

详解Tutorial代码的学习过程与准备
描述
导读:本文主要解析Pytorch Tutorial中BiLSTM_CRF代码,几乎注释了每行代码,希望本文能够帮助大家理解这个tutorial,除此之外借助代码和图解也对理解条件随机场(CRF)会有一定帮助,因为这个tutorial代码主要还是在实现CRF部分。
1 知识准备
在阅读tutorial前,需具备一些理论或知识基础,包括LSTM单元、BiLSTM-CRF模型、CRF原理以及一些代码中的函数使用,参考资料中涵盖了主要的涉及知识,可配合tutorial一同学习。
2 理解CRF中归一化因子Z(x)的计算
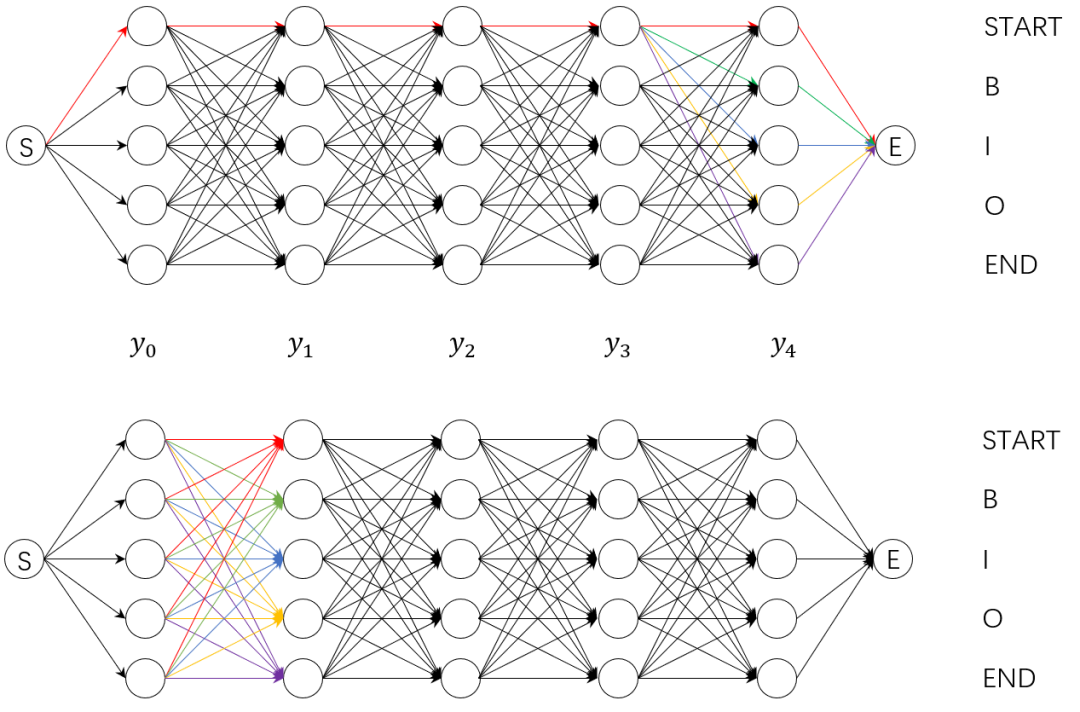
条件随机场中的Z(x)表示归一化因子,它是一个句子所有可能标记tag序列路径的得分总和。一般的,我们会有一个直接的想法,就是列举出所有可能的路径,计算出每条路径的得分之后再加和。如上图中的例子所示,有5个字符和5个tag,如果按照上述的暴力穷举法进行计算,就有种路径组合,而在我们的实际工作中,可能会有更长的序列和更多的tag标签,此时暴力穷举法未免显得有些效率低下。于是我们考虑采用分数累积的方式进行所有路径得分总和的计算,即先计算出到达的所有路径的总得分,然后计算-》的所有路径的得分,然后依次计算-》。..-》间的所有路径的得分,最后便得到了我们的得分总和,这个思路源于如下等价等式:

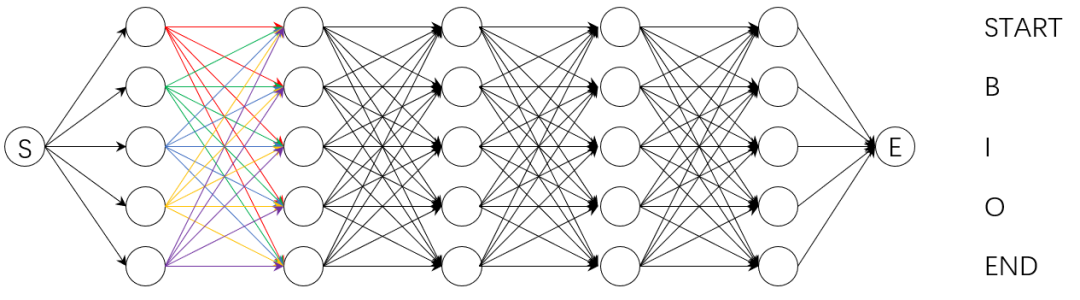
上式相等表明,直接计算整个句子序列的全局分数与计算每一步的路径得分再加和等价,计算每一步的路径得分再加和这种方式可以大大减少计算的时间,故Pytorch Tutorial中的_forward_alg()函数据此实现。这种计算每一步的路径得分再加和的方法还可以以下图方式进行计算。
3 理解CRF中序列解码过程,即viterbi算法
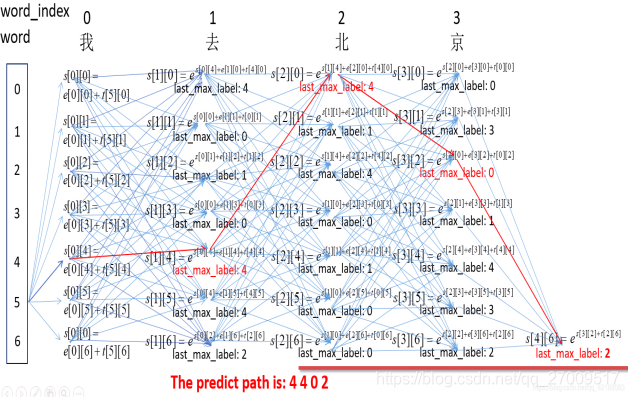
如上图所示,在每个时间步上,比如’word==去‘这一列,每一个tag处(0~6竖框是tag的id),关注两个值:前一个时间步上所有tag到当前tag中总得分最大值以及该最大值对应的前一个时间步上tag的id。这样一来每个tag都记录了它前一个时间步上到自己的最优路径,最后通过tag的id进行回溯,这样就可以得到最终的最优tag标记序列。此部分对应Pytorch Tutorial中的_viterbi_decode()函数实现。
4 理解log_sum_exp()函数
Pytorch Tutorial中的log_sum_exp()函数最后返回的计算方式数学推导如下:
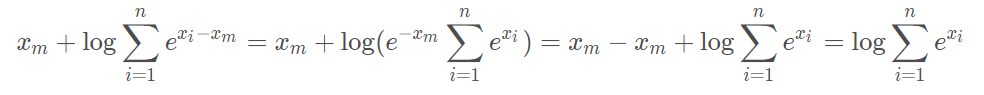
5 Pytorch Tutorial代码部分注释辅助理解
import torch
import torch.nn as nn
import torch.optim as optim
# 人工设定随机种子以保证相同的初始化参数,使模型可复现
torch.manual_seed(1)
