

Linux三剑客之awk实战详解教程
描述
我们知道 Linux 三剑客,它们是 grep、sed、awk。在前边已经讲过 grep 和 sed,没看过的同学可以直接点击阅读,今天要分享的是更为强大的 awk。
sed 可以实现非交互式的字符串替换,grep 能够实现有效的过滤功能。与两者相比,awk 是一款强大的文本分析工具,在对数据分析并生成报告时,显得尤为强悍。
awk 强大的功能,是一般 Linux 命令无法比拟的。在本文中,我不会告诉你 awk 也是一种编程语言,免得会吓到你。我们只需把它当做 Linux 下一款强大的文本分析工具即可。
这篇文章,我仍然秉持着实用、实践原则,提供大量的示例,但不会面面俱到。通过本文可以帮助你,快速将 awk 运用起来,这些东西足够应付工作中大多数应用场景。
场景
学习具体使用前,先来看下 awk 能干些什么事情:
1. 能够将给定的文本内容,按照我们期望的格式输出显示,打印成报表。
2. 分析处理系统日志,快速地分析挖掘我们关心的数据,并生成统计信息;
3. 方便地用来统计数据,比如网站的访问量,访问的 IP 量等;
4. 通过各种工具的组合,快速地汇总分析系统的运行信息,让你对系统的运行了如指掌;
5. 强大的脚本语言表达能力,支持循环、条件、数组等语法,助你分析更加复杂的数据;
......
当然 awk 不仅能做这些事情,当你将它的用法融汇贯通时,可以随心所欲的按照你的意愿,来进行高效的数据分析和统计。
