

嵌入式机器学习和AI前沿资讯简报
描述
1. STM32 嵌入式机器学习(TinyML)实战教程-01 | 边缘智能实验室
第1部分:总体介绍 在STM32H747I Discovery开发板上,使用机器学习技术,开发机器视觉应用,本教程由ST(意法半导体)官方发布。 边缘智能实验室原创中文字幕,感谢支持。视频中涉及的文档(也可到ST官网下载):
链接:https://pan.baidu.com/s/1K1Dr2vMUZ8UmtVbZHkKAVA
提取码:w41p
2. 为AI而生,打破存储墙,佐治亚理工等提出新型嵌入式无电容DRAM | 机器之心
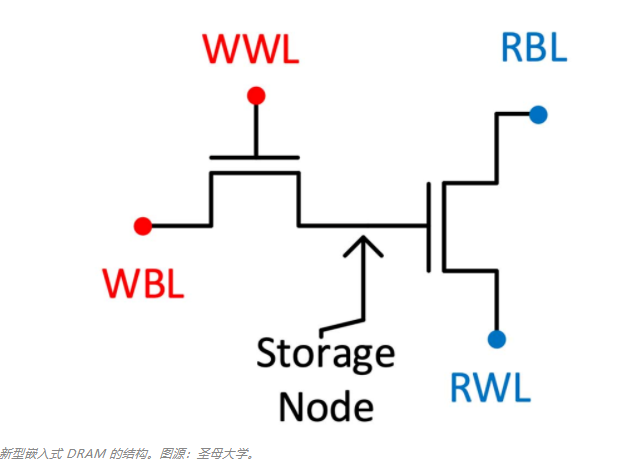
当今计算中最大的问题之一是「存储墙」,即处理时间与将数据从单独的 DRAM 存储器芯片传送到处理器所花费时间之间的差距。AI 应用的日益普及只会加剧该问题,因为涉及面部识别、语音理解、消费商品推荐的巨大网络很少能容纳在处理器的板载内存上。 在 2020 年 12 月举行的 IEEE 国际电子设备会议(IEDM)上,一些研究小组认为:一种新型的 DRAM 可能成为「存储墙」问题的解决方案。他们表示:「这种新型的 DRAM 由氧化物半导体制成,并内置在处理器上方的各层中,其位长是商用 DRAM 的数百或数千倍,并且在运行大型神经网络时可以提供较大的区域,节省大量能源。」 新型嵌入式 DRAM 仅由两个晶体管制成,没有电容器,简称为 2T0C。之所以可以这样做,是因为晶体管的栅极是天然的电容器(尽管有些小)。因此代表该位的电荷可以存储在此处。该设计具有一些关键优势,特别是对于 AI 来说。
原文链接:https://spectrum.ieee.org/tech-talk/semiconductors/memory/new-type-of-dram-could-accelerate-ai
3. 明年,我要用 AI 给全村写对联 | HyperAI超神经
春节接近尾声,你是否还沉浸在年味里? 年前的腊月二十九、三十,家家户户都要开始贴春联了。今年,各种 AI 写春联应用都纷纷上线,帮大家写春联,要不来试试? 对联对联,讲究的就是「成对」,要对仗工整,平仄协调。不过现代人的对对联技能,已经远不如古代的文人墨客,甚至有时候可能连上下联都傻傻分不清楚。而聪明的 AI 已经学会自己写对联了。
测试地址:
https://ai.binwang.me/couplet/
Github:
https://github.com/wb14123/couplet-dataset
数据集地址:
https://hyper.ai/datasets/14547
4. DeepMind最新研究NFNet:抛弃归一化,深度学习模型准确率却达到了前所未有的水平 | 机器之心
Paper:
https://arxiv.org/abs/2102.06171
DeepMind 还放出了模型的实现:
https://github.com/deepmind/deepmind-research/tree/master/nfnets
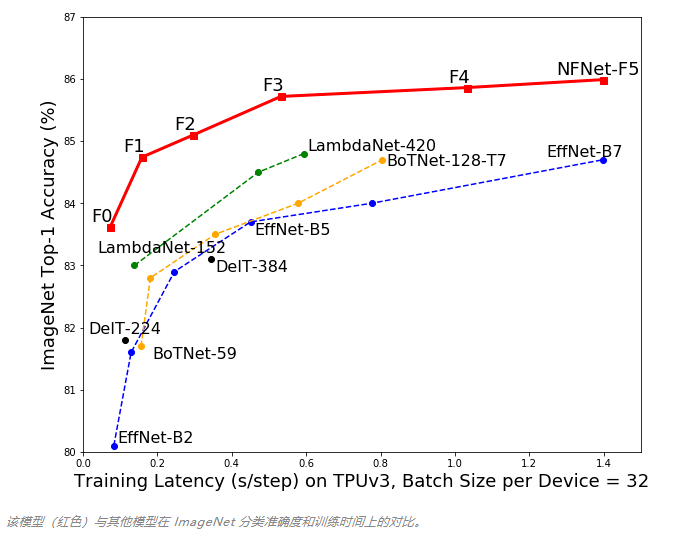
我们知道,在传递给机器学习模型的数据中,我们需要对数据进行归一化(normalization)处理。 在数据归一化之后,数据被「拍扁」到统一的区间内,输出范围被缩小至 0 到 1 之间。人们通常认为经过如此的操作,最优解的寻找过程明显会变得平缓,模型更容易正确的收敛到最佳水平。 然而这样的「刻板印象」最近受到了挑战,DeepMind 的研究人员提出了一种不需要归一化的深度学习模型 NFNet,其在大型图像分类任务上却又实现了业内最佳水平(SOTA)。 该论文的第一作者,DeepMind 研究科学家 Andrew Brock 表示:「我们专注于开发可快速训练的高性能体系架构,已经展示了一种简单的技术(自适应梯度裁剪,AGC),让我们可以训练大批量和大规模数据增强后的训练,同时达到 SOTA 水平。」
5. 在游戏里还原自己的脸,给AI一张照片就行,网易&密歇根大学出品 | AAAI 2021 开源 | 量子位
论文地址:
https://arxiv.org/abs/2102.02371
