

全面概述ARM Mali GPU架构演进!
描述
年初有机会调研了一下历代ARM Mali GPU架构,目前一共四代【1】,分别是Utgard,Midgard,Bifrost和Valhall。有感于他的演进是大GPU架构发展的缩影,所以作文一篇记录心得。我不打算逐一介绍各代架构的细节,而是针对Shader处理器聊一聊每代GPU的发展。对各代架构细节有兴趣或者希望了解全貌的同学可以参考【2】【3】【4】【5】。
Shader处理器
图形API发展到OpenGL 2.0之后,图形处理管线摆脱了之前的固定模式,实现了高度的可定制化。出现了针对图形管线各阶段的Shader,比如Vertex Shader,Fragment Shader,再到后来的Geometry Shader,Tessellation Shader和Compute Shader。每个Shader都是一个用户编写的小程序,执行这些小程序就是GPU中Shader处理器的工作。
Shader处理器作为核心组件,它的架构关系到GPU的性能表现,也是演进最为激烈的部分。每代Mali GPU都会对Shader处理器做较大调整以适应图形API和应用的发展。这里着重讨论两个主要变化——统一处理器架构和TLP驱动的架构设计。
从独立到统一
初代的Utgard架构有两种Shader处理器,GP——执行Vertex Shader,PP——执行Fragment Shader。两者采用不同的硬件架构和指令集,所以编译器会将不同的Shader编译成各自Shader处理器的机器码后交由它们分别执行。
Vertex Shader是对每一个顶点执行一次,而Fragment Shader是对每一个像素执行一次,一般情况下Fragment Shader的执行次数会多于Vertex Shader;而且很多图形效果的实现,Fragment Shader都比Vertex Shader更加复杂。所以Utgard是一个GP配上多个PP,比如一个GP配四个PP就是MP4,最高能配到MP8。单个PP的硬件设计也相对GP更加复杂。
这种独立Shader处理器的架构Shader处理器之间算力无法互通,当一种Shader算力需求远大于另一种时,另一种Shader处理器只能干等着无法帮忙,造成利用率下降。而且随着图形API加入新的Shader种类,给每一种Shader设计一种处理器会不断增加软件和硬件的复杂度。但其实这些Shader在纯计算部分几乎是一样的,可以复用大部分的设计,不必每一个Shader都搞一套。
所以从Midgard这一代开始,采用了统一Shader处理器架构。不同种类的Shader共享计算部分作为统一Shader处理器,顶点插值和光栅化这些固定功能操作独立于外。这样每种Shader都能跑满所有的处理器,提高了硬件利用率。
从ILP到TLP
ILP(Instruction Level Parallelism)和TLP(Thread Level Parallelism)都或多或少同时存在于每代的Shader处理器架构中,但是趋势是TLP的比重逐渐加大。
Utgard和Midgard架构下TLP仅限于处理器级别,Shader处理器就像CPU的一个核心,一次运行一个顶点或者像素的Shader,有几个处理器就有几个线程。比如Mali400MP4,有四个PP,可以并行处理四个像素的fragment shader。每个处理器完全采用了ILP的方式着重优化单线程的处理能力。
我们可以从两种架构所使用的VLIW指令【6】一窥ILP的设计。Utgard PP的指令编码可以参见【7】,包含两个向量处理单元、两个标量处理单元、一个函数处理单元,还有负责各类数据加载和执行控制的单元。这种VLIW指令和普通的CPU指令不同,一条指令可以完成多个操作。它对应了硬件上的管线(pipeline)结构,如图一所示。管线是处理器执行指令的一条流水线,可以分成多个阶段(stage)。VLIW指令里的各个操作由这条管线里的各个阶段完成。
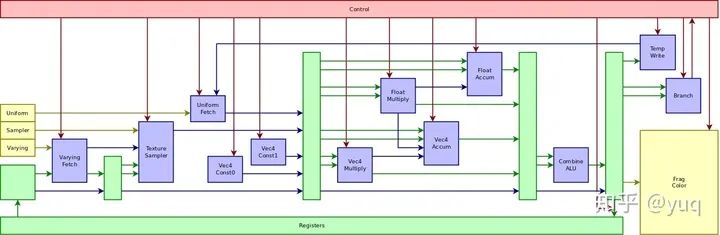
图一:Utgard PP处理器管线【7】
比如这一系列操作:取贴图数据,然后做加法,再做乘法,最后写结果到内存。精简指令集(RISC)一般需要四条指令,每条指令都有各自的取指令,执行,写结果的步骤;但是VLIW可以在一条指令里将这些操作依序串起来,取出的贴图数据不需要写进寄存器文件,直接传给加法单元处理,加法单元的结果也是这样直接传递给乘法单元,最后输出到内存。所以VLIW管线会更长,但是由于略去了操作的中间步骤,整合后更加高效。
普通CPU会通过复杂的硬件设计,动态调度要执行的指令来提高单线程性能,比如并行执行和乱序执行。VLIW却是通过在编译阶段,依靠编译器静态调度各个操作填充到VLIW指令的单元中。所以很多早期的GPU包括桌面和移动的,为了简化硬件降低功耗,都采用VLIW来加强ILP。但是这种设计对编译器要求很高。如何调度Shader里的操作以充分利用一条指令里的所有操作单元决定了硬件的执行效率。当然Shader本身的逻辑也决定了有没有足够可以并行的操作。这些都是ILP发展方向的限制条件。
好在图形计算是一个天生的数据并行良好的邻域——有大量的图元需要计算,而且每个图元的计算可以独立进行,不依赖其他图元。所以每个图元的计算都可以作为一个线程,绘制出一帧画面就是跑完这成千上万个线程的工作。利用大量的线程,获得很多可以并行执行的操作,不用很复杂的调度就能达到很高的硬件利用率,这就是GPU里TLP设计的出发点。
从Bifrost架构开始,ARM在单处理器内部也引入了TLP。方法是将大量线程每4个一组(后来扩展为8、16个),然后一组一组在单个处理器中运行。同组的线程执行相同的指令,类似于SIMD。这样就不需要为每个线程都准备一套完整的处理器设计,而是可以多个线程共享除了执行器和寄存器以外的部分。再乘上核心数,同时运行的线程数量大大增加。
而且为了隐藏一些操作比如内存访问的延迟,还有一个线程组的池,里面可以准备执行到不同指令的几十组线程,在一组线程因为数据访问等依赖无法马上执行时,硬件调度器可以挂起这组线程执行另一组的线程。也算是利用线程数量的例子。
不过Bifrost架构里依然有很多ILP的设计,比如句式(Clause)指令(图二):将很多串行指令组成一个指令块——句子,句子是硬件调度器调度的最小单位。句子内部可以有一些加速操作,比如当一个加法指令输出是一个减法指令输入的时候,可以不通过寄存器文件直接传递数据。而且单个指令虽然减少了单元数量,但还是有三个计算单元。所以编译器还是需要考虑单指令单元填充以及多指令组成句子的问题。
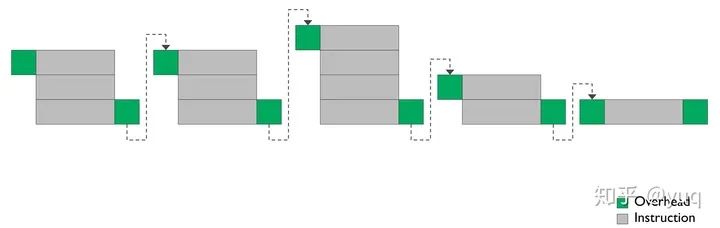
图二:Bifrost句式指令【4】
Valhall架构就更加依赖TLP来提升性能了,为此放弃了句式指令和多单元指令这些依赖软件的ILP特性,减小了调度粒度的同时也缩短了处理器管线。如图三所示,Valhall的处理器有三个计算单元,包括一个FMA(Fused-Multiply-Add),一个CVT(Convert)和一个SFU(Special Function Unit),线程组调度器可以在线程组池里找出三个当前指令使用不同计算单元的线程组,让他们在四个时钟周期内同时在三个计算单元内执行。而Bifrost虽然也有三个计算单元,但是他们属于一条长指令,而且ADD和Table排在FMA下游,是一个串行结构,这一条管线需要八个时钟周期。
对比来看Valhall再次加强了TLP,一个处理器最多可以同时运行三个线程组,而Bifrost最多只有一个。反过来看Valhall将三个Bifrost处理器压缩为一个,减少了控制逻辑,就可以有更多的空间增加处理器的数量,也是增加了TLP。