不过我们需要知道,awk 不是万能的,它比较擅长处理格式化的文本,比如 日志、csv 格式数据等;
原理
我们先来简单了解 awk 基本工作原理,通过下边的图文讲述,希望你能了解 awk 到底是如何工作的。
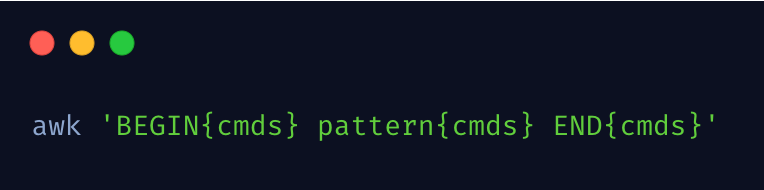
awk 基本命令格式
结合下图来详细说明 awk 工作原理
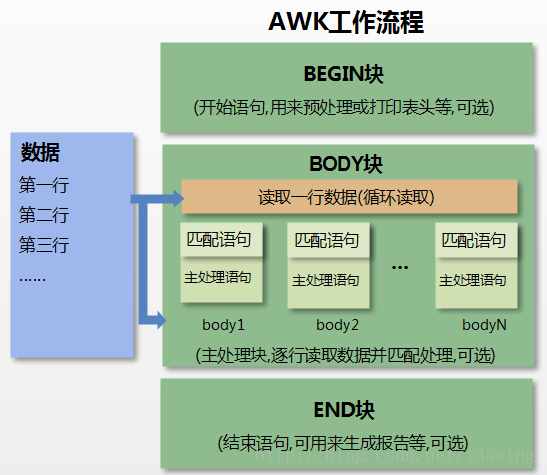
首先,执行关键字 BEGIN 标识的 {} 中的命令;
完成 BEGIN 大括号中命令的后,开始执行 body 命令;
逐行读取数据,默认读到 分割的内容为一条记录,其实就是行的概念;
将记录按照指定的分隔符划分为字段,其实就是列的概念;
循环执行 body 块中的命令,每读取一行,执行一次 body,最终完成 body 执行;
最后,执行 END 命令,通常会在 END 中输出最后的结果;
awk 是输入驱动的,有多少输入行,就会执行多少次 body 命令。
我们在下边的示例学习中,要时刻记着:记录(Record) 就是行,字段(Field) 就是列,BEGIN 是预处理阶段,body 是 awk 真正工作的阶段,END 是最后处理阶段。
实战 - 入门
从下边内容开始,我们直接进入到实战。为了方便举例,我先把如下信息保存到 file.txt
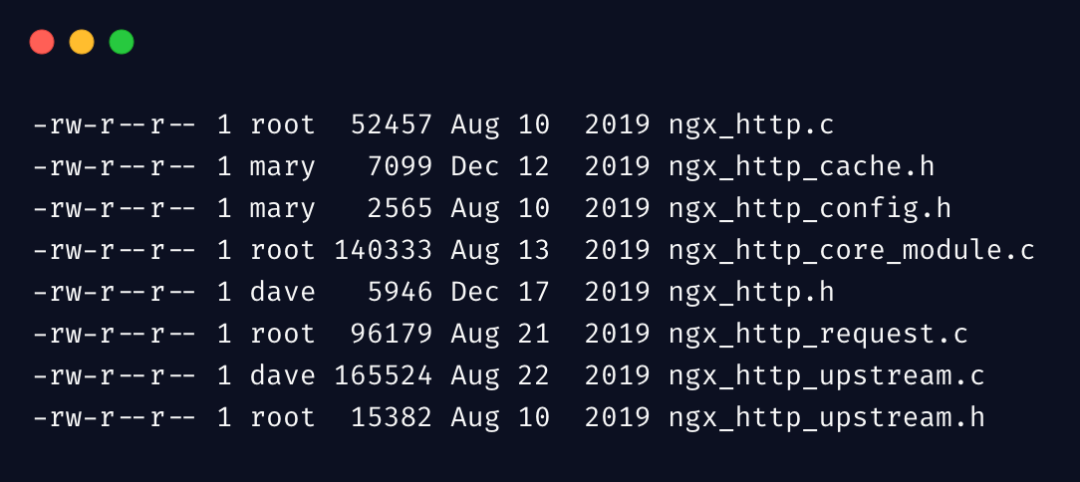
