

一种可以编码局部信息的结构T2T module,并证明了T2T的有效性
描述
深度学习实战
前面提到过ViT,但是ViT在数据量不够巨大的情况下是打不过ResNet的。于是ViT的升级版T2T-ViT横空出世了,速度更快性能更强。T2T-ViT相比于ViT,参数量和MACs(Multi-Adds)减少了200%,性能在ImageNet上又有2.5%的提升。T2T-ViT在和ResNet50模型大小差不多的情况下,在ImageNet上达到了80.7%的准确率。论文的贡献:
证明了通过精心设计的Transformer-based的网络(T2T module and efficient backbone),是可以打败CNN-based的模型的,而且不需要在巨型的训练集(如JFT-300M)上预训练。
提出了一种可以编码局部信息的结构T2T module,并证明了T2T的有效性。
展示了在设计CNNs backbone时用到的architecture engineering经验同样适用于设计Transformer-based的模型,通过大量的实验证明深且窄(deep-narrow)的网络能够增加feature的丰富性和减少冗余。
Why T2T-ViT?
先来说下ViT[1],ViT在从头开始训练(trained from scratch) ImageNet时,效果甚至比CNN-based的模型还差。这显然是不能让人足够满意的,文中分析了两点原因:
(1)由于ViT是采用对原图像分块,然后做Linear Projection得到embedding。但是通过实验发现,这种基于原图像的简单tokenization并没有很好地学到图像的边缘或者线条这种低级特征,导致ViT算法的学习效率不高,难以训练,因此ViT需要大量的数据进行训练。
(2)在有限的计算资源和有限的数据的情况下,ViT冗余的attention主干网络难以学得丰富的特征。
所以为了克服这些限制,提出了Tokens-To-Token Vision Transformers(T2T-Vit)。为了证明上面的结论,还做了一个实验,可视化了ResNet、ViT和T2T-ViT所学到的特征的差异。
绿色的框中表示了模型学到的一些诸如边缘和线条的low-level structure feature,红色框则表示模型学到了不合理的feature map,这些feature或者接近于0,或者是很大的值。从这个实验可以进一步证实,CNN会从图像的低级特征学起,这个在生物上是说得通的,但是通过可视化来看,ViT的问题确实不小,且不看ViT有没有学到低级的特征,后面的网络层的feature map甚至出现了异常值,这个是有可能导致错误的预测的,同时反映了ViT的学习效率差。 Tokens-to-Token:Progressive Tokenization
为了解决ViT的问题,提出了一种渐进的tokenization去整合相邻的tokens,从tokens到token,这种做法不仅可以对局部信息的建模还能减小token序列的长度。整个T2T的操作分为两个部分:重构(re-structurization)和软划分(soft split)。(1)Re-structurization假设上一个网络层的输出为T,T经过Transformer层得到T',Transformer是包括mutil-head self-attention和MLP的,因此从T到T'可以表示为T' = MLP(MSA(T)),这里MSA表示mutil-head self-attention,MLP表示多层感知机,上述两个操作后面都省略了LN。经过Transformer层后输出也是token的序列,为了重构局部的信息,首先把它还原为原来的空间结构,即从一维reshape为二维,记作I。I = Reshape(T'),reshape操作就完成了从一维的向量到二维的重排列。整个操作可以参见上图的step1。(2)Soft Split与ViT那种hard split不同,T2T-ViT采用了soft split,说直白点就是不同的分割部分会有overlapping。I会被split为多个patch,然后每个patch里面的tokens会拼接成一个token,也就是这篇论文的题目tokens to token,这个步骤也是最关键的一个步骤,因为这个步骤从图像中相邻位置的语义信息聚合到一个向量里面。同时这个步骤会使tokens序列变短,单个token的长度会变长,符合CNN-based模型设计的经验deep-narrow。 T2T module