GitHub地址:
https://github.com/FuxiCV/MeInGame
给AI一张毛不易的照片,它自动就能生成一个古风毛大侠。
现在,想在游戏里定制化自己的脸,你可以不用自己花时间琢磨参数了。 熟悉游戏的小伙伴可能认出来了,这一套AI捏脸术,来自网易伏羲人工智能实验室和密歇根大学。 现在,最新相关研究登上了AAAI 2021。 据作者介绍,这个名为MeInGame的方法,可以集成到大多数现有的3D游戏中,并且相比于单纯基于3DMM(3D Morphable Face Model )的方法,成本更低,泛化性能更好。
6. 谷歌开源计算框架JAX:比Numpy快30倍,还可在TPU上运行! | 新智元
Github:
https://github.com/google/jax
快速入门链接:
https://jax.readthedocs.io/en/latest/notebooks/quickstart.html
相信大家对numpy, Tensorflow, Pytorch已经极其熟悉,不过,你知道JAX吗? JAX发布之后,有网友进行了测试,发现,使用JAX,Numpy运算可以快三十多倍!下面是使用Numpy的运行情况:
1import numpy as np # 使用标准numpy,运算将在CPU上执行。 2x = np.random.random([5000, 5000]).astype(np.float32) 3%timeit np.matmul(x, x)
运行结果:
1 loop, best of 3: 3.9 s per loop
而下面是使用JAX的Numpy的情况:
1import jax.numpy as np # 使用"JAX版"的numpy 2from jax import random # 注意JAX下随机数API有所不同 3x = random.uniform(random.PRNGKey(0), [5000, 5000]) 4%timeit np.matmul(x, x)
运行情况:
1 loop, best of 3: 109 ms per loop
我们可以发现,使用原始numpy,运行时间大概为3.9s,而使用JAX的numpy,运行时间仅仅只有0.109s,速度上直接提升了三十多倍! 那JAX到底是什么? JAX是谷歌开源的、可以在CPU、GPU和TPU上运行的numpy,是针对机器学习研究的高性能自微分计算框架。简单来说,就是GPU和TPU加速、支持自动微分(autodiff)的numpy。
7. 大年初四,宜学习:MIT 6.S191视频、PPT上新!网友:这是最好的深度学习入门课之一 | 机器之心
课程主页:http://introtodeeplearning.com/
原文标题:【20210219期AI简报】嵌入式机器学习(TinyML)实战教程、谷歌开源计算框架JAX...
文章出处:【微信公众号:RTThread物联网操作系统】欢迎添加关注!文章转载请注明出处。
-
嵌入式机器学习的应用特性与软件开发环境2025-01-25 1926
-
2013 ARM 嵌入式应用 研讨会 简报2023-03-01 615
-
Codecraft:嵌入式机器学习的图形化编程2022-11-08 2098
-
嵌入式学习路线怎么学?如何学习嵌入式系统?2022-10-30 2674
-
嵌入式人工智能学习路线2022-09-16 4545
-
嵌入式结合机器学习文章分享2021-12-20 1152
-
嵌入式学习路线怎么学,如何学习嵌入式系统2021-10-20 1425
-
为什么需要嵌入式AI?2021-01-22 2366
-
三大厂商推出AI嵌入式视觉入门套件,用于计算机视觉和机器学习设计2020-03-11 4670
-
由Qeexo嵌入式机器提供的AI亮相于边缘设备2019-08-20 1212
-
嵌入式的定义和举例分析2019-02-11 2077
-
嵌入式学习路线怎么学 如何学习嵌入式系统2018-11-21 10463
-
[学习嵌入式]嵌入式系统学习方法,轻松入门嵌入式2016-03-28 1369
-
嵌入式系统的知识学习及误区2011-11-03 2289
全部0条评论

快来发表一下你的评论吧 !