# 得到每行最大值索引idx
def argmax(vec):
# 得到每行最大值索引idx
_, idx = torch.max(vec, 1)
# 返回每行最大值位置索引
return idx.item()
# 将序列中的字转化为数字(int)表示
def prepare_sequence(seq, to_ix):
# 将序列中的字转化为数字(int)表示
idx = [to_ix[c] for c in seq]
return torch.tensor(idx, dtype=torch.long)
# 前向算法是不断积累之前的结果,这样就会有个缺点
# 指数和积累到一定程度之后,会超过计算机浮点值的最大值
# 变成inf,这样取log后也是inf
# 为了避免这种情况,用一个合适的值clip=max去提指数和的公因子
# 这样不会使某项变得过大而无法计算
def log_sum_exp(vec):# vec:形似[[tag个元素]]
# 取vec中最大值
max_score = vec[0, argmax(vec)]
# vec.size()[1]:tag数
max_score_broadcast = max_score.view(1, -1).expand(1, vec.size()[1])
# 里面先做减法,减去最大值可以避免e的指数次,计算机上溢
# 等同于torch.log(torch.sum(torch.exp(vec))),防止e的指数导致计算机上溢
return max_score + torch.log(torch.sum(torch.exp(vec - max_score_broadcast)))
class BiLSTM_CRF(nn.Module):
# 初始化参数
def __init__(self, vocab_size, tag_to_ix, embedding_dim, hidden_dim):
super(BiLSTM_CRF, self).__init__()
# 词嵌入维度
self.embedding_dim = embedding_dim
# BiLSTM 隐藏层维度
self.hidden_dim = hidden_dim
# 词典的大小
self.vocab_size = vocab_size
# tag到数字的映射
self.tag_to_ix = tag_to_ix
# tag个数
self.tagset_size = len(tag_to_ix)
# num_embeddings (int):vocab_size 词典的大小
# embedding_dim (int):embedding_dim 嵌入向量的维度,即用多少维来表示一个符号
self.word_embeds = nn.Embedding(vocab_size, embedding_dim)