图三:Valhall和Bifrost处理器对比【5】
结语
在GPU架构历史上,统一Shader处理器和TLP驱动架构设计都是趋势。各家各代的GPU都或多或少经历了这个过程。我们纯从架构上看后期的GPU都比前期来的先进,但是放在当时的环境下,早期的图形应用Shader负载不是很复杂,而且移动邻域处理器对于面积和功耗方面的严格控制,都是他合理性的来源。
引用
Mali (GPU):https://zh.wikipedia.org/wiki/Mali_(GPU)
Lima driver status update:https://xdc2019.x.org/event/5/contributions/328/attachments/420/670/lima.pdf
ARM‘s Mali Midgard Architecture Explored:https://www.anandtech.com/show/8234/arms-mali-midgard-architecture-explored
ARM Unveils Next Generation Bifrost GPU Architecture & Mali-G71: The New High-End Mali:https://www.anandtech.com/show/10375/arm-unveils-bifrost-and-mali-g71
Arm’s New Mali-G77 & Valhall GPU Architecture: A Major Leap:https://www.anandtech.com/show/14385/arm-announces-malig77-gpu
Very long instruction word:https://en.wikipedia.org/wiki/Very_long_instruction_wordA4%E5%AD%97
Mali ISA:https://gitlab.freedesktop.org/panfrost/mali-isa-docs/-/tree/master
编辑:jq
-
ARM Mali GPU 深度解读2025-05-29 5333
-
Mali GPU支持tensorflow或者caffe等深度学习模型吗2022-09-16 3112
-
在RK3399开发板上运行Arm mali GPU驱动2022-07-27 8290
-
简单介绍下Arm Mali的GPU系列2022-04-12 11382
-
ARM发布全新架构CPU、GPU及AI内核 性能全面提升2019-05-29 7049
-
ARM的Cortex-A73 CPU和Mali-G71 GPU架构介绍并支持移动VR2017-09-18 1588
-
ARM推出Cortex-A73 CPU和Mali-G71 GPU架构以提升处理器的性能和功效并为移动VR提供支持2017-09-13 1225
-
Mali™-G51 GPU助主流手机实现卓越性能2016-11-16 5351
-
ARM Mali-G51 GPU发布 支持VR2016-10-31 3030
-
ARM发布三款Mali T-600系列GPU2012-08-07 3161
-
ARM发布Mali-T604 GPU 支持OpenCL 1.12012-08-04 1940
-
ARM推出ARM Mali-450 MP图形处理器(GPU)2012-06-20 9509
-
ARM最新Roadmap:GPU Mali-450性能提升两倍,Skrymir将重拳出击2012-06-15 5439
-
海思获得系列ARM Mali图形处理器(GPU)授权2012-05-31 2537
全部0条评论

快来发表一下你的评论吧 !