好了,我们先来一个最简单最常用的 awk 示例,输出第 1、4、8 列:
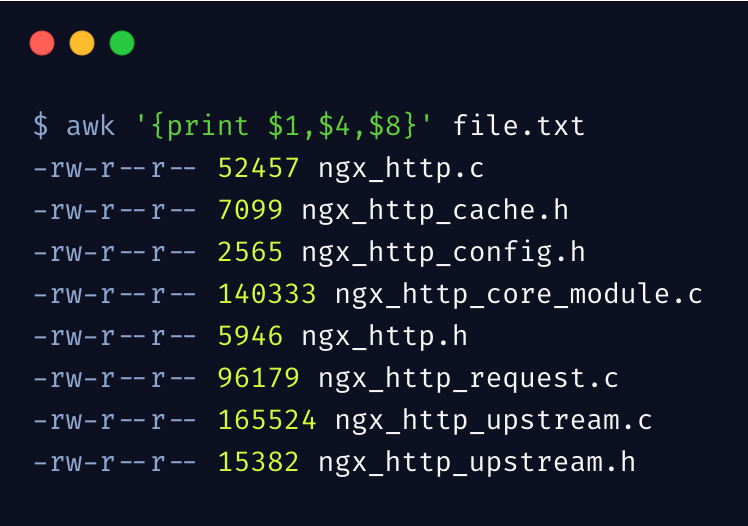
大括号里边的就是 awk 语句,只能被单引号包含,其中,$1..$N表示第几列,$0 表示整个行内容
再来看下 awk 比较实用的功能格式化输出。和 C 语言的 printf 格式输出是一毛一样,我个人特别喜欢这种格式化方式,而不是 C++ 中的流的方式。
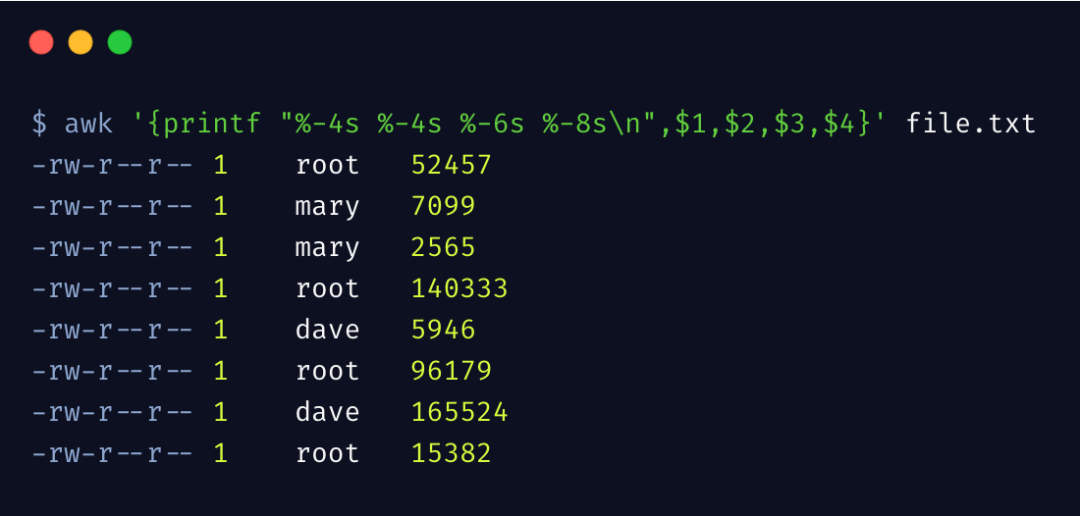
%s 表示字符串占位符,-4表示列宽度为 4,且左对齐,我们还可以根据需要,列出更复杂的格式来,这里先不详细举例了。
实战 - 进阶
(一)过滤记录
有些数据可能不是你想要的,可以根据需要进行过滤
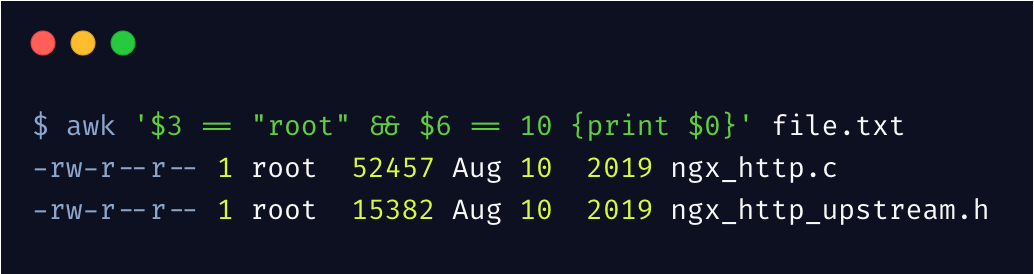
上边的过滤条件为,第 3 列为 root 且第 6 列为 10 的行,才会被输出。
awk 支持各种比较运算符号 !=、>、<、>=、<=,其中 $0 表示整行的所有内容。
(二)内置变量
awk 内置了一些变量,更方便我们对数据的处理
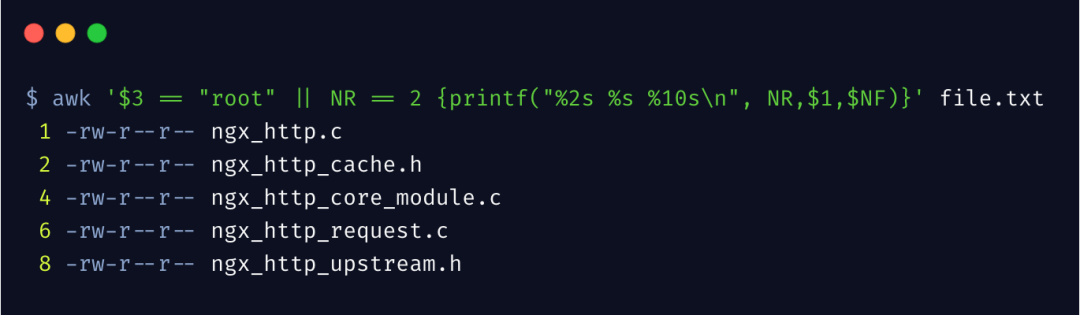
过滤第 3 列为 root 用户,以及第 2 行内容,且打印时输出行号。NR 表示当前第几行,NF表示当前行有几列。
(三)指定分隔符
