

如何高效的使用Python和pandas清理非结构化文本字段技巧
描述
介绍
大家都知道数据清洗是数据分析过程中的一个重要部分。pandas有多种清洗文本字段的方法,可以用来为进一步分析做准备。随着数据集越来越大,文本清洗的过程会逐渐变长,寻找一个能在合理时间内有效运行并可维护的方法变得非常重要。
本文将展示清洗大数据文件中文本字段的示例,帮助大家学习使用 Python 和 pandas 高效清理非结构化文本字段的技巧。
问题
假设你有一批全新工艺的威士忌想出售。你所在的爱荷华州,刚好有一个公开的数据集显示了该州所有的酒类销售情况。这似乎是一个很好的机会,你可以利用你的分析技能,看看谁是这个州最大的客户。有了这些数据,你甚至可以为每个客户规划销售流程。
你对这个机会感到兴奋,但下载了数据后发现它相当大。这个数据集是一个565MB的CSV文件,包含24列和2.3百万行。它虽然不是我们平时说的“大数据”,但它依然足够大到可以让Excel卡死。同时它也大到让一些pandas方法在比较慢的笔记本电脑上运行地非常吃力。
本文中,我们将使用包括2019年所有销售额的数据。当然你也可以从网站上下载其他不同时间段的数据。
我们从导入模块和读取数据开始,我会使用sidetable包来查看数据的概览。这个包虽然不能用来做清洗,但我想强调一下它对于这些数据探索场景其实很有用。
数据
读取数据:
import pandas as pd
import numpy as np
import sidetable
df = pd.read_csv(‘2019_Iowa_Liquor_Sales.csv’)
数据长这样:
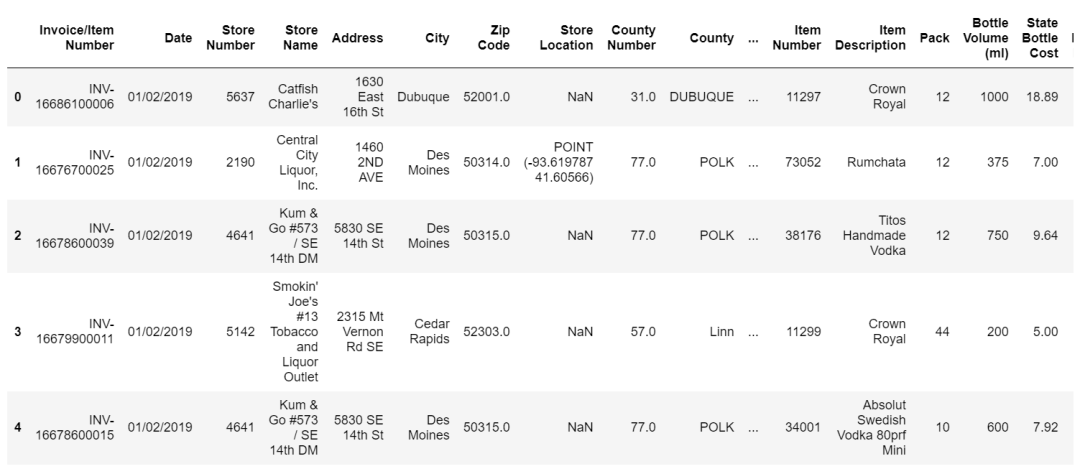
我们大概率要做的第一件事是看每一家商店的购买量,并将它们从大到小排序。资源有限所以我们应该集中精力在那些我们能从中获得最好回报的地方。我们更应该打电话给几个大公司的账户,而不是那些夫妻小店。
sidetable是以可读格式汇总数据的快捷方式。另一种方法是groupby加上其他操作。
df.stb.freq([‘Store Name’], value=‘Sale (Dollars)’, style=True, cum_cols=False)
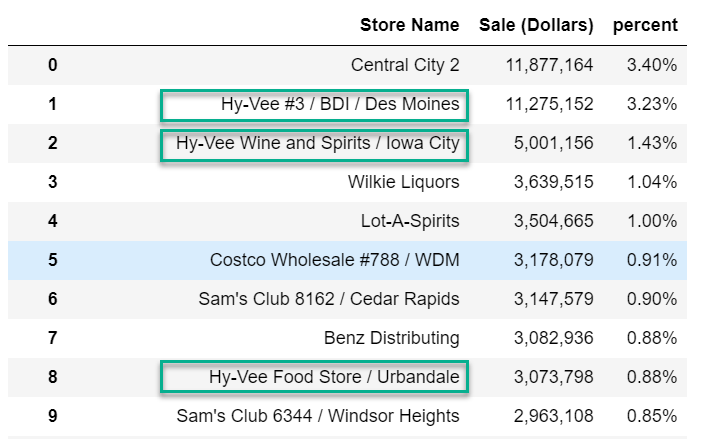
很明显在大多数情况下,每个位置的商店名称都是唯一的。理想情况下我们希望看到的是Hy-Vee, Costco, Sam’s 等聚合在一起的内容。
看来我们需要清洗数据了。
清洗尝试·1
我们可以研究的第一种方法是使用.loc以及str的布尔过滤器来搜索Store Name列中的相关字符串。
df.loc[df[‘Store Name’].str.contains(‘Hy-Vee’, case=False), ‘Store_Group_1’] = ‘Hy-Vee’
上述代码使用不区分大小写的方式来搜索字符串“Hy Vee”,并将值“Hy Vee”存储在名为Store_Group_1的新列中。这个代码可以有效地将“Hy Vee#3/BDI/Des Moines”或“Hy Vee Food Store/Urbandale”等名称转换为正常的“Hy Vee”。
用%%timeit来计算此操作的时间:
1.43 s ± 31.8 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
我们不想过早地进行优化,但我们可以使用regex=False参数来稍微加速一下:
df.loc[df[‘Store Name’].str.contains(‘Hy-Vee’, case=False, regex=False), ‘Store_Group_1’] = ‘Hy-Vee’
804 ms ± 27.9 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