在T2T模块中,依次通过Re-structurization和Soft Split操作,会逐渐使tokens的序列变短。整个T2T模块的操作可以表示如下:
由于是soft split所以tokens的序列长度会比ViT大很多,MACs和内存占用都很大,因此对于T2T模块来说,只能减小通道数,这里的通道数可以理解为embedding的维度,还使用了Performer[2]来进一步减少内存的占用。 Backbone
为了增加特征的丰富性和减少冗余,需要探索一个更有效的backbone。从DenseNet、Wide-ResNets、SENet、ResNeXt和GhostNet寻找设计的灵感,最终发现:(1)在原ViT的网络结构上采用deep-narrow的原则,增加网络的深度,减小token的维度,可以在缩小模型参数量的同时提升性能。(2)使用SENet[3]中的channel attention对ViT会有提升,但是在使用deep-narrow的结构下提升很小。 Architecture
T2T-ViT由T2T module和T2T-ViT backbone组成。PE是position embedding。对于T2T-ViT-14来说,由14个transformer layers组成,backbone中的hidden dimensions是384。对比ViT-B/16,ViT-B/16有12个transformer layers,hidden dimensions是768,模型大小和MACs是T2T-ViT-14整整三倍。 Experiments
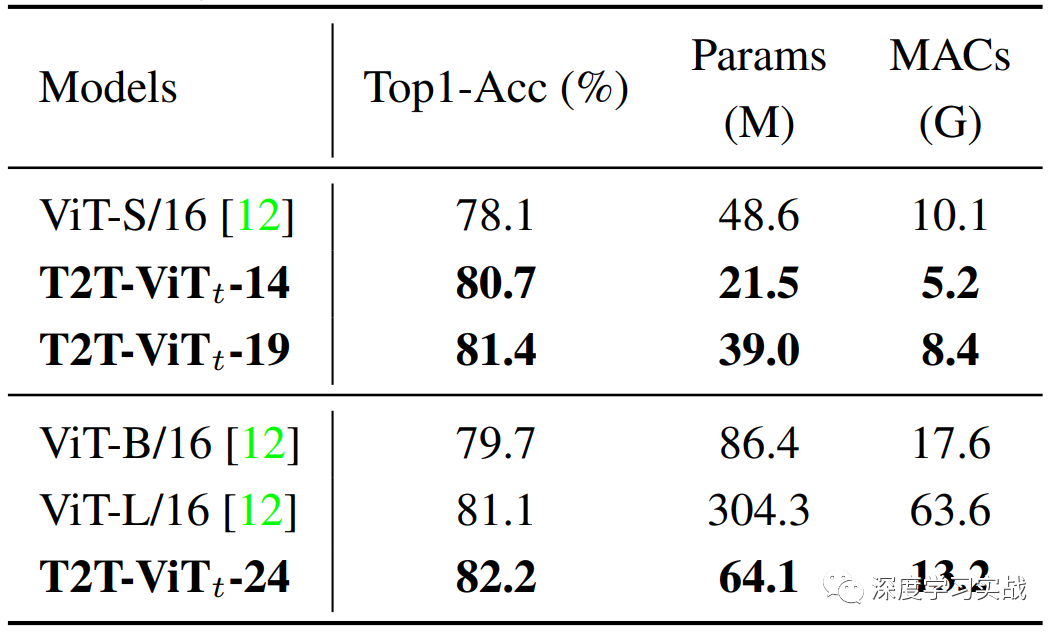
在不使用预训练时,T2T-ViT和ViT的对比,可以看到T2T-ViT真的是完胜ViT啊,不仅模型比你小,精度还比你高。
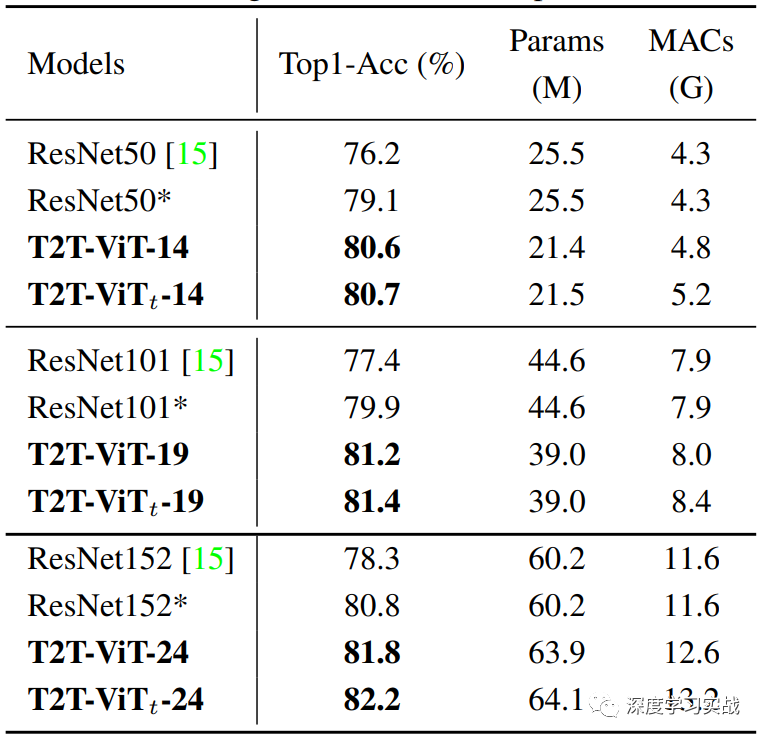
不仅完胜ViT,ResNet也不在话下,说实话看到这个结果的时候真的可以说Transformer战胜了CNN了。 Conclusion
T2T-ViT通过重构图像的结构性信息,克服了ViT的短板,真正意义上击败了CNN。通过提出tokens-to-token的process,逐渐聚合周围的token,增强局部性信息。这篇论文中不仅探索了Transformer-based的网络结构的设计,证明了在Transformer-based模型中deep-narrow要好于shallow-wide,还取得了很好的性能表现。 Reference
[1] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020. [2] K. Choromanski, V. Likhosherstov, D. Dohan, X. Song, A. Gane, T. Sarlos, P. Hawkins, J. Davis, A. Mohiuddin, L. Kaiser, et al. Rethinking attention with performers. arXiv preprint arXiv:2009.14794, 2020. [3] Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 7132-7141.
责任编辑:lq
-
通过特定方法验证T2PAK封装散热设计的有效性2026-02-25 1840
-
探索 KIT_T2G-B-E_LITE 评估套件:开启 TRAVEO™ T2G 开发之旅2025-12-19 1276
-
M30850T2-EPBM 用户手册(MCU Board for Replacing M30850T2-EPB, M30850T3-CPE and M30850T2-CPE)2023-05-04 440
-
如何读取NFC-A T2T卡内存块?2023-02-03 515
-
RZ/T2M 组 RZ/T2M Motor Solution Kit Startup 手册(for RZ/T2M Motion Control Utility)2023-01-10 636
-
怎样使用NFC读卡器读取T2T标签呢2022-12-23 632
-
XC7A100T-2FGG676I 芯片详细信息浅谈2021-11-29 7214
-
什么是欺诈证明和有效性证明2019-01-28 3000
-
基于电网的T2考核标准2017-12-26 775
-
NanoPC-T22016-02-03 7216
-
一种符合ITU-T指标要求的嵌入式立体声语音频编码方法2011-03-09 1879
全部0条评论

快来发表一下你的评论吧 !