# input_size: embedding_dim 输入数据的特征维数,通常就是embedding_dim(词向量的维度)
# hidden_size: hidden_dim LSTM中隐藏层的维度
# num_layers:循环神经网络的层数
# 默认使用偏置,默认不用dropout
# bidirectional = True 用双向LSTM
# 设定为单层双向
# 隐藏层设定为指定维度的一半,便于后期拼接
# // 表示整数除法,返回不大于结果的一个最大的整数
self.lstm = nn.LSTM(embedding_dim, hidden_dim // 2,
num_layers=1, bidirectional=True)
# 将BiLSTM提取的特征向量映射到特征空间,即经过全连接得到发射分数
# in_features: hidden_dim 每个输入样本的大小
# out_features:tagset_size 每个输出样本的大小
self.hidden2tag = nn.Linear(hidden_dim, self.tagset_size)
# 转移矩阵的参数初始化,transition[i,j]代表的是从第j个tag转移到第i个tag的转移分数
self.transitions = nn.Parameter(torch.randn(self.tagset_size, self.tagset_size))
# 初始化所有其他tag转移到START_TAG的分数非常小,即不可能由其他tag转移到START_TAG
# 初始化STOP_TAG转移到所有其他的分数非常小,即不可能有STOP_TAG转移到其他tag
# CRF的转移矩阵,T[i,j]表示从j标签转移到i标签,
self.transitions.data[tag_to_ix[START_TAG], :] = -10000
self.transitions.data[:, tag_to_ix[STOP_TAG]] = -10000
# 初始化LSTM的参数
self.hidden = self.init_hidden()
# 使用随机正态分布初始化LSTM的h0和c0
# 否则模型自动初始化为零值,维度为[num_layers*num_directions, batch_size, hidden_dim]
def init_hidden(self):
return (torch.randn(2, 1, self.hidden_dim // 2),
torch.randn(2, 1, self.hidden_dim // 2))
# 计算归一化因子Z(x)
def _forward_alg(self, feats):
‘’‘
输入:发射矩阵(emission score),实际上就是LSTM的输出
sentence的每个word经BiLSTM后对应于每个label的得分
输出:所有可能路径得分之和/归一化因子/配分函数/Z(x)
’‘’
# 通过前向算法递推计算
# 初始化1行 tagset_size列的嵌套列表
init_alphas = torch.full((1, self.tagset_size), -10000.)
# 初始化step 0 即START位置的发射分数,START_TAG取0其他位置取-10000
init_alphas[0][self.tag_to_ix[START_TAG]] = 0.