我们的数据,不总是以空格为分隔符,我们可以通过 FS 变量指定分隔符。
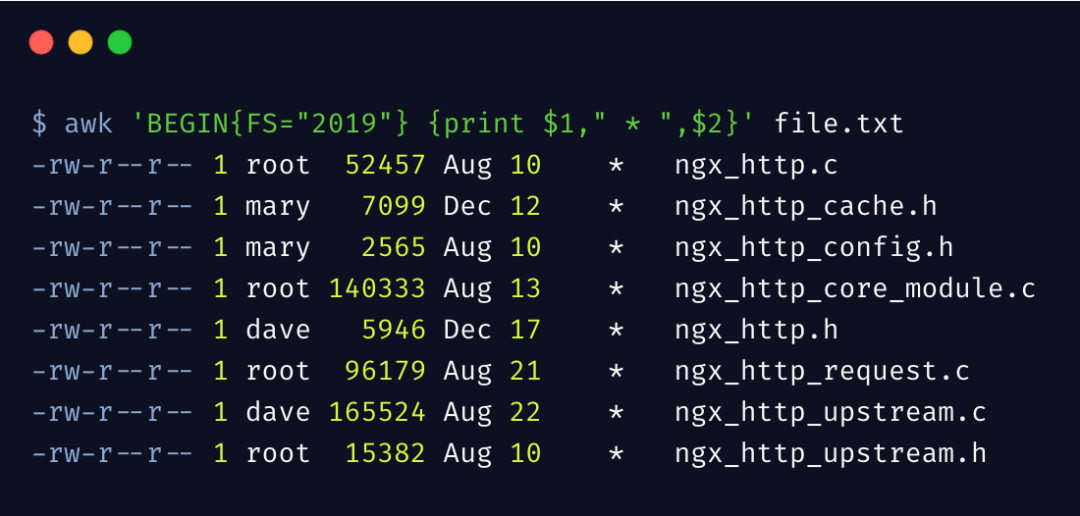
我们指定分隔符为 2019,这样就将行内容分割为了两部分,将 2019 替换成了 *
上边的命令也可以通过 -F 选项指定分割符
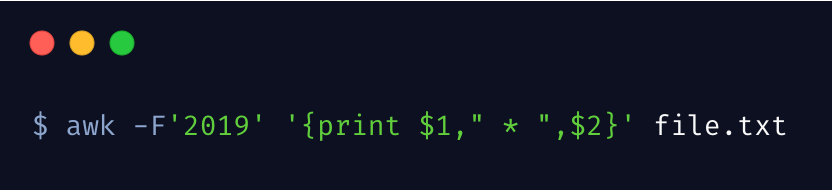
如果你需要指定多个分隔符,可以这样做 -F '[;:]'。相信聪明的你,一定能够理解并融会贯通的。
同样,awk 可以指定输出时的分隔符,通过 OFS 变量来设置
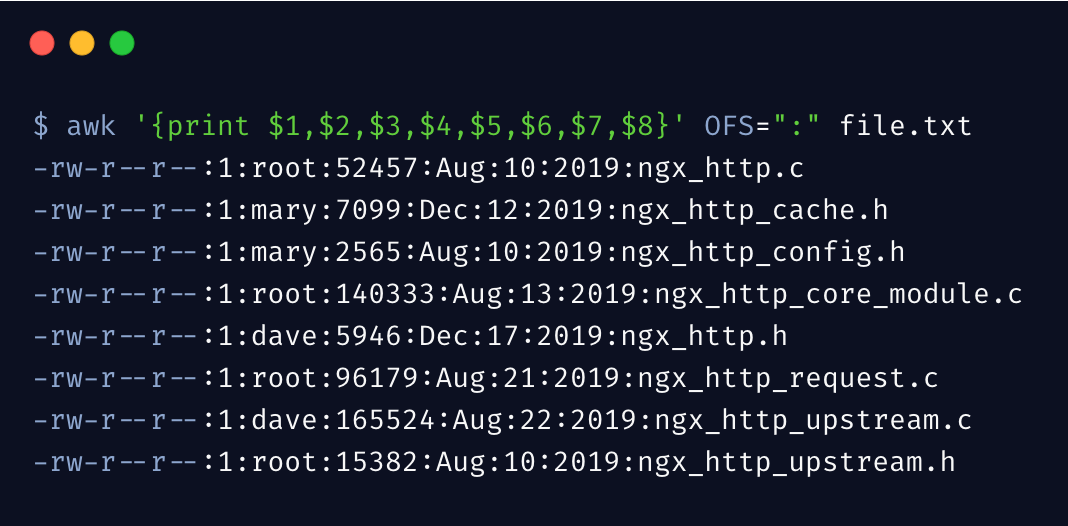
输出时,各字段用 OFS 指定的符号进行了分隔。
实战 - 高级
(一)条件匹配
列出 root 用户的所有文件,以及第一行文件
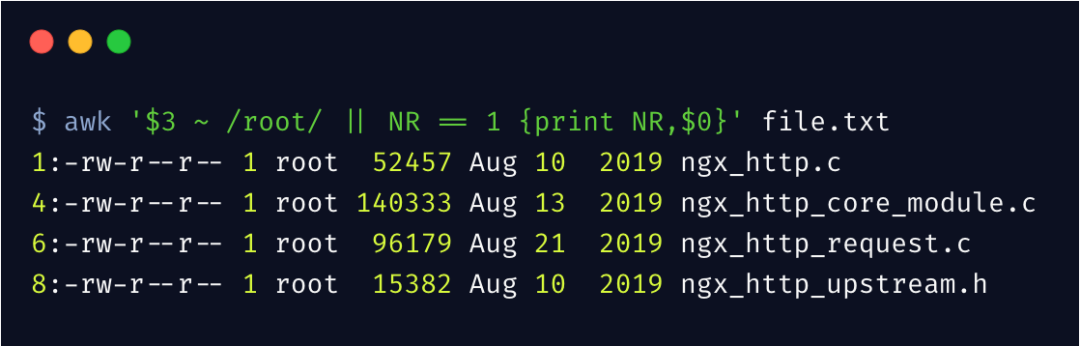
上边匹配第三列中包含 root 的行,~ 其实就是正则表达式的匹配。
同样,awk 可以像 grep 一样匹配某一行,就像这样
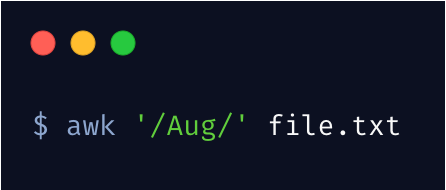
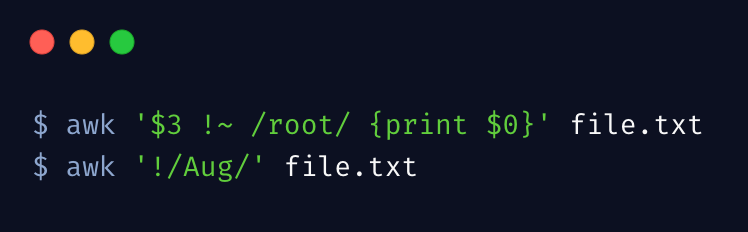
另外,可以这样 /Aug|Dec/ 匹配多个关键词。
模式取反可以使用 ! 符号
(二)拆分文件
