

Transformer模型的多模态学习应用
描述
导读
随着Transformer在视觉中的崛起,Transformer在多模态中应用也是合情合理的事情,甚至以后可能会有更多的类似的paper。先来解释一下什么多模态,模态译作modality,多模态译作multimodel。多模态学习主要有一下几个方向:表征、转化、对齐、融合和协同学习。人就是生活在一个多模态的世界里面,文字、视觉、语言都是不同的模态,当我们能够同时从视觉、听觉、嗅觉等等来识别当前发生的事情,实际上我们就是在做了多模态的融合。而Transformer is All You Need这篇论文(从Attention is All You Need开始大家都成了标题党,X is All You Need)是属于协同学习(Co-learning)的范畴,将多个不同的tasks一起训练,共享模型参数。

背景介绍
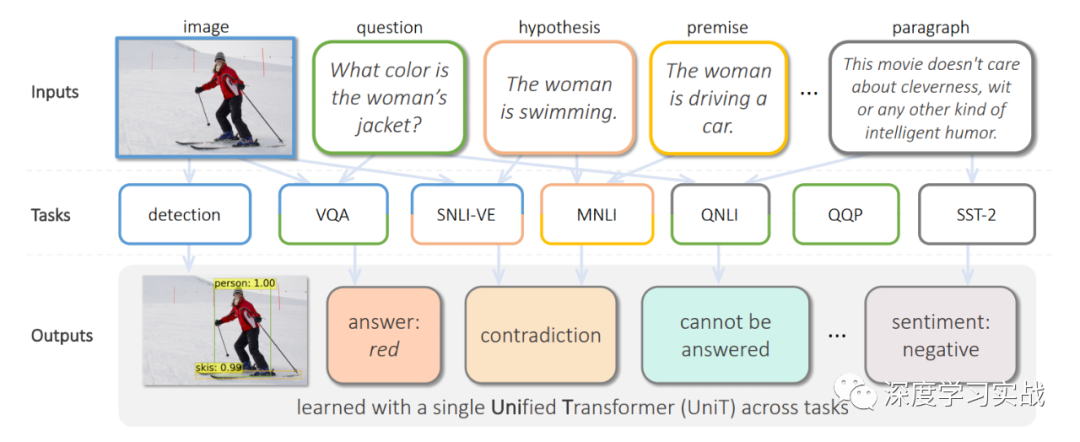
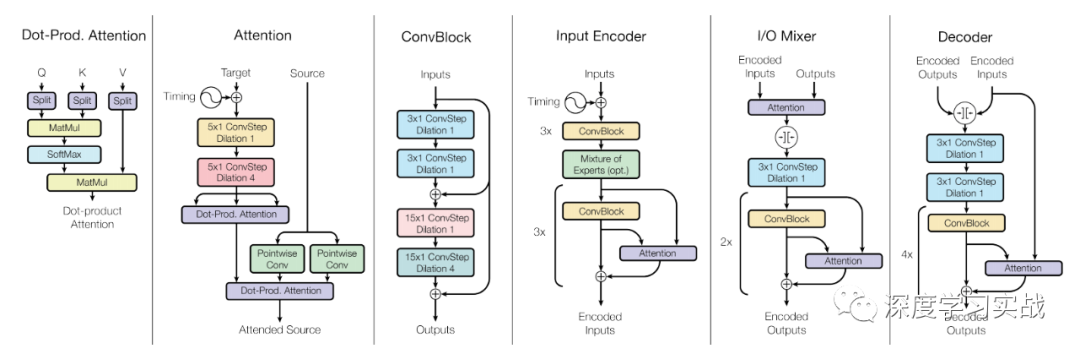
这篇论文出自Facebook AI Research,文章提出了UniT,Unified Transformer model,用一个Transformer模型去同时学习多个不同的tasks,甚至这些tasks的领域都可能不同,从目标检测到语言理解,一共训练了7个tasks8个datasets,但是各个beachmark上都取得了不错的成绩。Transformer在各种不同的领域中都取得了极大的成功,例如NLP、images、video和audio,不仅在以上领域表现出色,甚至在一些vision-and-language reasoning的tasks上,比如VQA(visual question answering)也有很强的表现。但是现有的一些多模态的模型基本都是关注某一个领域的不同task或者就是用将近N倍的参数去处理N个不同的领域问题。在17年谷歌提出的《One Model To Learn Them All》[1]中也使用了Transformer encoder-decoder的架构,但是不同的是,它对于每个task都需要一个与之对应的decoder,如下图。类似的还有MT-DNN[2]和VILBERT-MT[3]等等。
UniT: One transformer to learn them all