# 包装到一个变量里面以便自动反向传播
forward_var = init_alphas
# 迭代整个句子
# feats:形似[[。..。], 每个字映射到tag的发射概率,
# [。..。],
# [。..。]]
for feat in feats:
# 存储当前时间步下各tag得分
alphas_t = []
for next_tag in range(self.tagset_size):
# 取出当前tag的发射分数(与之前时间步的tag无关),扩展成tag维
emit_score = feat[next_tag].view(1, -1).expand(1, self.tagset_size)
# 取出当前tag由之前tag转移过来的转移分数
trans_score = self.transitions[next_tag].view(1, -1)
# 当前路径的分数:之前时间步分数+转移分数+发射分数
next_tag_var = forward_var + trans_score + emit_score
# 对当前分数取log-sum-exp
alphas_t.append(log_sum_exp(next_tag_var).view(1))
# 更新forward_var 递推计算下一个时间步
# torch.cat 默认按行添加
forward_var = torch.cat(alphas_t).view(1, -1)
# 考虑最终转移到STOP_TAG
terminal_var = forward_var + self.transitions[self.tag_to_ix[STOP_TAG]]
# 对当前分数取log-sum-exp
scores = log_sum_exp(terminal_var)
return scores
# 通过BiLSTM提取特征
def _get_lstm_features(self, sentence):
# 初始化LSTM的h0和c0
self.hidden = self.init_hidden()
# 使用之前构造的词嵌入为语句中每个词(word_id)生成向量表示
# 并将shape改为[seq_len, 1(batch_size), embedding_dim]
embeds = self.word_embeds(sentence).view(len(sentence), 1, -1)
# LSTM网络根据输入的词向量和初始状态h0和c0
# 计算得到输出结果lstm_out和最后状态hn和cn
lstm_out, self.hidden = self.lstm(embeds, self.hidden)
lstm_out = lstm_out.view(len(sentence), self.hidden_dim)
# 转换为词 - 标签([seq_len, tagset_size])表
# 可以看作为每个词被标注为对应标签的得分情况,即维特比算法中的发射矩阵
lstm_feats = self.hidden2tag(lstm_out)
return lstm_feats
# 计算一个tag序列路径的得分
def _score_sentence(self, feats, tags):
# feats发射分数矩阵
# 计算给定tag序列的分数,即一条路径的分数
score = torch.zeros(1)
# tags前面补上一个句首标签便于计算转移得分
tags = torch.cat([torch.tensor([self.tag_to_ix[START_TAG]], dtype=torch.long), tags])
# 循环用于计算给定tag序列的分数
for i, feat in enumerate(feats):
# 递推计算路径分数:转移分数+发射分数
# T[i,j]表示j转移到i
score = score + self.transitions[tags[i + 1], tags[i]] + feat[tags[i + 1]]
# 加上转移到句尾的得分,便得到了gold_score
score = score + self.transitions[self.tag_to_ix[STOP_TAG], tags[-1]]
return score
# veterbi解码,得到最优tag序列
def _viterbi_decode(self, feats):
‘’‘
:param feats: 发射分数矩阵
’‘’
# 便于之后回溯最优路径
backpointers = []
# 初始化viterbi的forward_var变量
init_vvars = torch.full((1, self.tagset_size), -10000.)
