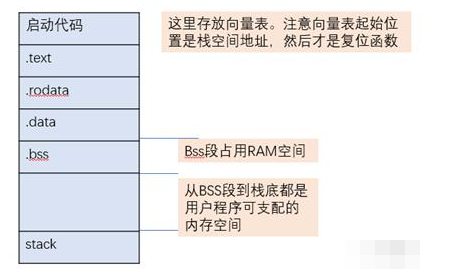
因此在连接脚本中BSS段末尾和stack底部地址就决定了用户态内存的位置和大小。
责任编辑人:CC
-
Linux内核内存管理之ZONE内存分配器2024-02-21 2143
-
如何高效管理MCU内存? 多种分配算法对比?2023-10-17 2347
-
关于RTT支持的内存分配算法2023-04-27 2486
-
Linux内核引导内存分配器的原理2023-04-03 917
-
C语言既然可以自动为变量分配内存,为什么还要用动态分配内存呢?2022-12-13 1559
-
cosmic编译内存分配插件2022-09-07 726
-
什么是堆内存?堆内存是如何分配的?2021-07-05 11218
-
Linux操作系统知识讲解:走进Linux 内存分配算法2020-08-28 6349
-
Linux内存系统: Linux 内存分配算法2020-08-24 42346
-
详解String对象的内存分配2020-07-01 3066
-
UCOS扩展例程-UCOSIII内存管理2016-12-14 1138
-
uCOS-III的任务调度算法研究2016-01-13 888
-
V5-807_uCOS-II实验_内存管理2015-11-23 734
-
基于μCOS-II的TLSF动态内存分配算法的应用与仿真2013-09-25 1396
全部0条评论

快来发表一下你的评论吧 !