来看下新列的情况:
df[‘Store_Group_1’].value_counts(dropna=False)
NaN 1617777
Hy-Vee 762568
Name: Store_Group_1, dtype: int64
可以看到我们已经清理了Hy-Vee,但还有很多其他值需要我们处理。
.loc方法内部包含大量代码,速度其实可能很慢。我们可以利用这个思想,来寻找一些更易于执行和维护的替代方案。
清洗尝试·2
另一种非常有效和灵活的方法是使用np.select来进行多匹配并在匹配时指定值。
有几个很好的资源可以帮你学习如何使用np.select。这篇来自Dataquest的文章就是一个很好的概述。Nathan Cheever的这篇演讲也十分有趣,内容丰富。我建议你们可以看下这两篇文章。
关于np.select的作用最简单的解释是,它计算一个条件列表,如果有条件为真,就应用相应值的列表。
在我们的例子中,我们想查找不同的字符串,来替换为我们想要的规范值。
浏览完我们的数据后,我们把条件和值列表总结在store_patterns列表中。列表中的每个元组都是一个str.contains()方法,来查找和替换对应的我们想要做聚合的规范值。
store_patterns = [
(df[‘Store Name’].str.contains(‘Hy-Vee’, case=False, regex=False), ‘Hy-Vee’),
(df[‘Store Name’].str.contains(‘Central City’,
case=False, regex=False), ‘Central City’),
(df[‘Store Name’].str.contains(“Smokin‘ Joe’s”,
case=False, regex=False), “Smokin‘ Joe’s”),
(df[‘Store Name’].str.contains(‘Walmart|Wal-Mart’,
case=False), ‘Wal-Mart’),
(df[‘Store Name’].str.contains(‘Fareway Stores’,
case=False, regex=False), ‘Fareway Stores’),
(df[‘Store Name’].str.contains(“Casey‘s”,
case=False, regex=False), “Casey’s General Store”),
(df[‘Store Name’].str.contains(“Sam‘s Club”, case=False, regex=False), “Sam’s Club”),
(df[‘Store Name’].str.contains(‘Kum & Go’, regex=False, case=False), ‘Kum & Go’),
(df[‘Store Name’].str.contains(‘CVS’, regex=False, case=False), ‘CVS Pharmacy’),
(df[‘Store Name’].str.contains(‘Walgreens’, regex=False, case=False), ‘Walgreens’),
(df[‘Store Name’].str.contains(‘Yesway’, regex=False, case=False), ‘Yesway Store’),
(df[‘Store Name’].str.contains(‘Target Store’, regex=False, case=False), ‘Target’),
(df[‘Store Name’].str.contains(‘Quik Trip’, regex=False, case=False), ‘Quik Trip’),