用单个模型去训练跨模态的任务,UniT包括对于不同的task对于的encoder,因为不同模态的数据需要经过处理才能放到同一个网络,就和人获得不同模态的信息需要不同的器官一样。然后这些信息会经过一个共享decoder,最后各个task会有对应的简单的head进行最后的输出。UniT有两种不同模态的输入:图像和文本。也就是说只需要两个对应的encoder就可以训练7种不同的任务,可以形象地比喻这个网络有两个不同的器官(Image encoder和Text encoder)。
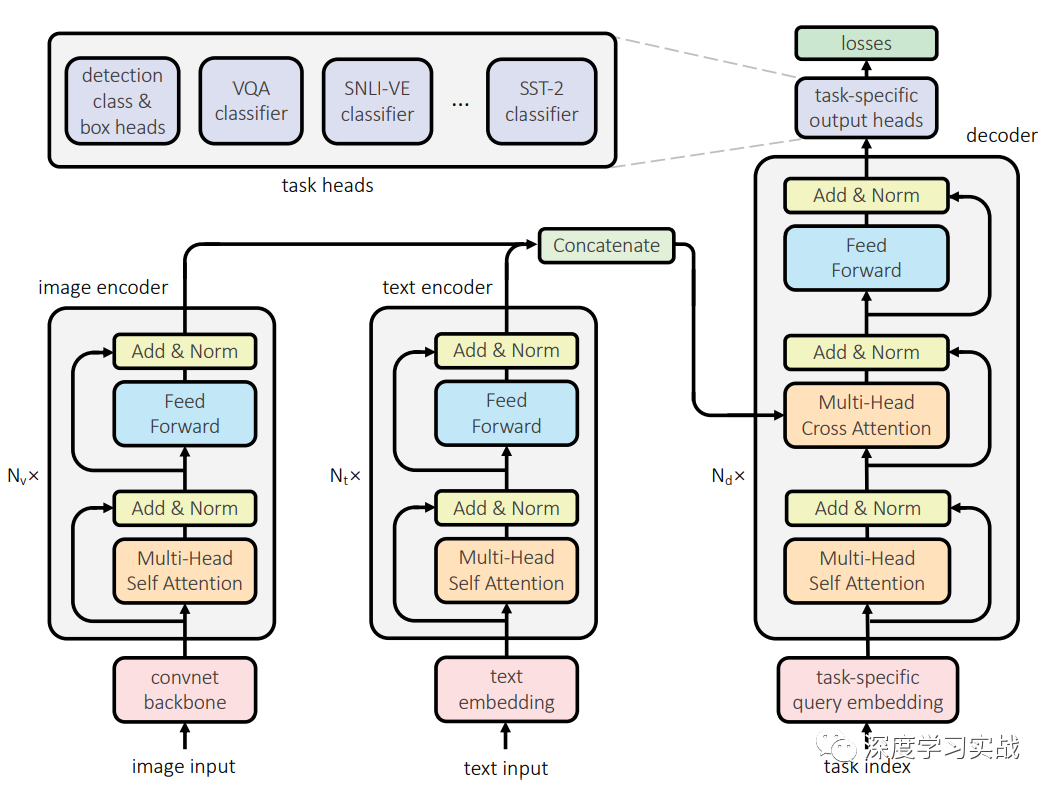
Image encoder一些视觉相关的task,比如目标检测、视觉问答等都需要处理图像,在UniT中,图像先经过一个卷积的backbone,然后再用transformer对特征进行编码,进一步得到编码后的向量。图像的处理与DETR[4]类似。xv=B(I),xv是经过卷积神经网络B得到的特征图,B采用了ResNet-50,并在C5中使用了空洞卷积。再用encoder Ev得到图像编码的向量,这里使用encoder进行编码时为了区别不同的task加入了task embedding以进行区分,和IPT中的作法类似,因为不同的task它可能关注的点不一样。
Text encoder对于文本的输入,采用BERT来进行编码,BERT是一个在大规模语料库上预训练好的模型。给定输入的文本,和BERT处理一样,先将文本编码成tokens的序列{w1, · · · , wS},和image encoder一样,还需要加入一个wtask来区分不同的task。在实现中,采用了embedding维度是768,12层的BERT。
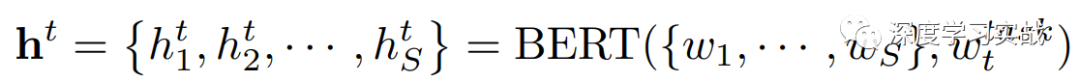
Domain-agnostic UniT decoder领域不可知的解码器,和image和text encoder不一样的是encoder是针对某一特定领域的,但是encoder的输入可以是来自与image encoder或者是text encoder,所以是领域不可知。对于纯视觉、纯文本和视觉文本混合的task,encoder的输入是不一样的,纯视觉和纯文本的task的情况下,decoder的输入就是它们各自encoder的输出,但是对于视觉文本的task,decoder的输入是两个encoder输出的拼接,这很好理解,因为需要VQA这种同时会有image和text的输入。