init_vvars[0][self.tag_to_ix[START_TAG]] = 0
# forward_var表示每个标签的前向状态得分,即上一个词被打作每个标签的对应得分值
forward_var = init_vvars
# 遍历每个时间步时的发射分数
for feat in feats:
# 记录当前词对应每个标签的最优转移结点
# 保存当前时间步的回溯指针
bptrs_t = []
# 与bptrs_t对应,记录对应的最优值
# 保存当前时间步的viterbi变量
viterbivars_t = []
# 遍历每个标签,求得当前词被打作每个标签的得分
# 并将其与当前词的发射矩阵feat相加,得到当前状态,即下一个词的前向状态
for next_tag in range(self.tagset_size):
# transitions[next_tag]表示每个标签转移到next_tag的转移得分
# forward_var表示每个标签的前向状态得分,即上一个词被打作每个标签的对应得分值
# 二者相加即得到当前词被打作next_tag的所有可能得分
# 维特比算法记录最优路径时只考虑上一步的分数以及上一步的tag转移到当前tag的转移分数
# 并不取决于当前的tag发射分数
next_tag_var = forward_var + self.transitions[next_tag]
# 得到上一个可能的tag到当前tag中得分最大值的tag位置索引id
best_tag_id = argmax(next_tag_var)
# 将最优tag的位置索引存入bptrs_t
bptrs_t.append(best_tag_id)
# 添加最优tag位置索引对应的值
viterbivars_t.append(next_tag_var[0][best_tag_id].view(1))
# 更新forward_var = 当前词的发射分数feat + 前一个最优tag当前tag的状态下的得分
forward_var = (torch.cat(viterbivars_t) + feat).view(1, -1)
# 回溯指针记录当前时间步各个tag来源前一步的最优tag
backpointers.append(bptrs_t)
# forward_var表示每个标签的前向状态得分
# 加上转移到句尾标签STOP_TAG的转移得分
terminal_var = forward_var + self.transitions[self.tag_to_ix[STOP_TAG]]
# 得到标签STOP_TAG前一个时间步的最优tag位置索引
best_tag_id = argmax(terminal_var)
# 得到标签STOP_TAG当前最优tag对应的分数值
path_score = terminal_var[0][best_tag_id]
# 根据过程中存储的转移路径结点,反推最优转移路径
# 通过回溯指针解码出最优路径
best_path = [best_tag_id]
# best_tag_id作为线头,反向遍历backpointers找到最优路径
for bptrs_t in reversed(backpointers):
best_tag_id = bptrs_t[best_tag_id]
best_path.append(best_tag_id)
# 去除START_TAG
start = best_path.pop()
# 最初的转移结点一定是人为构建的START_TAG,删除,并根据这一点确认路径正确性
assert start == self.tag_to_ix[START_TAG]
# 最后将路径倒序即得到从头开始的最优转移路径best_path
best_path.reverse()
return path_score, best_path
# 损失函数loss
def neg_log_likelihood(self, sentence, tags):
# 得到句子对应的发射分数矩阵
feats = self._get_lstm_features(sentence)
# 通过前向算法得到归一化因子Z(x)
forward_score = self._forward_alg(feats)
# 得到tag序列的路径得分
gold_score = self._score_sentence(feats, tags)
return forward_score - gold_score
# 输入语句序列得到最佳tag路径及其得分
def forward(self, sentence): # dont confuse this with _forward_alg above.
# 从BiLSTM获得发射分数矩阵
lstm_feats = self._get_lstm_features(sentence)
# 使用维特比算法进行解码,计算最佳tag路径及其得分
score, tag_seq = self._viterbi_decode(lstm_feats)
return score, tag_seq
START_TAG = “《START》”
STOP_TAG = “《STOP》”
# 词嵌入维度
EMBEDDING_DIM = 5
# LSTM隐藏层维度
HIDDEN_DIM = 4
# 训练数据
training_data = [(
“the wall street journal reported today that apple corporation made money”.split(),
“B I I I O O O B I O O”.split()
), (
“georgia tech is a university in georgia”.split(),
“B I O O O O B”.split()
)]
word_to_ix = {}
# 构建词索引表,数字化以便计算机处理
for sentence, tags in training_data:
for word in sentence:
if word not in word_to_ix:
word_to_ix[word] = len(word_to_ix)
# 构建标签索引表,数字化以便计算机处理
tag_to_ix = {“B”: 0, “I”: 1, “O”: 2, START_TAG: 3, STOP_TAG: 4}