我们来做一件有意思的事情,可以将文本信息拆分为多个文件,下边命令按照月份(第5列)将文件信息拆分为多个文件
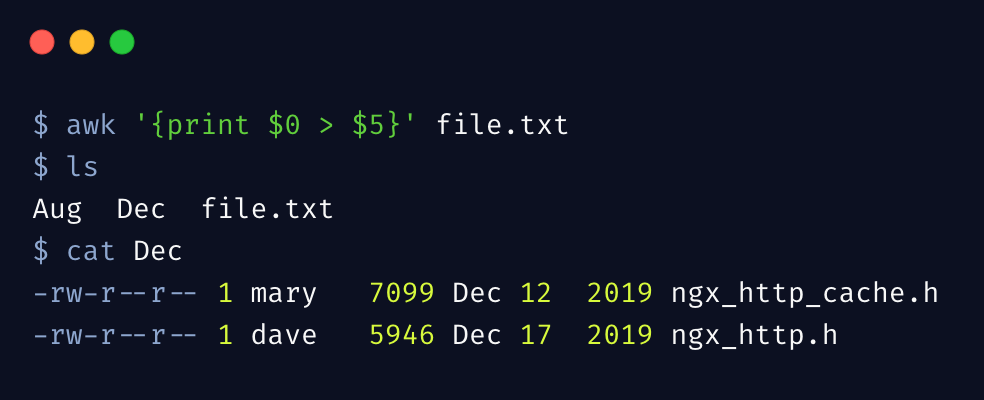
awk 支持重定向符号 >,直接将每行内容重定向到月份命名的文件了,当然你也可以把指定的列输出到文件
(三)if 语句
复杂的条件判断,可以使用 awk 的 if 语句,awk 的强大正因为它是个脚本解释器,拥有一般脚本语言的编程能力,下边示例通过稍微复杂的条件进行拆分文件
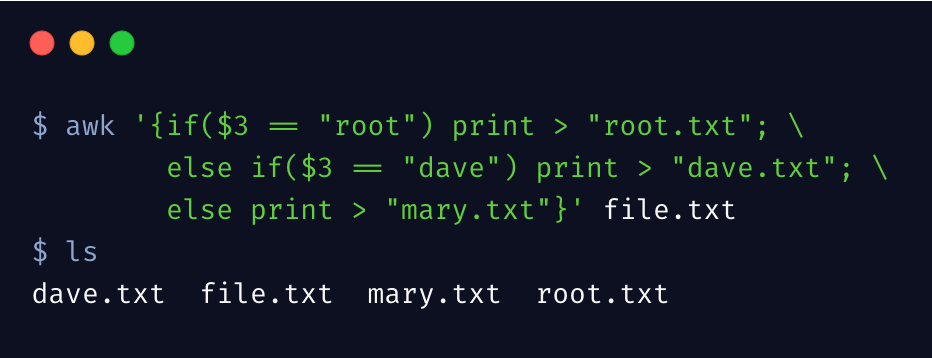
要注意,if 语句是在大括号里边的。
(四)统计
统计当前目录下,所有 *.c、*.h 文件所占用空间大小总和

第 5 列表示文件大小,每读取一行就会将该文件大小计算到 sum 变量中,在最后 END 阶段打印出 sum,也就是所有文件的大小总和。
再来看一个例子,统计每个用户的进程占用了多少内存,注意取值的是 RSS 那一列
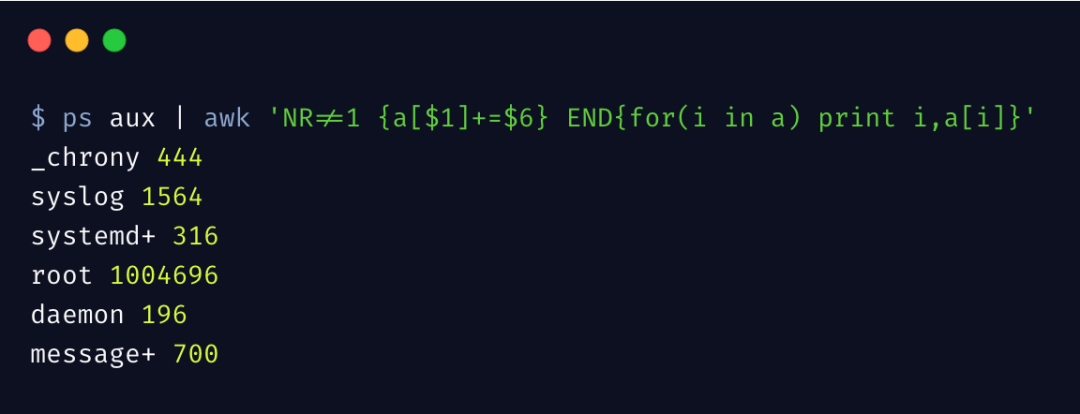
这里用到了 数组 和 for 循环,值得一提的是,awk 的数组可以理解为字典或 Map,key 可以是数值和字符串,这种数据类型在平时很常用。
(五)字符串
通过下边简单示例,展示 awk 对字符串操作的支持
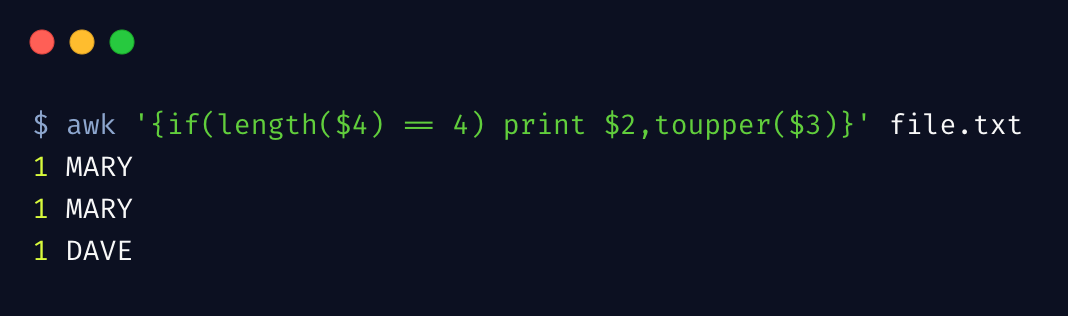