(df[‘Store Name’].str.contains(‘Circle K’, regex=False, case=False), ‘Circle K’),
(df[‘Store Name’].str.contains(‘Hometown Foods’, regex=False,
case=False), ‘Hometown Foods’),
(df[‘Store Name’].str.contains(“Bucky‘s”, case=False, regex=False), “Bucky’s Express”),
(df[‘Store Name’].str.contains(‘Kwik’, case=False, regex=False), ‘Kwik Shop’)
]
使用np.select很容易遇到条件和值不匹配的情况。所以我们将其合并为元组,以便更容易地跟踪数据匹配。
想使用这种数据结构,我们需要将元组分成两个单独的列表。使用zip来把store_patterns分为store_criteria和store_values:
store_criteria, store_values = zip(*store_patterns)
df[‘Store_Group_1’] = np.select(store_criteria, store_values, ‘other’)
上述代码将用文本值填充每个匹配项。如果没有匹配项,我们给它赋值‘other’。
数据现在长这样:
df.stb.freq([‘Store_Group_1’], value=‘Sale (Dollars)’, style=True, cum_cols=False)
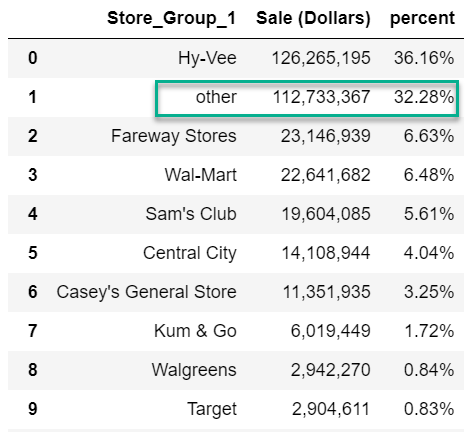
看起来比之前好,但仍然有32.28%的‘other’。
思考下这样做是不是更好:如果帐户不匹配,我们使用Store Name字段,而不是‘other’。这样来实现:
df[‘Store_Group_1’] = np.select(store_criteria, store_values, None)
df[‘Store_Group_1’] = df[‘Store_Group_1’].combine_first(df[‘Store Name’])
这里使用了combine_first方法来将Store Name填充None值,这是清理数据时要记住的一个简便技巧。
再来看下数据:
df.stb.freq([‘Store_Group_1’], value=‘Sale (Dollars)’, style=True, cum_cols=False)
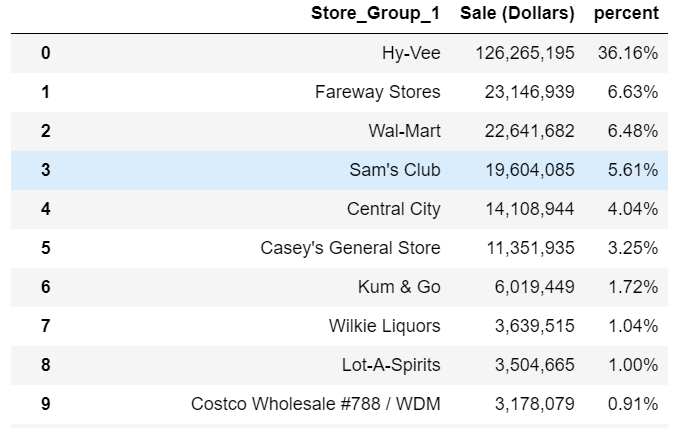
这样看起来更好了,我们可以根据需要继续细化分组。例如我们可能需要为Costco构建一个字符串查找。
对于这个大型数据集来说,性能也还不错:
13.2 s ± 328 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
这个方法的好处是你可以使用np.select来做数值分析或者上面展示的文本示例,非常灵活。这个方法也有一个弊端,那就是代码量很大。如果你要清理的数据集非常大,那么用这个方法可能导致很多数据和代码混合在一起。那么有没有其他方法可以有差不多的性能,代码更整洁一些?
清洗尝试·3
这里要介绍的解决方案基于Matt Harrison的优秀代码示例,他开发了一个可以做匹配和清洗的generalize函数。我做了一些修改,让这个方法可以在这个示例中使用,我想给Matt一个大大的赞。如果没有他前期99%的工作,我永远不会想到这个解决方案!
def generalize(ser, match_name, default=None, regex=False, case=False):
“”“ Search a series for text matches.