# 初始化模型参数
model = BiLSTM_CRF(len(word_to_ix), tag_to_ix, EMBEDDING_DIM, HIDDEN_DIM)
# 使用随机梯度下降法(SGD)进行参数优化
# model.parameters()为该实例中可优化的参数,
# lr:学习率,weight_decay:正则化系数,防止模型过拟合
optimizer = optim.SGD(model.parameters(), lr=0.01, weight_decay=1e-4)
# 在no_grad模式下进行前向推断的检测,函数作用是暂时不进行导数的计算,目的在于减少计算量和内存消耗
# 训练前检查模型预测结果
with torch.no_grad():
# 取训练数据中第一条语句序列转化为数字
precheck_sent = prepare_sequence(training_data[0][0], word_to_ix)
# 取训练数据中第一条语句序列对应的标签序列进行数字化
precheck_tags = torch.tensor([tag_to_ix[t] for t in training_data[0][1]], dtype=torch.long)
print(model(precheck_sent))
# 300轮迭代训练
for epoch in range(300):
for sentence, tags in training_data:
# Step 1. 每次开始前将上一轮的参数梯度清零,防止累加影响
model.zero_grad()
# Step 2. seq、tags分别数字化为sentence_in、targets
sentence_in = prepare_sequence(sentence, word_to_ix)
targets = torch.tensor([tag_to_ix[t] for t in tags], dtype=torch.long)
# Step 3. 损失函数loss
loss = model.neg_log_likelihood(sentence_in, targets)
# Step 4. 通过调用optimizer.step()计算损失、梯度、更新参数
loss.backward()
optimizer.step()
# torch.no_grad() 是一个上下文管理器,被该语句 wrap 起来的部分将不会track 梯度
# 训练结束查看模型预测结果,对比观察模型是否学到
with torch.no_grad():
precheck_sent = prepare_sequence(training_data[0][0], word_to_ix)
print(model(precheck_sent))
# We got it!
欢迎交流指正
参考资料:
[1]torch.max()使用讲解
https://www.jianshu.com/p/3ed11362b54f
[2]torch.manual_seed()用法
https://www.cnblogs.com/dychen/p/13920000.html
[3]BiLSTM-CRF原理介绍+Pytorch_Tutorial代码解析
https://blog.csdn.net/misite_j/article/details/109036725
[4]关于nn.embedding函数的理解
https://blog.csdn.net/a845717607/article/details/104752736
[5]torch.nn.LSTM()详解
https://blog.csdn.net/m0_45478865/article/details/104455978
[6]pytorch函数之nn.Linear
https://www.cnblogs.com/Archer-Fang/p/10645473.html
[7]pytorch之torch.randn()
https://blog.csdn.net/zouxiaolv/article/details/99568414
[8]torch.full()
https://blog.csdn.net/Fluid_ray/article/details/109855155
[9]PyTorch中view的用法
https://blog.csdn.net/york1996/article/details/81949843
https://blog.csdn.net/zkq_1986/article/details/100319146
[10]torch.cat()函数
https://blog.csdn.net/xinjieyuan/article/details/105208352
[11]ADVANCED: MAKING DYNAMIC DECISIONS AND THE BI-LSTM CRF
https://pytorch.org/tutorials/beginner/nlp/advanced_tutorial.html
[12]条件随机场理论理解
https://blog.csdn.net/qq_27009517/article/details/107154441
[13]PyTorch tutorial - BiLSTM CRF 代码解析
https://blog.csdn.net/ono_online/article/details/105089750
编辑:lyn
-
深度学习模型训练过程详解2024-07-01 4678
-
[源代码]Python算法详解2023-06-06 751
-
STM32 SPI NRF24L01代码详解学习总结2021-12-16 1288
-
单片机学习前准备2021-11-26 747
-
学习单片机之前需要哪些准备?2021-11-14 1195
-
详解MCU的运行过程2021-11-03 1935
-
通力电梯故障代码详解2021-09-06 3875
-
HiveSQL实现过程的原理详解2019-06-04 2105
-
FPGA学习中的代码阅读浅析2019-03-25 1388
-
XPT2046触摸屏实验过程详解与STM32代码解析2017-12-23 26964
-
如何做好嵌入式Linux学习前的准备2017-06-19 1735
-
PICC学习资料2017-06-02 906
-
电子DIY过程详解2011-08-05 27343
全部0条评论

快来发表一下你的评论吧 !