awk 内置支持一系列的字符串函数,length 计算字符串长度,toupper 函数转换字符串为大写。
实战 - 技巧
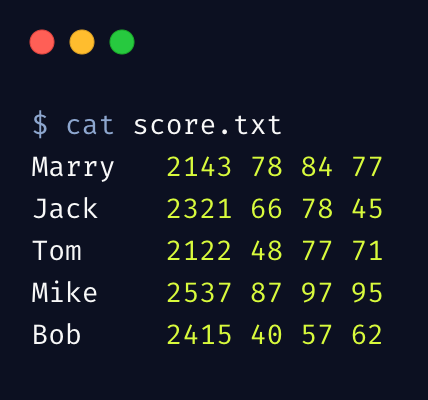
为了从整体上理解 awk 工作机制,我们再来看一个综合的示例,假设有一个学生成绩单:
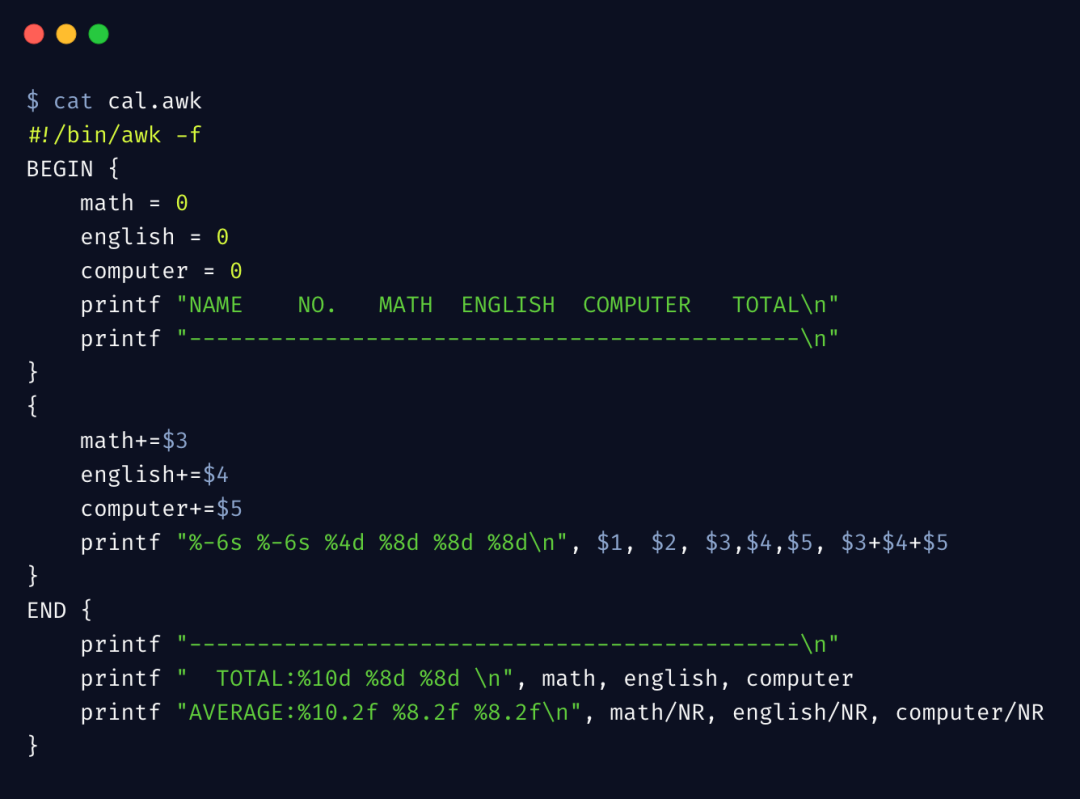
由于此示例程序稍显复杂,在命令行上不易读,另外呢,也想通过此案例介绍另外一种 awk 的执行方式,我们的 awk 脚本如下:
执行 awk 结果如下
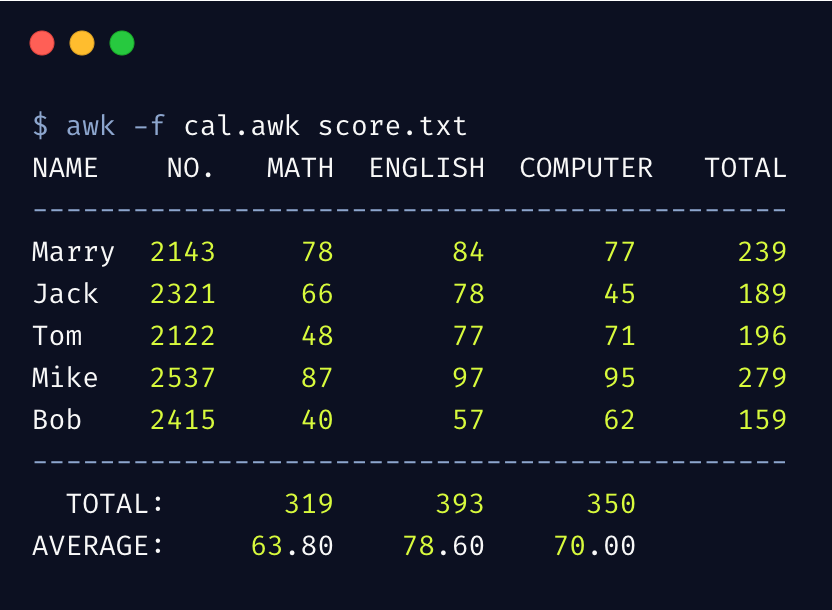
我们可以将复杂的 awk 语句写入脚本文件 cal.awk,然后通过 -f 选项指定从脚本文件执行。
在 BEGIN 阶段,我们初始化了相关变量,并打印了表头的格式
在 body 阶段,我们读取每一行数据,计算该学科和该同学的总成绩
在 END 阶段,我们先打印了表尾的格式,并打印总成绩,以及计算了平均值
这个简单示例,完整的体现了 awk 的工作机制和原理,希望通过此示例能够帮你真正理解 awk 是如何工作的。
总结归纳
通过上述的示例,我们学习到了 awk 的工作原理,下边我们来总结下几个概念和常用的知识点。
(一)内置变量
1. 每一行内容记录,叫做记录,英文名称 Record
2. 每行中通过分隔符隔开的每一列,叫做字段,英文名称 Field
明确这几个概念后,我们来总结几个重要的内置变量:
NR:表示当前的行数;
NF:表示当前的列数;
RS:行分隔符,默认是换行;
FS:列分隔符,默认是空格和制表符;
OFS:输出列分隔符,用于打印时分割字段,默认为空格
ORS:输出行分隔符,用于打印时分割记录,默认为换行符
(二)输出格式
awk 提供 printf 函数进行格式化输出功能,具体的使用方式和 C 语法基本一致。
基本用法
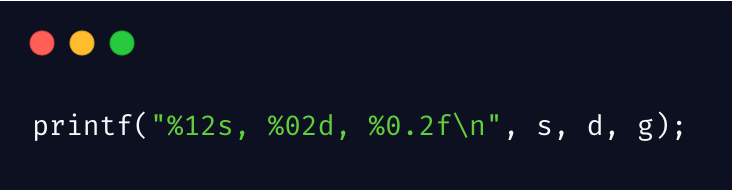
常用的格式化方式:
%d 十进制有符号整数
%u 十进制无符号整数
%f 浮点数
%s 字符串
%c 单个字符
%e 指数形式的浮点数
%x %X 无符号以十六进制表示的整数
%0 无符号以八进制表示的整数
%g 自动选择合适的表示法
换行符
Tab符
(三)编程语句
awk 不仅是一个 Linux 命令行工具,它其实是一门脚本语言,支持程序设计语言所有的控制结构,它支持:
条件语句
循环语句
数组
函数
(四)常用函数
awk 内置了大量的有用函数功能,也支持自定义函数,允许你编写自己的函数来扩展内置函数。
这里只简单罗列一些比较常用的字符串函数:
index(s, t) 返回子串 t 在 s 中的位置
length(s) 返回字符串 s 的长度
split(s, a, sep) 分割字符串,并将分割后的各字段存放在数组 a 中
substr(s, p, n) 根据参数,返回子串
tolower(s) 将字符串转换为小写