Based on code from https://www.metasnake.com/blog/pydata-assign.html
ser: pandas series to search
match_name: tuple containing text to search for and text to use for normalization
default: If no match, use this to provide a default value, otherwise use the original text
regex: Boolean to indicate if match_name contains a regular expression
case: Case sensitive search
Returns a pandas series with the matched value
”“”
seen = None
for match, name in match_name:
mask = ser.str.contains(match, case=case, regex=regex)
if seen is None:
seen = mask
else:
seen |= mask
ser = ser.where(~mask, name)
if default:
ser = ser.where(seen, default)
else:
ser = ser.where(seen, ser.values)
return ser
这个函数可以在pandas上调用,传参是一个元组列表。第一个元组项是要搜索的值,第二个是要为匹配值填充的值。
以下是等效的模式列表:
store_patterns_2 = [(‘Hy-Vee’, ‘Hy-Vee’), (“Smokin‘ Joe’s”, “Smokin‘ Joe’s”),
(‘Central City’, ‘Central City’),
(‘Costco Wholesale’, ‘Costco Wholesale’),
(‘Walmart’, ‘Walmart’), (‘Wal-Mart’, ‘Walmart’),
(‘Fareway Stores’, ‘Fareway Stores’),
(“Casey‘s”, “Casey’s General Store”),
(“Sam‘s Club”, “Sam’s Club”), (‘Kum & Go’, ‘Kum & Go’),
(‘CVS’, ‘CVS Pharmacy’), (‘Walgreens’, ‘Walgreens’),
(‘Yesway’, ‘Yesway Store’), (‘Target Store’, ‘Target’),
(‘Quik Trip’, ‘Quik Trip’), (‘Circle K’, ‘Circle K’),
(‘Hometown Foods’, ‘Hometown Foods’),
(“Bucky‘s”, “Bucky’s Express”), (‘Kwik’, ‘Kwik Shop’)]
这个方案的一个好处是,与前面的store_patterns示例相比,维护这个列表要容易得多。
我对generalize函数做的另一个更改是,如果没有提供默认值,那么将保留原始值,而不是像上面那样使用combine_first函数。最后,为了提高性能,我默认关闭了正则匹配。
现在数据都设置好了,调用它很简单:
df[‘Store_Group_2’] = generalize(df[‘Store Name’], store_patterns_2)
性能如何?
15.5 s ± 409 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
比起上面它稍微有一点慢,但我认为它是一个更优雅的解决方案,如果我要做一个类似的文本清理工作,我会用这个方法。
这种方法的缺点是,它只能做字符串清洗。而np.select也可以应用于数值,所以应用范围更广。
关于数据类型
在pandas的最新版本中,有一个专用的字符串类型。我尝试将Store Name转换为该字符串类型,想看是否有性能优化。结果没有看到任何变化。不过,未来有可能会有速度的提升,这点大家可以关注一下。
虽然string类型没有什么区别,但是category类型在这个数据集上显示了很大的潜力。有关category数据类型的详细信息,可以参阅我的上一篇文章:https://pbpython.com/pandas_dtypes_cat.html。
我们可以使用astype将数据转换为category类型:
df[‘Store Name’] = df[‘Store Name’].astype(‘category’)
然后我们跟之前那样在运行np.select的方法
df[‘Store_Group_3’] = np.select(store_criteria, store_values, None)