Task-specific output heads每个task可能最后的输出差别很大,因此最后使用对应的prediction head来进行最后的预测。对于检测任务来说,最后decoder产生的每个向量都会produce一个输出,输出包括类别和bounding box。当然,对于不同的task,decoder输入的query是不同的。
Experiments
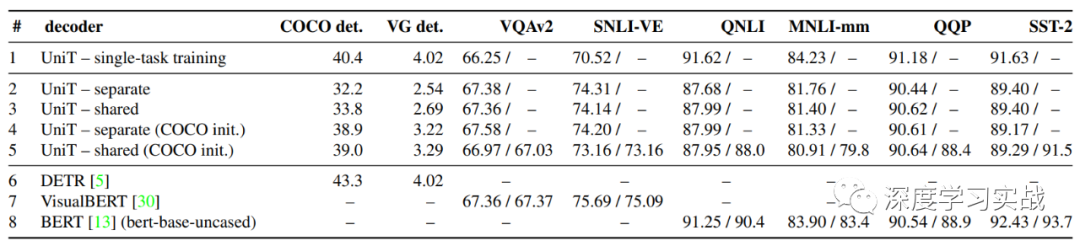
下图是所用到的8个不同的数据集以及上面的测试结果,可以看到不同任务的区别还是很大的。
根据下图的对比,其实UniT有些task离SOTA还是差的有点远,所以这个领域还是有很大的挖掘的空间的。
Conclusion
在这篇论文中,我们可以看到,Transformer确实是可以来处理不同的领域的,跨领域学习确实是个很大的难题,那么Transformer能否成为多模态领域发展的一个跳板呢?我们拭目以待。
Reference论文链接:https://arxiv.org/abs/2102.10772
编辑:lyn
- 相关推荐
- 热点推荐
- 视觉
- paper
- Transformer
-
《多模态大模型 前沿算法与实战应用 第一季》精品课程简介2026-05-01 180
-
基于多模态特征数据的多标记迁移学习方法的早期阿尔茨海默病诊断2017-12-14 1044
-
如何让Transformer在多种模态下处理不同领域的广泛应用?2021-03-08 3532
-
基于层次注意力机制的多模态围堵情感识别模型2021-04-01 1200
-
简述文本与图像领域的多模态学习有关问题2021-08-26 7902
-
VisCPM:迈向多语言多模态大模型时代2023-07-10 1552
-
更强更通用:智源「悟道3.0」Emu多模态大模型开源,在多模态序列中「补全一切」2023-07-16 1673
-
基于Transformer多模态先导性工作2023-08-21 1787
-
北大&华为提出:多模态基础大模型的高效微调2023-11-08 2612
-
探究编辑多模态大语言模型的可行性2023-11-09 1177
-
大模型+多模态的3种实现方法2023-12-13 3535
-
利用OpenVINO部署Qwen2多模态模型2024-10-18 3135
-
商汤日日新多模态大模型权威评测第一2024-12-20 1936
-
自动驾驶中Transformer大模型会取代深度学习吗?2025-08-13 4494
-
亚马逊云科技上线Amazon Nova多模态嵌入模型2025-10-29 465
全部0条评论

快来发表一下你的评论吧 !