toupper(s) 将字符串转换为大写
这里只简单总结一些常用的字符串功能函数,具体使用方法,还需要你参照前边的示例程序,举一反三,运用到实际问题中。
责任编辑:lq
-
Linux中文本处理命令的用法2025-04-15 1016
-
Linux系统中最重要的三个命令2025-03-03 1333
-
Linux三剑客之Sed:文本处理神器2024-12-16 1807
-
Linux中grep、sed和awk命令详解2023-04-26 4017
-
关于linux的awk高效命令集锦2023-04-20 836
-
linux三剑客之awk高效命令集锦!2023-01-03 1239
-
嵌入式Linux系统知识架构2021-10-27 1812
-
【嵌入式】构建嵌入式Linux系统(uboot、内核、文件系统)2021-10-20 1473
-
关于Linux中的sed简易介绍与工作原理2021-03-26 3108
-
Redmi Note 9 Pro系列三剑客正式亮相2020-11-27 2714
-
小米也玩智慧城市?三剑客联手“不务正业”2018-11-15 5034
-
Linux Awk用法总结2018-04-13 6435
-
锂离子正极三剑客之一:钴酸锂2009-11-04 1818
-
3ds max7渲染传奇三剑客-VRay教程2009-09-07 467
全部0条评论

快来发表一下你的评论吧 !