df[‘Store_Group_3’] = df[‘Store_Group_1’].combine_first(df[‘Store Name’])
786 ms ± 108 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
我们只做了一个简单的改动,运行时间从13秒到不到1秒。太神了!效果这么明显的原因其实很简单。当pandas将列转换为分组类型时,它只会对每个唯一的文本值调用珍贵的str.contains()函数。因为这个数据集有很多重复的数据,所以我们得到了巨大的性能提升。
让我们看看这是否适用于我们的generalize函数:
df[‘Store_Group_4’] = generalize(df[‘Store Name’], store_patterns_2)
不幸的是报错了:
ValueError: Cannot setitem on a Categorical with a new category, set the categories first
这个错误让我回忆起我过去处理分组数据时遇到的一些挑战。当你合并和关联分组数据时,你很容易遇到这些错误。
我试图找到一个比较好的方法来修改generage(),想让它起作用,但目前还没找到。如果有任何读者能找到方法,可以联系我获得奖金。这里,我们通过构建一个查找表来复制Category方法。
查找表
正如我们通过分类方法了解到的,这个数据集有很多重复的数据。我们可以构建一个查找表,每个字符串处理一次资源密集型函数。
为了说明它是如何在字符串上工作的,我们将值从category转换回字符串类型:
df[‘Store Name’] = df[‘Store Name’].astype(‘string’)
首先,我们构建一个包含所有唯一值的lookup DataFrame并运行generalize函数:
lookup_df = pd.DataFrame()
lookup_df[‘Store Name’] = df[‘Store Name’].unique()
lookup_df[‘Store_Group_5’] = generalize(lookup_df[‘Store Name’], store_patterns_2)
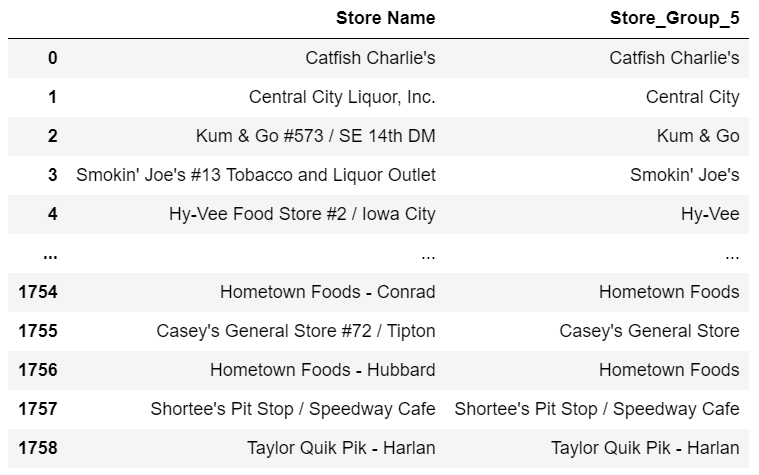
我们可以把它合并到最终的DataFrame:
df = pd.merge(df, lookup_df, how=‘left’)
1.38 s ± 15.1 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
比起np.select使用分组数据的方法稍慢一些,但是代码可读性和易维护程度更高,性能和这两者之间其实需要掌握一个平衡。
此外,中间的lookup_df可以很好的输出给分析师共享,从而让分析师帮助你清洗更多数据。这可能节省你几小时的时间!
总结
根据我的经验,通过本文中概述的清洗示例,你可以了解很多关于底层数据的信息。
我推测你会在你的日常分析中发现很多需要进行文本清理的案例,就像我在本文中展示的那样。
下面是本文解决方案的简要总结:
解决方案执行时间注释
np.select13s可用于非文本分析
generalize15s只支持文本
分组数据和np.select786ms在合并和关联时,分组数据可能会变得棘手
查找表和generalize1.3s查找表可以由其他人维护
对于一些数据集来说,性能不是问题,所以你可以随意选择。
然而,随着数据规模的增长(想象一下对50个州的数据进行分析),你需要了解如何高效地使用pandas进行文本清洗。我建议你可以收藏这篇文章,当你面对类似的问题时可以再回来看看。
当然,如果你有一些其他的建议,可能会对别人有用,可以写在评论里。如果你知道如何使我的generalize函数与分组数据一起工作,也记得告诉我。
编辑:lyn
-
如何在文本字段中使用上标、下标及变量2024-11-12 1462
-
CFD 设计利器:结构化和非结构化网格的组合使用2023-12-23 4731
-
Python Pandas如何来管理结构化数据2023-05-25 1467
-
MELSEC iQ R结构化文本(ST)编程指南2022-08-26 891
-
结构化文本(ST)编程参考手册2022-08-25 1609
-
结构化设计分为哪几部分?结构化设计的要求有哪些2021-12-23 2049
-
如何在Pixie中收集大量非结构化数据2021-08-10 3844
-
Codesys之结构化文本概述 相关资料分享2021-07-02 2168
-
结构化文本语言ST编程的学习课件2020-12-28 2599
-
如何使用西门子结构化文本编程2019-08-04 11824
-
并非所有字符都显示在文本字段或标签中2019-02-12 1196
-
MaxCompute(ODPS)上处理非结构化数据的Best Practice2018-05-15 3040
-
三菱Q系列PLC编程手册(结构化文本篇)2018-03-07 4909
全部0条评论

快来发表一下你的评论吧 !
